Apache Hadoop下的Solr:企业级全文搜索解决方案
需积分: 0 27 浏览量
更新于2024-09-02
收藏 597KB DOCX 举报
Apache Hadoop-Solr是一个强大的分布式数据检索引擎,它建立在Java基础之上,特别强调全文搜索功能。作为Lucene的扩展,Solr不仅保留了Lucene的核心搜索能力,如支持复杂的查询语法、短语、通配符和分组,而且还提供了更丰富的查询语言,以及高效的实时索引和查询性能。其显著特点包括:
1. **企业级服务**:Solr作为一个独立的服务,通过HTTP RESTful API对外提供服务,允许用户通过HTTP POST或GET请求上传文档并进行搜索,支持多种数据格式返回结果。
2. **近实时索引**:文档提交后,索引更新即时可见,提高了搜索响应速度。
3. **全面管理界面**:内置的管理界面简化了对Solr实例的配置和监控,便于用户进行日常维护。
4. **灵活配置与扩展**:通过简单的配置调整,Solr具备高度的灵活性和适应性,允许用户根据需求定制。
5. **高可用性和容错**:Solr利用Zookeeper实现分布式部署、备份和负载均衡,增强了系统的扩展性和容错性。
6. **插件架构**:Solr具有开放的插件体系结构,方便开发者根据业务需求添加新功能和定制化处理。
在系统架构方面,Solr的运行主要围绕SolrHome和SolrCore展开。SolrHome是Solr的主要工作目录,包含多个独立运行的SolrCore,每个SolrCore都是一个完整的搜索和索引服务单元,有自己的配置和索引文件。
搜索服务的实现分为两个关键步骤:索引创建和搜索索引。索引创建涉及分词、语言处理和索引组件,它们负责将原始数据转化为可检索的形式,包括词汇拆分、标准化处理和重复词的合并。搜索过程则依赖于这些预处理后的索引,执行快速准确的查询。
Apache Hadoop-Solr凭借其高性能、易用性和可扩展性,成为大数据场景中不可或缺的全文搜索引擎解决方案,广泛应用于内容管理和分析领域。
