李宏毅深度强化学习:Q-Learning解析
需积分: 9 23 浏览量
更新于2024-07-17
收藏 1.6MB PDF 举报
"台湾李宏毅老师的深度强化学习PPT,涵盖了Q-Learning的基本概念、技巧以及连续动作的处理方法,对于理解强化学习中的评价函数(Critic)和策略(Actor)有很好的指导作用。"
在深度强化学习中,Q-Learning是一种广泛使用的算法,它属于模型自由型强化学习,允许智能体在未知环境中通过与环境的交互来学习最佳策略。Q-Learning的目标是学习一个Q表,其中每个状态-动作对都有一个对应的Q值,代表采取该动作后预期的累积奖励。
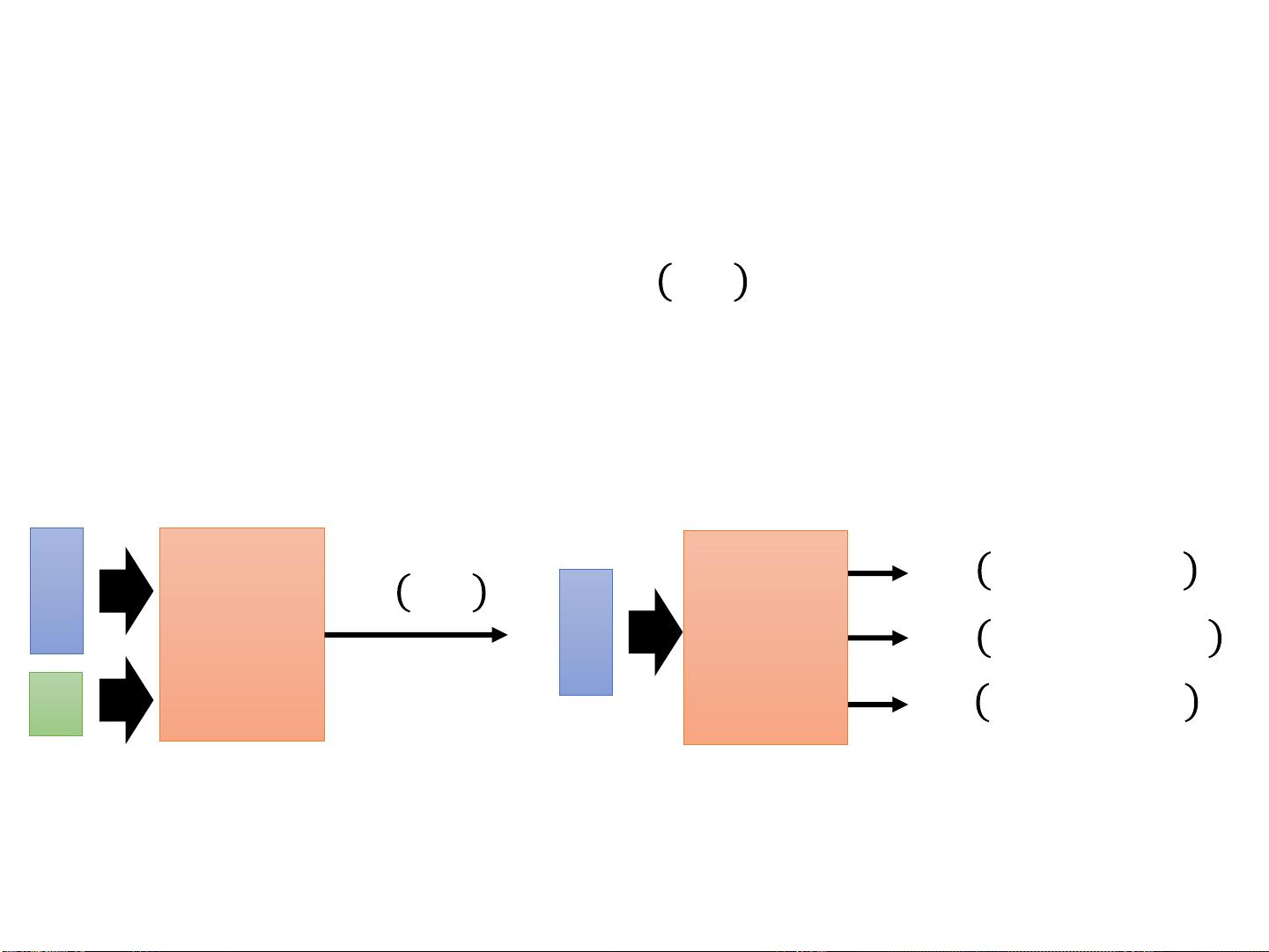
Hung-yi Lee教授在PPT中提到,Critic在强化学习中扮演着评价者角色,它并不直接影响智能体的动作选择,而是评估当前策略(Actor)的好坏。Critic通过计算状态价值函数𝑉𝜋𝑠来评估策略,这个函数表示遵循策略π时,从状态𝑠出发所能得到的未来奖励期望。如果𝑉𝜋𝑠较大,意味着该状态对策略π来说是有利的,反之则不利。
Critic的估计方法有两种主要途径:蒙特卡洛(Monte-Carlo, MC)和时间差分(Temporal-Difference, TD)。在MC方法中,Critic观察策略π玩游戏,等到一个完整的episode结束时,根据累计奖励𝐺𝑎来更新状态值函数𝑉𝜋𝑠。这种方法的更新较为准确,但缺点是必须等待整个episode结束,对于长时间序列的问题,学习速度会很慢。
相比之下,TD方法允许在每一步都进行学习,通过公式𝑉𝜋𝑠𝑡 = 𝑉𝜋𝑠𝑡+1 + 𝑟𝑡 + 𝛼(𝑉𝜋𝑠𝑡−𝑉𝜋𝑠𝑡+1)来进行即时的Q值更新,其中𝑟𝑡是当前获得的奖励,𝛼是学习率。TD方法的更新速度快,但可能会带来较大的方差,且可能不够准确,因为它依赖于当前的预测。
在处理连续动作的Q-Learning时,由于现实世界问题中的动作空间通常是连续的,因此需要采用近似方法,如神经网络来估计Q值。这种方法称为深度Q网络(Deep Q-Network, DQN),它引入了经验回放缓冲区和目标网络等技术,以解决连续动作空间的学习挑战。
