Flink本地部署与使用指南
需积分: 10 43 浏览量
更新于2024-09-03
收藏 2.31MB PDF 举报
"这篇文档是关于Flink的安装与使用教程,主要涵盖了本地部署的步骤以及简单的操作示例。作者zealscott分享了如何在本地环境中安装Flink,包括从官网下载、解压、修改配置文件、添加环境变量以及启动Flink集群。此外,文档还提到了Flink的JobManager提供的Web前端界面,用户可以通过该界面监控系统状态。"
Flink是一个开源的流处理框架,由Apache软件基金会维护,它提供了强大的流处理和批处理能力。在本文档中,作者首先介绍了如何在本地环境中安装Flink。这通常适用于开发者在开发和测试阶段进行快速迭代。以下是对安装过程的详细解析:
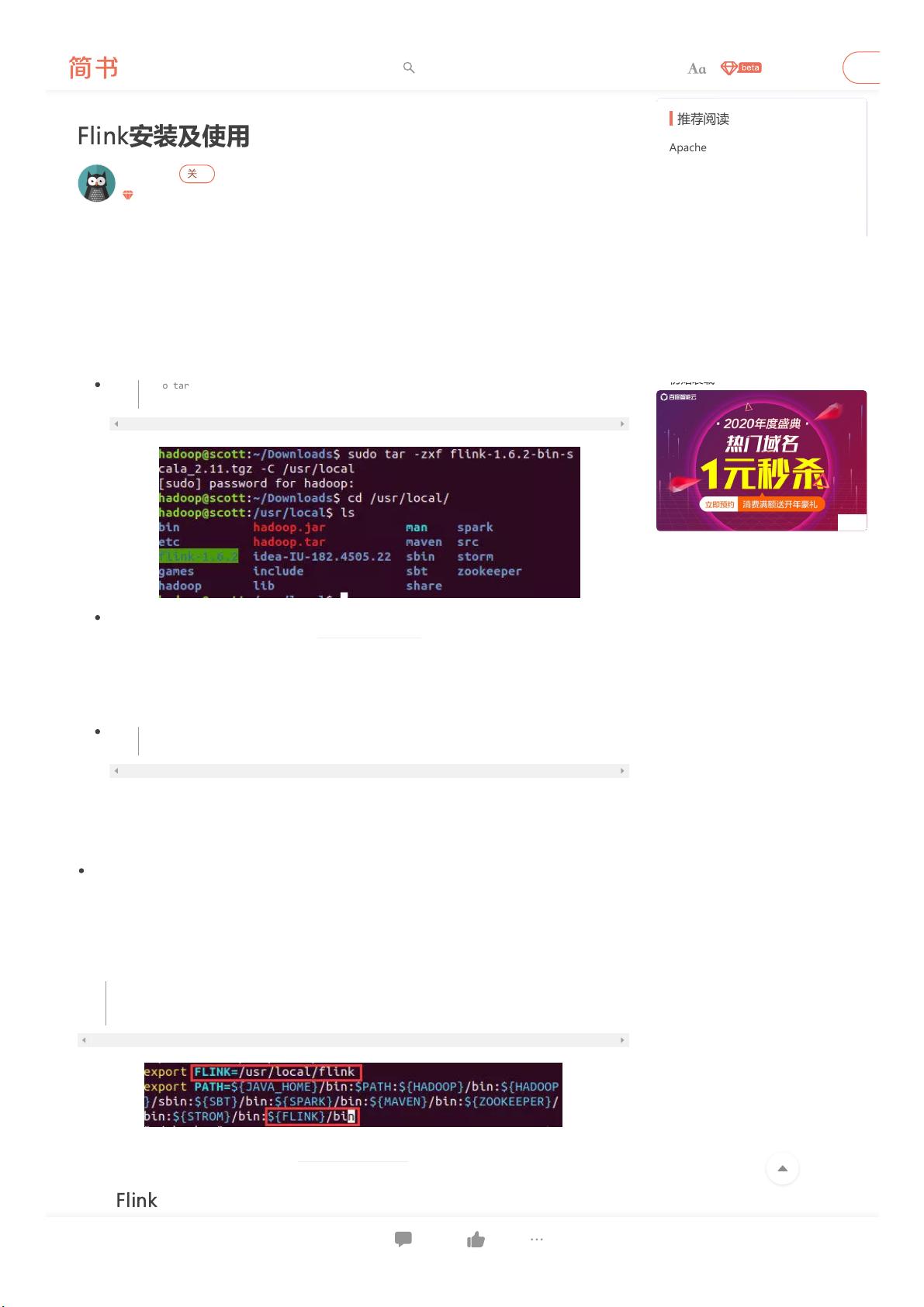
1. 下载Flink:用户可以从Flink的官方网站获取最新版本的Flink发行包,例如文中提到的`sudotar-zxfflink-1.6.2-bin-hadoop27-scala_2.11.tgz`。
2. 解压并重命名:将下载的压缩文件解压至指定目录,如`/usr/local`,然后将解压后的目录重命名为`flink`。
3. 设置权限:为了能正确运行Flink,需要更改目录的所有者和权限,例如使用`chown -R hadoop:hadoop ./flink`命令将所有者改为`hadoop`用户和组。
4. 修改配置:Flink的配置文件位于`conf/flink-conf.yaml`,这里可以设置Java运行环境,例如将`env.java.home`设置为本地Java的绝对路径。
5. 添加环境变量:为了能在命令行中方便地调用Flink的命令,需要在`.bashrc`文件中添加`FLINK_HOME`环境变量,并将`bin`目录加入PATH。
6. 启动Flink集群:执行`start-cluster.sh`脚本,启动Flink集群。启动成功后,JobManager会在8081端口提供Web前端服务,用户可以通过`http://localhost:8081`访问。
7. 验证运行:通过检查`logs`目录下的日志,以及Web前端界面,确认Flink集群已正常启动并运行。
接下来,文档虽然没有在提供的内容中继续,但通常会涵盖如何编写和提交Flink作业。用户通常会使用Maven或Gradle创建项目,添加Flink依赖,并编写处理逻辑。之后,可以使用`flink run`命令或者通过Web前端提交作业到集群执行。
在实际使用中,Flink支持多种数据源和数据接收器,可以处理连续的数据流,并提供了丰富的算子进行数据转换。Flink还具备强大的状态管理和容错机制,保证了在分布式环境下的高可用性和数据一致性。
此外,Flink的API包括DataStream API(用于处理无界和有界数据流)和DataSet API(主要用于批处理),以及近年来推出的Table API和SQL接口,使得开发更加简洁易懂。对于大型数据处理场景,Flink也可以与Hadoop、Hive等其他大数据组件集成,实现更复杂的数据处理任务。
1/10/2020 Flink安装及使用 - 简书
https://www.jianshu.com/p/bbaa8d72cfcf 1/7
