Elasticsearch倒排索引详解:速度优势与工作原理
8 浏览量
更新于2024-09-01
收藏 520KB PDF 举报
在本篇文章中,我们将深入了解时间序列数据库的秘密——索引在Elasticsearch中的应用,以及它与关系型数据库的b-tree索引相比所具有的优势。Elasticsearch利用了Lucene的倒排索引技术,这种索引方式特别适合处理复杂的多条件过滤查询,例如年龄范围和性别筛选,其性能优于b-tree索引,尤其是在检索速度上。
首先,b-tree索引是一种为写入优化的设计,它的目标是提供高效的插入和删除操作,但牺牲了部分更新速度。相比之下,倒排索引是为搜索优化的,它将文档的每个字段分解为独立的倒排索引,每个term(关键词)对应一个posting list,存储包含该term的所有文档ID。这使得查询时能够快速定位到相关的文档,即使数据量庞大也能保持较高的效率。
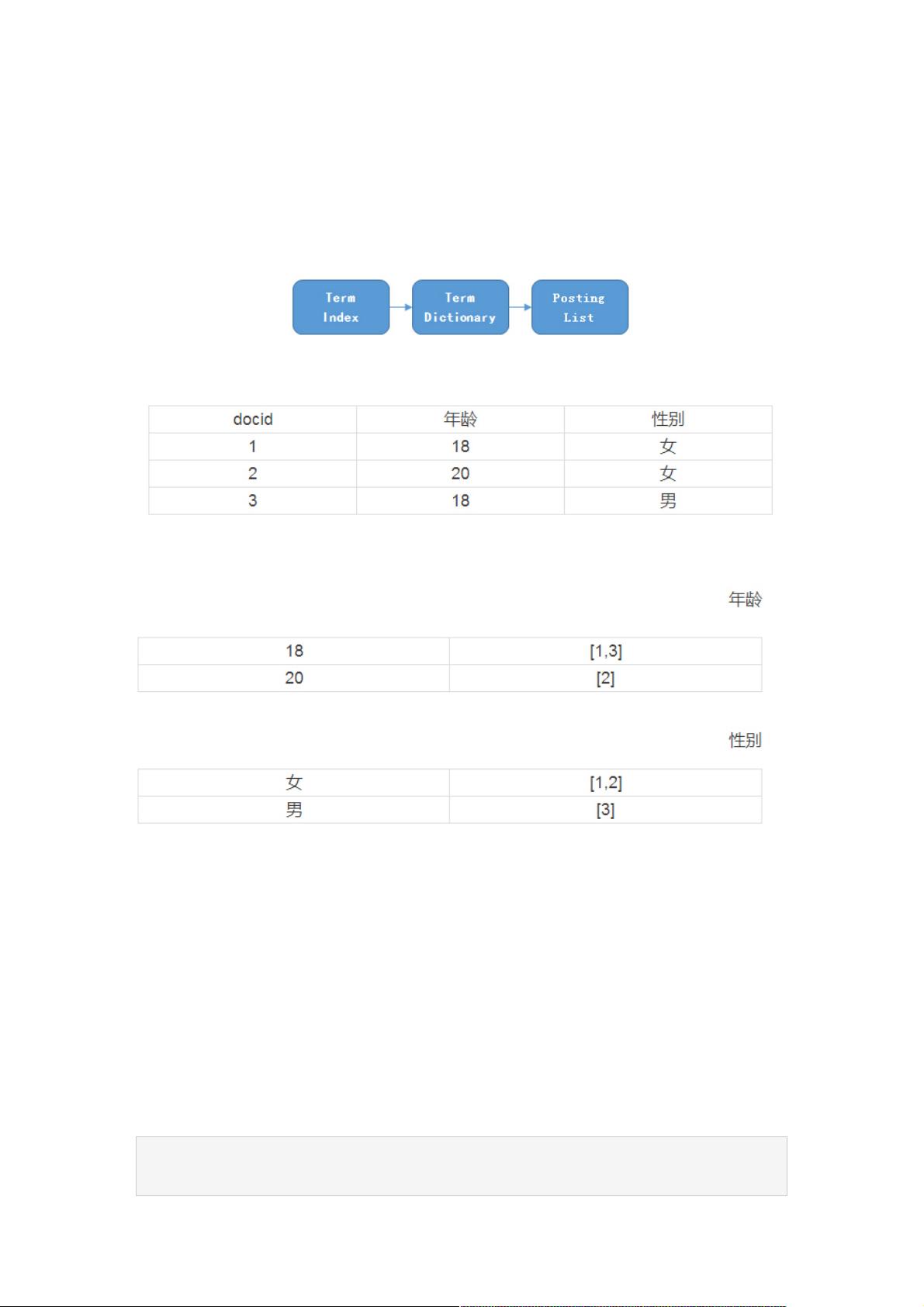
Termdictionary的概念在此起着关键作用,它是一种预排序的术语表,允许通过二分查找找到特定的term,大大减少了搜索时间。然而,由于磁盘读取操作的高成本,需要通过内存缓存来减少磁盘I/O。为了管理庞大的termdictionary,Lucene引入了termindex,类似于书的目录,将term按字母或某个规则分组,形成小的页面,便于快速定位到目标term所在的页码。
Elasticsearch的倒排索引设计通过牺牲部分更新性能来换取更快的查询速度和更小的存储需求。这对于实时分析和大数据处理场景至关重要,尤其是对于需要频繁查询和过滤的应用。理解这些索引机制有助于我们更好地优化查询策略,提高时间序列数据库的性能。
时间序列数据库的秘密时间序列数据库的秘密(二二)——索引索引
如何快速检索?
