分布式数据库:适用场景与挑战分析
182 浏览量
更新于2024-08-27
收藏 185KB PDF 举报
分布式数据库集群是一种在大型互联网企业中广泛应用的架构,它起源于谷歌提出的分布式概念,其核心思想是将数据分散在多个独立的服务器节点上,以提高系统的可用性和可扩展性。然而,并非所有业务场景都适合采用分布式架构,选择分布式架构需要根据实际需求和数据特性来决定。
在适合分布式架构的场景中,如网易考拉和网易云音乐这样的大数据密集型应用,处理像歌单库(包含数十亿条记录)和评论库等高并发、大数据量的场景,分布式架构能够有效应对。例如,对于那些有时间维度的数据,如快递行业和微信红包,即使存储3个月的在线数据量相对较小,分布式架构也能提供更好的资源管理和负载均衡。
然而,分布式架构并非无条件的优点。首先,虽然分布式能提高可用性,但在实际操作中,如MySQL等关系型数据库扩展性受限于数据迁移和分片策略。将原本的4个节点扩展到8个节点时,原有的数据需要重新分布,可能导致性能瓶颈和数据管理复杂。相比之下,非关系型数据库如MongoDB、Redis和TiDB通过更优化的分片策略展现较好的可扩展性,但它们牺牲了一些SQL支持和复杂的事务处理能力。
其次,分布式数据库引入了中间件依赖和运维复杂度的增加。业界虽然有如MyCat这样的中间件可用,但它们并不总是生产环境的理想选择,特别是对于SQL复杂操作的支持有限。在某些情况下,过度依赖中间件可能导致性能下降,尤其是当SQL查询复杂度较高时。
最后,shard(分片)是分布式数据库中的一种关键概念,它是水平分割数据的一种方式,将数据分布在多个物理服务器上,以实现负载均衡。shard与分区相似,但关键区别在于数据可能分布到不同的服务器实例上,增加了系统复杂性和管理难度。
分布式数据库集群的优势在于处理大规模数据和高并发,同时具有较高的可用性和潜在的可扩展性,但其挑战包括依赖性增强、SQL支持限制以及运维复杂性。企业在考虑分布式架构时,必须权衡这些因素,确保其适用于自身的特定业务场景。
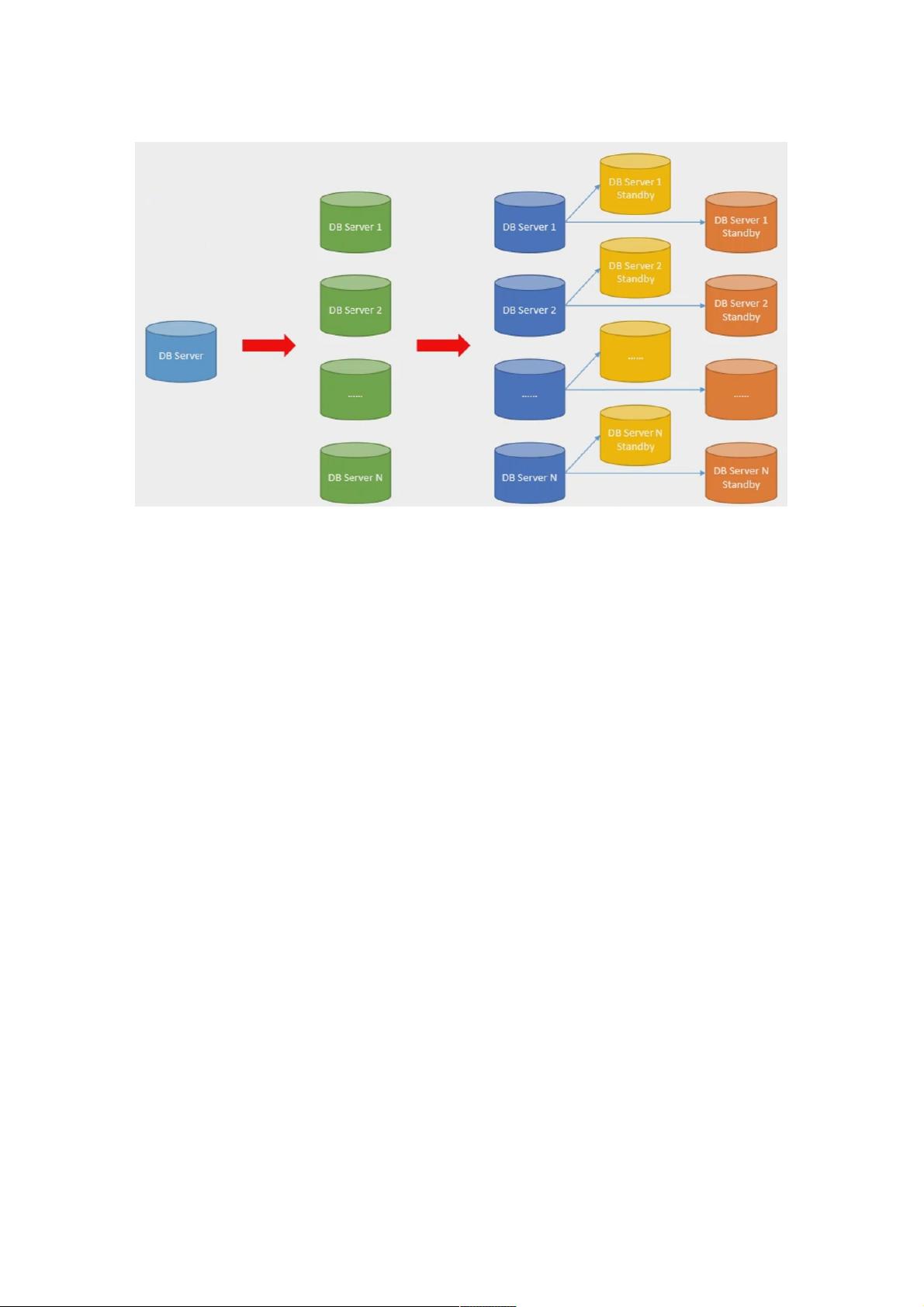
分布式数据库集群介绍分布式数据库集群介绍
自从谷歌提出分布式这个概念,这个玩意太火了,但是并不是所有的业务场景都适合用分布式的
什么场景适合用分布式架构?
网易分布式用的最好的两个项目:网易考拉 && 网易云音乐(歌单库单表百亿以上记录、评论库)
快递行业
微信红包
其他业务都是有时间维度的,可能只需要存3个月的在线数据,算下来也就2kw,那为什么还要做分布式架构呢?
所以不要迷信分布式架构和分库分表
tips:
单台服务器几千qps没必要分,两三万的话可以分
Ⅰ、分布式数据库特点
优点
可用性提高