Flink
安装及使用
zealscott
0.094 2018.12.04 10:07:23 字数 396 阅读 6,868
本地部署
安装
1. 在官网安装Flink,并解压到 /usr/local/flink
54388226982
2. 修改文件名字,并设置权限
修改配置文件
Flink 对于本地模式是开箱即用的,如果要修改Java运行环境,可修改 conf/flink-conf.yaml 中
的 env.java.home ,设置为本地java的绝对路径
添加环境变量
54388242695
启动
Flink
zealscott
总资产22 (约2.14元)
Hive优化
阅读 160
初始装载
阅读 66
关注
sudo tar -zxf flink-1.6.2-bin-hadoop27-scala_2.11.tgz -C /usr/local
cd /usr/local
1
2
sudo mv ./flink-*/ ./flink
sudo chown -R hadoop:hadoop ./flink
1
2
vim ~/.bashrc
export FLNK_HOME=/usr/local/flink
export PATH=$FLINK_HOME/bin:$PATH
1
2
3
start-cluster.sh
1
广告
关注
推荐阅读
Apache Spark在海致大数据平台中的
优化实践
阅读 629
简单说说数据仓库
阅读 204
Flink 源码之JobGraph生成
阅读 50
Flink去重第一弹:MapState去重
阅读 559
Flink operator状态管理
阅读 85
广告
首页 下载APP
登录 注册
搜索
评论1 赞2
写下你的评论...
下载后可阅读完整内容,剩余6页未读,立即下载
2018-10-09 上传
2023-06-07 上传
2023-06-02 上传
2023-05-13 上传
2023-09-12 上传
2023-08-12 上传
2024-05-30 上传

尾的zw
- 粉丝: 1
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java集合ArrayList实现字符串管理及效果展示
- 实现2D3D相机拾取射线的关键技术
- LiveLy-公寓管理门户:创新体验与技术实现
- 易语言打造的快捷禁止程序运行小工具
- Microgateway核心:实现配置和插件的主端口转发
- 掌握Java基本操作:增删查改入门代码详解
- Apache Tomcat 7.0.109 Windows版下载指南
- Qt实现文件系统浏览器界面设计与功能开发
- ReactJS新手实验:搭建与运行教程
- 探索生成艺术:几个月创意Processing实验
- Django框架下Cisco IOx平台实战开发案例源码解析
- 在Linux环境下配置Java版VTK开发环境
- 29街网上城市公司网站系统v1.0:企业建站全面解决方案
- WordPress CMB2插件的Suggest字段类型使用教程
- TCP协议实现的Java桌面聊天客户端应用
- ANR-WatchDog: 检测Android应用无响应并报告异常
