数据挖掘2009年十大算法详解 - X. Wu & V. Kumar
需积分: 9 183 浏览量
更新于2024-08-01
收藏 5.95MB PDF 举报
"The Top Ten Algorithms in Data Mining 2009 - X. Wu & V. Kumar -"
在数据挖掘领域,算法的选择对于解决问题至关重要。2009年,X. Wu 和 V. Kumar 提出了一份关于数据挖掘领域的十大算法列表。这些算法在学术界和工业界都具有广泛的影响,是理解和应用数据挖掘技术的基础。以下是对这十大算法的详细解释:
1. **Apriori**:Apriori 算法是一种关联规则学习算法,用于发现数据库中项集之间的频繁模式。它通过迭代的方式生成候选集并进行支持度计算,有效地避免了对全数据库的扫描。
2. **ID3 (Iterative Dichotomiser 3)**:ID3 是决策树学习的经典算法,基于信息熵和信息增益来选择最佳划分属性,用于分类任务。
3. **C4.5**:C4.5 是 ID3 的改进版本,解决了 ID3 中的一些问题,如处理连续属性和类别不平衡。它使用信息增益比作为分裂标准,并能处理缺失值。
4. **K-Nearest Neighbors (KNN)**:KNN 是一种基于实例的学习方法,用于分类和回归。它根据最近邻的距离(通常是欧氏距离)将新样本分配到最接近的多数类。
5. **Naive Bayes**:朴素贝叶斯算法基于贝叶斯定理,假设特征之间相互独立,用于概率分类。尽管其“朴素”假设可能过于简化,但在许多实际问题中仍表现出良好的性能。
6. **SVM (Support Vector Machines)**:支持向量机是一种监督学习模型,通过构造最大边距超平面来分离数据。SVM 在高维空间中的分类效果尤为出色,并可以应用于非线性问题。
7. ** CART (Classification and Regression Trees)**:CART 生成二叉决策树,不仅用于分类,还可用于回归任务。它通过最小化不纯度或Gini指数来选择最优分割点。
8. **EM (Expectation-Maximization)**:EM 算法是一种用于估计混合模型参数的迭代方法,如高斯混合模型。它通过期望步骤和最大化步骤交替更新参数,直至收敛。
9. **PageRank**:PageRank 是谷歌搜索引擎的核心算法,用于评估网页的重要性。它通过模拟随机浏览网络的行为来确定网页的排名。
10. **DBSCAN (Density-Based Spatial Clustering of Applications with Noise)**:DBSCAN 是一种基于密度的空间聚类算法,可以发现任意形状的聚类,并对噪声有很好的容忍度。
这些算法构成了数据挖掘的基础工具箱,它们各自适用于不同的问题和数据类型。了解并熟练运用这些算法对于数据科学家来说至关重要,能够帮助他们更好地从海量数据中提取有价值的信息。同时,随着数据科学的发展,新的算法不断涌现,但这些经典的算法依然保持着重要的地位。
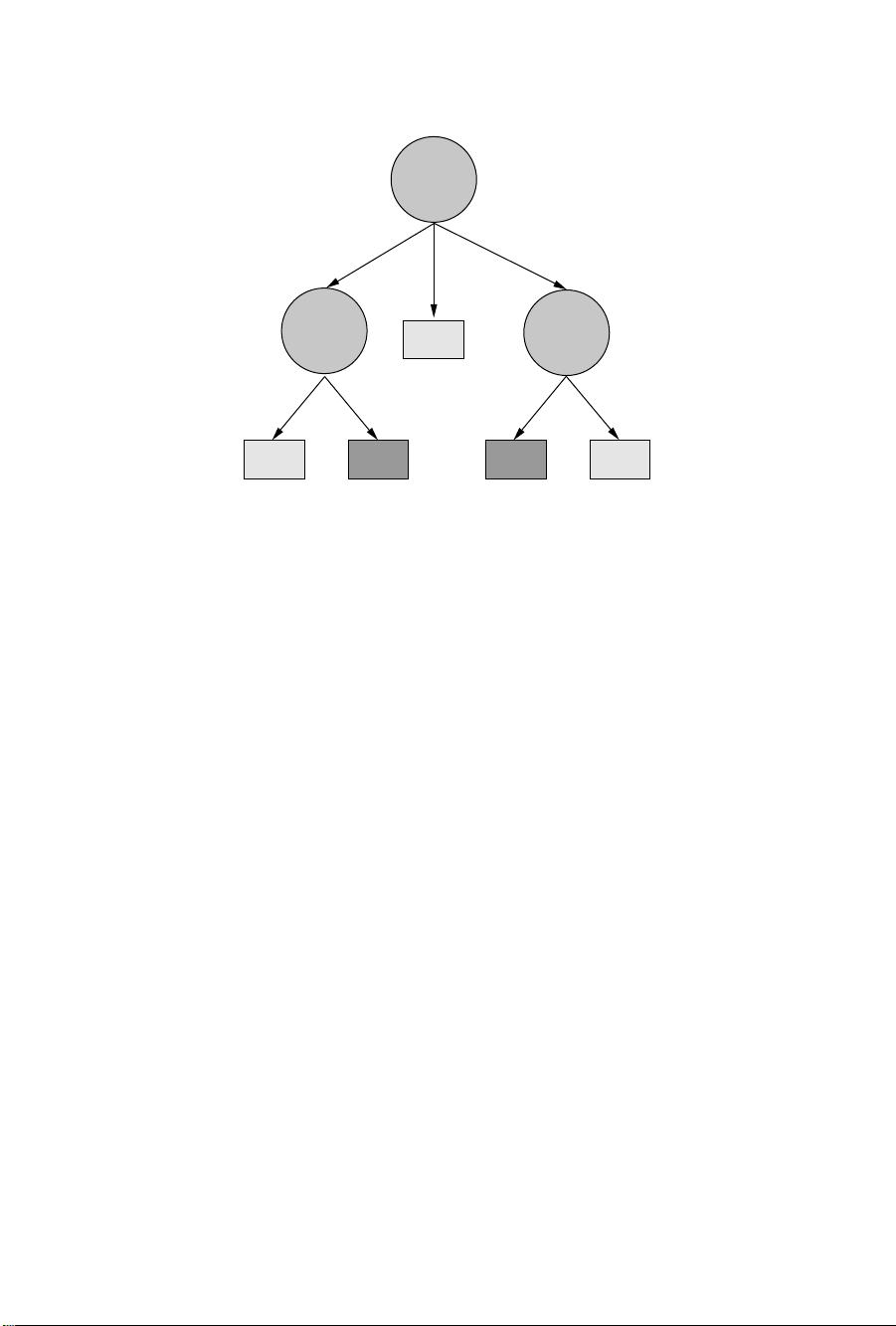
4 C4.5
Yes
Yes
Yes
No No
Outlook
Humidity
Windy
Sunny Rainy
Overcast
>75<=75 FalseTrue
Figure 1.2 Decision tree induced by C4.5 for the dataset of Figure 1.1.
Figure 1.1 presents the classical “golf” dataset, which is bundled with the C4.5
installation. As stated earlier, the goal is to predict whether the weather conditions
on a particular day are conducive to playing golf. Recall that some of the features are
continuous-valued while others are categorical.
Figure 1.2 illustrates the tree induced by C4.5 using Figure 1.1 as training data
(and the default options). Let us look at the various choices involved in inducing such
trees from the data.
r
What types of tests are possible? As Figure 1.2 shows, C4.5 is not restricted