Elasticsearch是通过Lucene的倒排索引技术实现比关系型数据库更快的过滤。特别是它对多条件的过滤支持非常好,比如年
龄在18和30之间,性别为女性这样的组合查询。倒排索引很多地方都有介绍,但是其比关系型数据库的b-tree索引快在哪里?
到底为什么快呢?
笼统的来说,b-tree索引是为写入优化的索引结构。当我们不需要支持快速的更新的时候,可以用预先排序等方式换取更小的
存储空间,更快的检索速度等好处,其代价就是更新慢。要进一步深入的化,还是要看一下Lucene的倒排索引是怎么构成
的。
这里有好几个概念。我们来看一个实际的例子,假设有如下的数据:
这里每一行是一个document。每个document都有一个docid。那么给这些document建立的倒排索引就是:
可以看到,倒排索引是per field的,一个字段由一个自己的倒排索引。18,20这些叫做 term,而[1,3]就是posting list。Posting
list就是一个int的数组,存储了所有符合某个term的文档id。那么什么是term dictionary 和 term index?
假设我们有很多个term,比如:
Carla,Sara,Elin,Ada,Patty,Kate,Selena
如果按照这样的顺序排列,找出某个特定的term一定很慢,因为term没有排序,需要全部过滤一遍才能找出特定的term。排序
之后就变成了:
Ada,Carla,Elin,Kate,Patty,Sara,Selena
这样我们可以用二分查找的方式,比全遍历更快地找出目标的term。这个就是 term dictionary。有了term dictionary之后,可
以用 logN 次磁盘查找得到目标。但是磁盘的随机读操作仍然是非常昂贵的(一次random access大概需要10ms的时间)。所
以尽量少的读磁盘,有必要把一些数据缓存到内存里。但是整个term dictionary本身又太大了,无法完整地放到内存里。于是
就有了term index。term index有点像一本字典的大的章节表。比如:
A开头的term ……………. Xxx页
C开头的term ……………. Xxx页
E开头的term ……………. Xxx页
如果所有的term都是英文字符的话,可能这个term index就真的是26个英文字符表构成的了。但是实际的情况是,term未必都
是英文字符,term可以是任意的byte数组。而且26个英文字符也未必是每一个字符都有均等的term,比如x字符开头的term可
下载后可阅读完整内容,剩余4页未读,立即下载
244 浏览量
点击了解资源详情
1522 浏览量
116 浏览量
182 浏览量
147 浏览量
2009-09-07 上传
124 浏览量
点击了解资源详情

weixin_38610070
- 粉丝: 2
- 资源: 940
 我的内容管理
展开
我的内容管理
展开







最新资源
- spring&hibernate整合
- 操作手册(GB8567——88).doc
- Bluetooth Tutorial
- CANopen协议中文简介.pdf
- UML_Concept
- [Bruce.Eckel编程思想系列丛书].PRENTICE_HALL-Thinking_In_Python
- 达内oracle笔记
- Java数据库查询结果的输出
- linux0.11注释-赵炯
- ALV development operation guide
- exp/imp导出导入工具的使用
- 很完善的oracle函数手册
- Oracle傻瓜手册
- jdbc连接驱动大全
- HTML指令HTML指令
- ActionScript.3.0.Cookbook.中文完整版
