使用SVM进行上证指数涨跌预测的监督学习实践
需积分: 0 167 浏览量
更新于2024-08-05
收藏 658KB PDF 举报
"这篇文档是关于使用监督学习预测上证指数涨跌的教程,主要采用支持向量机(SVM)算法。数据来源于网易财经,包含了从1997年到2017年的上证指数历史数据。目标是根据过去150天的数据预测当天的涨跌情况。在实现过程中,利用了pandas、numpy和sklearn等Python库进行数据处理和模型构建,并采用了交叉验证来评估模型性能。"
在监督学习中,我们首先需要构建一个模型,该模型能够通过已知的输入(特征)和输出(标签)学习规律,然后用于未知数据的预测。在这个案例中,我们关注的是上证指数的涨跌预测。为了实现这个目标,我们需要进行以下步骤:
1. **数据加载与预处理**:使用pandas的`read_csv`函数从CSV文件中读取数据,`encoding='gbk'`用于处理中文编码,`parse_dates=[0]`将第一列(日期)转换为日期类型,`index_col=0`设置日期作为数据的索引。接着,使用`sort_index`按时间顺序排列数据。
2. **特征提取**:由于我们要基于过去150天的数据进行预测,所以选取了150天内每天的五个特征值,总共形成`featurenum=5*dayfeature`个特征。创建两个numpy数组,`x`存储特征,`y`存储对应的涨跌标签。
3. **模型建立**:这里选用的是sklearn库中的SVM(Support Vector Machine,支持向量机)。SVM是一种二分类模型,能够找到一个最优超平面来区分两类样本。在这个问题中,它会试图找到一个决策边界,将上涨日和下跌日分开。
4. **模型训练**:使用训练数据(特征`x`和标签`y`)对SVM模型进行训练。SVM通过最大化边距来最小化分类错误,同时考虑样本距离决策边界的距离,确保泛化能力。
5. **交叉验证**:sklearn的`cross_validation`模块提供了交叉验证功能,可以将数据集分成多个子集,每次用一部分作为测试集,其余部分作为训练集,重复多次以得到更稳定的结果。这有助于防止过拟合,提高模型的泛化性能。