李宏毅老师的深度强化学习课程深入浅出地讲解了Q-Learning的核心概念,包括Critic和Actor的区分、Critic的估价方式以及连续动作的处理,对于想要深入理解和应用强化学习的人士是非常宝贵的资源。通过学习这些内容,我们可以更好地掌握强化学习的理论基础,并将其应用于实际问题中。
MC v.s. TD
• The critic has the following 8 episodes
•
, END
•
, END
•
, END
•
, END
•
, END
•
, END
•
, END
•
, END
[Sutton, v2,
Example 6.4]
(The actions are ignored here.)
0?
3/4?
Monte-Carlo:
Temporal-difference:
3/43/4
0
剩余42页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
230 浏览量
147 浏览量

wc409
- 粉丝: 1
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- CrystalDiskMark8
- 十九种不良生活习惯PPT
- Android-SecretCodes:Secret Codes是一个开源应用程序,可让您浏览Android手机的隐藏代码-Android application source code
- data-utils:围绕数据解析和转换的辅助函数集合
- bric_sheets_react
- yeelight:用于通过局域网控制yeeelight的nodeJS客户端库
- leetcode答案-daily_coding_problems:存储库包含我对DailyCodingProblem和InterviewCak
- 登录
- WechatApp-cinema:基于云开发的电影院订票微信小程序
- 资产负债管理
- STBlueMS_Android:“ ST BLE传感器” Android应用程序源代码-Android application source code
- crack:从Merb和Rails中复制的真正简单的JSON和XML解析
- cloud-dapr-demo:Dapr运行时演示和云提供商的无缝集成
- sherlock:夏洛克
- 熵权法 MATLAB实现,熵权法matlab实现+层次分析法,matlab源码.zip
- 组织设计与权力配置