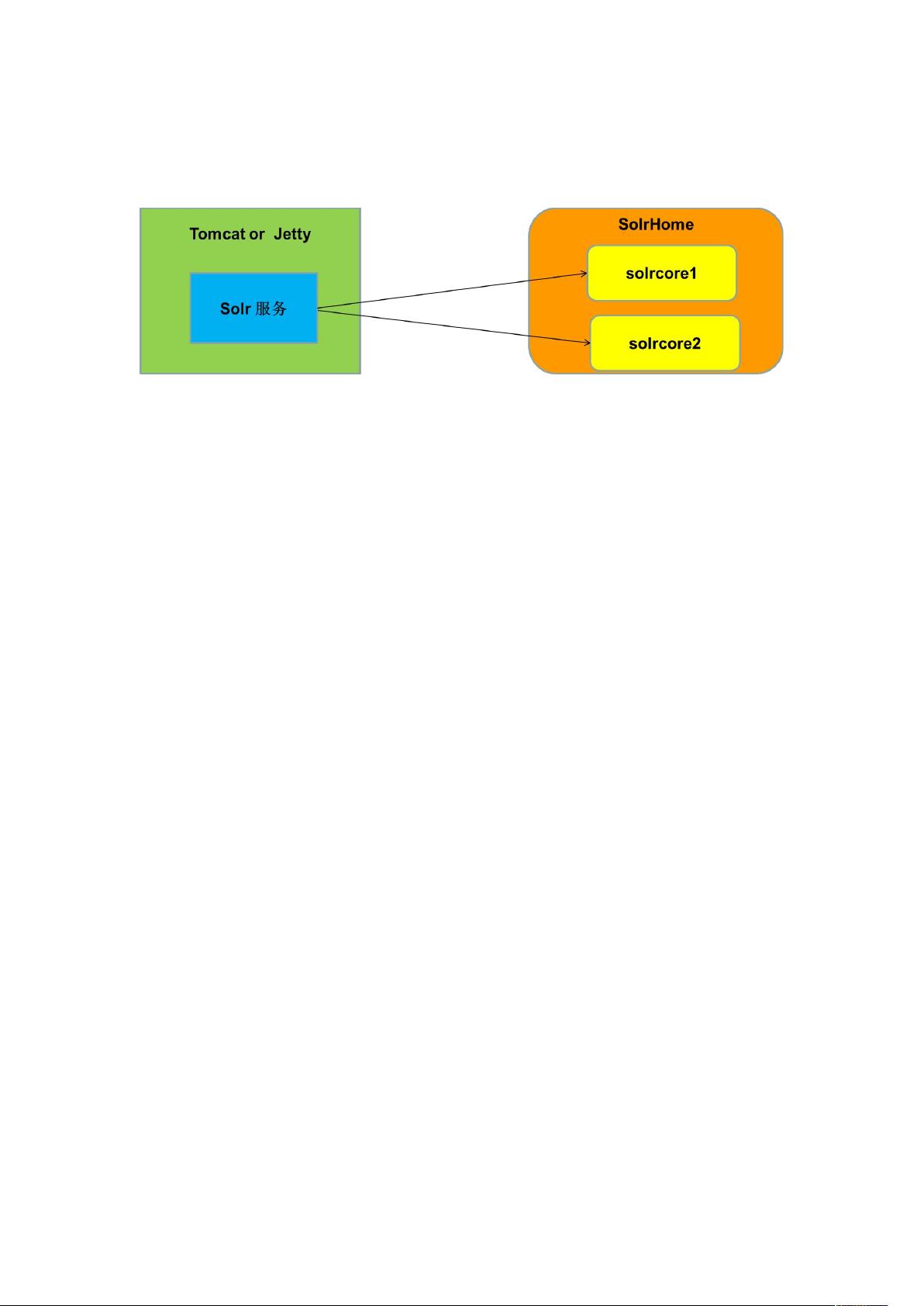
2、系统架构
SolrHome:SolrHome 是 Solr 运行的主目录,该目录可以包含多个
solrcore 目录。
SolrCore:每个 solrcore 相互独立,可以单独对外提供搜索和索引服务;
Solr 实例就是一个 solrcore 目录,包含运行 solr 实例的所有配置文件和索
引文件。
剩余13页未读,继续阅读
2020-06-12 上传
2020-06-11 上传
2020-06-11 上传
2017-04-18 上传
2021-12-23 上传
2022-11-25 上传
2024-05-23 上传
2022-11-26 上传
2022-07-13 上传

砸锅卖铁上论坛
- 粉丝: 4
- 资源: 39
 我的内容管理
展开
我的内容管理
展开







最新资源
- Fisher Iris Setosa数据的主成分分析及可视化- Matlab实现
- 深入理解JavaScript类与面向对象编程
- Argspect-0.0.1版本Python包发布与使用说明
- OpenNetAdmin v09.07.15 PHP项目源码下载
- 掌握Node.js: 构建高性能Web服务器与应用程序
- Matlab矢量绘图工具:polarG函数使用详解
- 实现Vue.js中PDF文件的签名显示功能
- 开源项目PSPSolver:资源约束调度问题求解器库
- 探索vwru系统:大众的虚拟现实招聘平台
- 深入理解cJSON:案例与源文件解析
- 多边形扩展算法在MATLAB中的应用与实现
- 用React类组件创建迷你待办事项列表指南
- Python库setuptools-58.5.3助力高效开发
- fmfiles工具:在MATLAB中查找丢失文件并列出错误
- 老枪二级域名系统PHP源码简易版发布
- 探索DOSGUI开源库:C/C++图形界面开发新篇章