6. **模型评估**:训练完成后,使用验证集或测试集评估模型的性能,常见的评估指标包括准确率、精确率、召回率和F1分数等。
7. **模型优化**:如果模型性能不理想,可以通过调整模型参数(如SVM的C和γ参数),或者进行特征选择和降维来提升模型效果。
8. **预测与应用**:最后,我们可以用训练好的模型对未来的新数据进行预测,从而预测上证指数的涨跌。
整个过程中,pandas库用于数据的加载和处理,numpy库提供了矩阵运算的支持,而sklearn库则提供了SVM算法和交叉验证功能,使得模型的构建和评估变得方便快捷。这个例子展示了如何在实际问题中运用机器学习技术解决金融领域的预测问题。
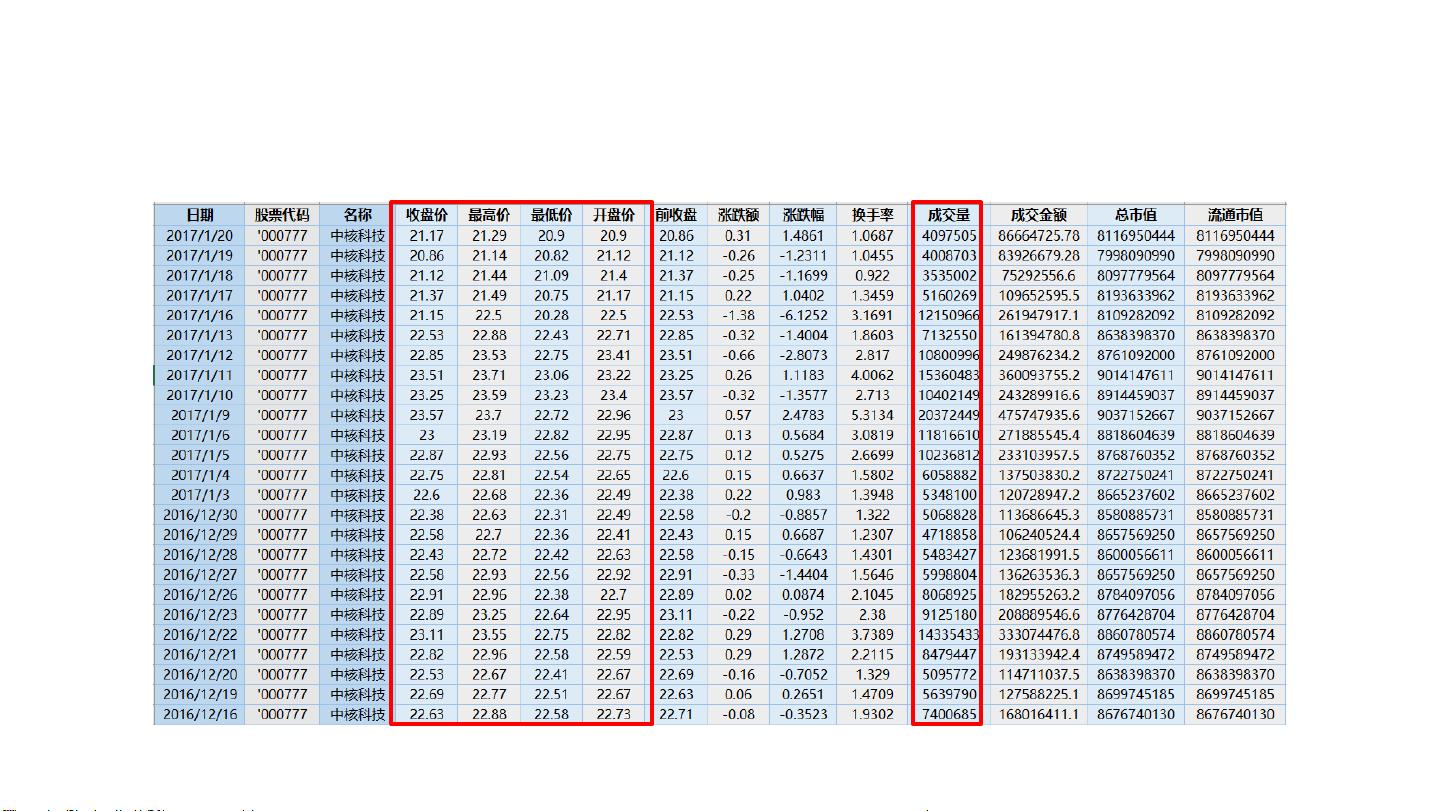
中核科技1997年到2017年的股票数据部分截图,红框部分为选取的特征值
数据实例:
剩余11页未读,继续阅读
2020-01-11 上传
2023-05-29 上传
2022-08-08 上传
2021-12-07 上传
2022-08-03 上传
2021-11-09 上传
2024-01-19 上传

陈莽昆
- 粉丝: 29
- 资源: 289
 我的内容管理
展开
我的内容管理
展开







最新资源
- Fisher Iris Setosa数据的主成分分析及可视化- Matlab实现
- 深入理解JavaScript类与面向对象编程
- Argspect-0.0.1版本Python包发布与使用说明
- OpenNetAdmin v09.07.15 PHP项目源码下载
- 掌握Node.js: 构建高性能Web服务器与应用程序
- Matlab矢量绘图工具:polarG函数使用详解
- 实现Vue.js中PDF文件的签名显示功能
- 开源项目PSPSolver:资源约束调度问题求解器库
- 探索vwru系统:大众的虚拟现实招聘平台
- 深入理解cJSON:案例与源文件解析
- 多边形扩展算法在MATLAB中的应用与实现
- 用React类组件创建迷你待办事项列表指南
- Python库setuptools-58.5.3助力高效开发
- fmfiles工具:在MATLAB中查找丢失文件并列出错误
- 老枪二级域名系统PHP源码简易版发布
- 探索DOSGUI开源库:C/C++图形界面开发新篇章
