CUDA编程入门指南:利用GPU加速计算
需积分: 50 20 浏览量
更新于2024-07-18
收藏 1.14MB PDF 举报
CUDA编程入门教程是一份针对初学者设计的指南,由NVIDIA公司于2006年推出,旨在利用NVIDIA GPU的并行计算能力来提升计算效率,尤其是在深度学习等需要大量数据并行处理的领域。CUDA的核心是建立在NVIDIA CPU之上的通用并行计算平台,通过编程模型使得开发者能够利用GPU的众多运算核心来执行数据密集型任务,如矩阵运算。
教程强调了GPU与CPU之间的异构计算架构,即GPU作为CPU的协处理器,通过PCIe总线与主机端的CPU协同工作。GPU的特点是拥有众多轻量级线程,适用于大规模并行计算,而CPU则负责更复杂的逻辑运算和控制流程,两者优势互补。例如,在深度学习训练中,GPU负责大量的矩阵乘法和激活函数计算,而CPU处理网络结构定义和优化等任务。
CUDA编程为开发者提供了一种简便的接口,支持多种编程语言,如C、C++,使得原本可能在CPU上耗时的任务能够在GPU上加速执行。此外,教程还可能涉及CUDA编程的基本概念,如CUDA设备和主机之间的通信机制、线程组织、内存管理以及如何编写CUDA kernels(GPU上的自定义函数)等内容。
对于想要入门CUDA编程的读者,这本教程应该是非常实用的资源,它将帮助学习者理解CUDA编程的基本原理,熟悉其编程环境,以及如何有效地将计算任务分解到GPU上,从而提高计算性能。随着CUDA版本的更新,教程可能会包含对新特性和技术的介绍,确保读者紧跟CUDA技术的发展步伐。
2018/5/18 CUDA编程入门极简教程
https://zhuanlan.zhihu.com/p/34587739 3/15
函数,并且每个线程会分配一个唯一的线程号thread ID,这个ID值可以通过核函数的内置变量
threadIdx 来获得。
由于GPU实际上是异构模型,所以需要区分host和device上的代码,在CUDA中是通过函数类型限
定词开区别host和device上的函数,主要的三个函数类型限定词如下:
• __global__ :在device上执行,从host中调用(一些特定的GPU也可以从device上调用),返
回类型必须是 void ,不支持可变参数参数,不能成为类成员函数。注意用 __global__ 定义的
kernel是异步的,这意味着host不会等待kernel执行完就执行下一步。
• __device__ :在device上执行,单仅可以从device中调用,不可以和 __global__ 同时用。