可扩展性提升(扯淡,MySQL现在4个节点扩8个节点怎么办?数据库不是redis,redis里面内存数据可以丢掉,甚至redis单线程的
做这些都好弄,MySQL并不是,8扩12的话,原来的数据都要打散一遍,原来8个机器,hash8个,现在变12个,数据全部打散,如果
8*500G,4T数据打散到12个节点,怎么打散,这么多表),MySQL可扩展性的提升是很难达到的,我们借助另外一些手段来做扩展
性,为什么mongodb,redis,tidb扩展性是好的,因为他们的分片策略更好(也有缺点),是未来比较好的模式,但是在关系型数据库中
很难实现,对MySQL内核和中间件的改造太大了 某些情况下吞吐率提升显著 ---大大的问号,只有某些场景才会显著提升, 原来
一台机器,拆成八台机器,那就性能提升八倍?这是不存在的
缺点
依赖中间件(不依赖中间件就要在业务层做),业界基本上找不到一个好的中间件,mycat可以用,但是生产上不建议 SQL语句支持
不足(中间件支持的sql非常有限,多表join,子查询,派生表这些估计玩不转,mongodb,redis,tidb不做这些)
运维复杂度提高
某些情况下性能下降巨大
Ⅱ、分布式数据库——shard
2.1 shard相关概念
下载后可阅读完整内容,剩余3页未读,立即下载
2021-08-08 上传
2021-08-09 上传
2021-05-27 上传
2010-03-18 上传
2010-04-17 上传
2022-11-13 上传
点击了解资源详情
点击了解资源详情

weixin_38696836
- 粉丝: 3
- 资源: 932
 我的内容管理
展开
我的内容管理
展开







最新资源
- Fisher Iris Setosa数据的主成分分析及可视化- Matlab实现
- 深入理解JavaScript类与面向对象编程
- Argspect-0.0.1版本Python包发布与使用说明
- OpenNetAdmin v09.07.15 PHP项目源码下载
- 掌握Node.js: 构建高性能Web服务器与应用程序
- Matlab矢量绘图工具:polarG函数使用详解
- 实现Vue.js中PDF文件的签名显示功能
- 开源项目PSPSolver:资源约束调度问题求解器库
- 探索vwru系统:大众的虚拟现实招聘平台
- 深入理解cJSON:案例与源文件解析
- 多边形扩展算法在MATLAB中的应用与实现
- 用React类组件创建迷你待办事项列表指南
- Python库setuptools-58.5.3助力高效开发
- fmfiles工具:在MATLAB中查找丢失文件并列出错误
- 老枪二级域名系统PHP源码简易版发布
- 探索DOSGUI开源库:C/C++图形界面开发新篇章