to considering binary tests, and allows tests with two or more outcomes. If the
attribute is Boolean, the test induces two branches. If the attribute is categorical,
the test is multivalued, but different values can be grouped into a smaller set of
options with one class predicted for each option. If the attribute is numerical,
then the tests are again binary-valued, and of the form {≤ θ?,> θ?}, where θ
is a suitably determined threshold for that attribute.
r
How are tests chosen? C4.5 uses information-theoretic criteria such as gain
(reduction in entropy of the class distribution due to applying a test) and
gain ratio (a way to correct for the tendency of gain to favor tests with many
outcomes). The default criterion is gain ratio. At each point in the tree-growing,
the test with the best criteria is greedily chosen.
r
How are test thresholds chosen? As stated earlier, for Boolean and categorical
attributes, the test values are simply the different possible instantiations of that
attribute. For numerical attributes, the threshold is obtained by sorting on that
attribute and choosing the split between successive values that maximize the
criteria above. Fayyad and Irani [10] showed that not all successive values need
to be considered. For two successive values v
i
and v
i+1
of a continuous-valued
© 2009 by Taylor & Francis Group, LLC



剩余204页未读,继续阅读
2014-10-27 上传
2021-09-29 上传
2021-08-11 上传
2019-09-17 上传
2011-02-19 上传
2019-09-17 上传
2024-08-29 上传
2019-09-14 上传
2019-09-17 上传

ALuya
- 粉丝: 36
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- Raspberry Pi OpenCL驱动程序安装与QEMU仿真指南
- Apache RocketMQ Go客户端:全面支持与消息处理功能
- WStage平台:无线传感器网络阶段数据交互技术
- 基于Java SpringBoot和微信小程序的ssm智能仓储系统开发
- CorrectMe项目:自动更正与建议API的开发与应用
- IdeaBiz请求处理程序JAVA:自动化API调用与令牌管理
- 墨西哥面包店研讨会:介绍关键业绩指标(KPI)与评估标准
- 2014年Android音乐播放器源码学习分享
- CleverRecyclerView扩展库:滑动效果与特性增强
- 利用Python和SURF特征识别斑点猫图像
- Wurpr开源PHP MySQL包装器:安全易用且高效
- Scratch少儿编程:Kanon妹系闹钟音效素材包
- 食品分享社交应用的开发教程与功能介绍
- Cookies by lfj.io: 浏览数据智能管理与同步工具
- 掌握SSH框架与SpringMVC Hibernate集成教程
- C语言实现FFT算法及互相关性能优化指南