• __host__ :在host上执行,仅可以从host上调用,一般省略不写,不可以和 __global__ 同时
用,但可和 __device__ ,此时函数会在device和host都编译。
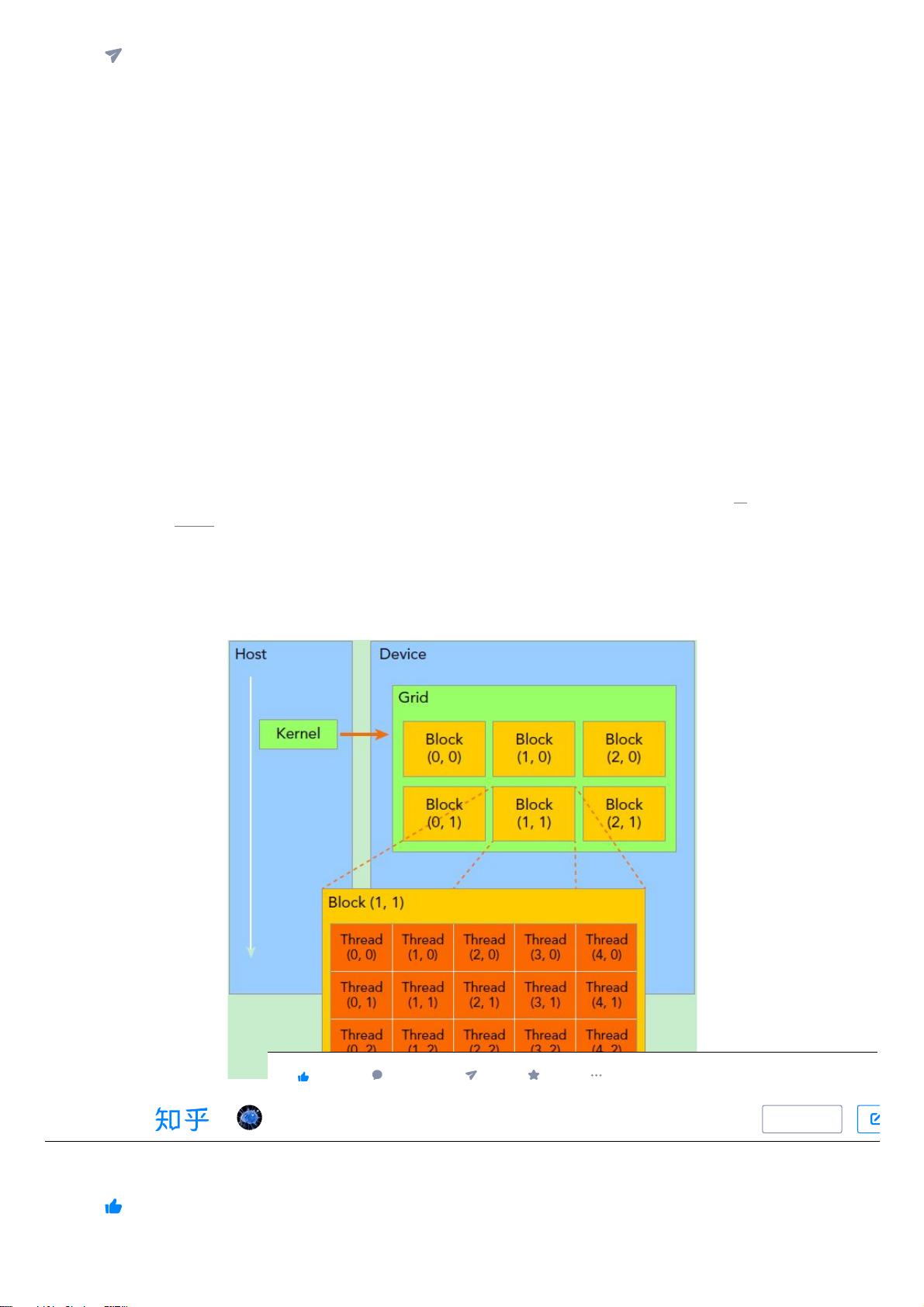
要深刻理解kernel,必须要对kernel的线程层次结构有一个清晰的认识。首先GPU上很多并行化的
轻量级线程。kernel在device上执行时实际上是启动很多线程,一个kernel所启动的所有线程称为
一个网格(grid),同一个网格上的线程共享相同的全局内存空间,grid是线程结构的第一层次,
而网格又可以分为很多线程块(block),一个线程块里面包含很多线程,这是第二个层次。线程
两层组织结构如下图所示,这是一个gird和block均为2-dim的线程组织。grid和block都是定义
为 dim3 类型的变量, dim3 可以看成是包含三个无符号整数(x,y,z)成员的结构体变量,在定
义时,缺省值初始化为1。因此grid和block可以灵活地定义为1-dim,2-dim以及3-dim结构,对
于图中结构(主要水平方向为x轴),定义的grid和block如下所示,kernel在调用时也必须通过执
行配置 <<<grid, block>>> 来指定kernel所使用的线程数及结构。
dim3 grid(3, 2);
dim3 block(5, 3);
kernel_fun<<< grid, block >>>(prams...);
Kernel上的两层线程组织结构(2-dim)
所以,一个线程需要两个内置的坐标变量(blockIdx,threadIdx)来唯一标识,它们都是 dim3
类型变量,其中blockIdx指明线程所在grid中的位置,而threaIdx指明线程所在block中的位置,
如图中的Thread (1,1)满足:
threadIdx.x = 1
threadIdx.y = 1
首发于
机器学习算法工程师
已关注
分享
425
425 27 条评论 收藏分享
分享
425
425
剩余14页未读,继续阅读
2017-09-09 上传
2022-09-23 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

经常不在
- 粉丝: 1
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







