基于Scrapy-Redis的微博数据爬虫与分析
需积分: 0 6 浏览量
更新于2024-06-30
收藏 5.7MB DOCX 举报
"这篇论文探讨了在网络大数据时代背景下,如何利用网络爬虫技术应对信息量急剧膨胀的问题。文章以Python2.7和Scrapy框架,结合Scrapy-Redis分布式框架,设计并实现了针对‘新浪微博’的高并发、强鲁棒性的网络爬虫,对抓取的数据进行了初步分析。"
在大数据信息时代,网络爬虫技术的重要性日益凸显。网络爬虫作为一种自动收集网页信息的工具,其灵活性和高效性使其成为处理海量数据的主要手段。随着互联网上的信息量以惊人的速度增长,传统的爬虫技术面临着如何有效、快速地采集和处理这些数据的挑战。
论文主要围绕以下几个方面展开:
1. 爬虫技术基础:介绍了爬虫的基本原理,包括网页抓取、链接解析和数据存储等环节,以及当前爬虫技术的发展状况。特别提到了Cookie池和user-agent欺骗作为突破网站访问限制的策略,以及信息过滤和搜索策略在爬虫中的应用。
2. Scrapy-Redis分布式爬虫:基于Python的Scrapy框架,结合Redis内存数据库,构建了分布式爬虫系统。Redis在这里用于实现去重、任务调度、提升爬取速度和“断点续爬”的功能。同时,论文还讨论了MongoDB等NoSQL数据库在存储元数据时的重要作用。
3. 爬虫设计的关键问题及解决方案:详细阐述了如何应对微博等网站的反爬策略,如验证码识别、URL去重以防止循环爬取,以及多线程并发处理。Scrapy-Redis框架提供了内置的工具和策略来解决这些问题。
4. 数据分析:爬虫获取到的数据经过初步分析,得出了一些有价值的小结论。这部分可能涉及内容挖掘、用户行为分析等方面,为后续的数据挖掘和分析奠定了基础。
关键词涵盖了新浪微博、Scrapy-Redis、Python、Web爬虫和数据分析等领域,表明该论文专注于实现在特定社交媒体平台上的网络爬虫设计与数据处理实践。通过这种深入的研究,可以为其他类似的大数据采集和分析项目提供参考和指导。
爬虫能用来干什么.如今每天互联网上的流量足足有 10 亿 GB 左右,不可能
毫无选择的全部爬取下来,这是要根据我们自己的需求来有选择的爬取相对应的
数据.那爬虫可以用来干什么呢?我们根据实际需要将爬虫的目标分为三类.
第一类是通过搜索引擎的网络爬虫来充实搜索引擎的索引列表.这部分需求所需
要的数据是各种网页的地址,标题,主题字等等.这方面比较知名的有 google 爬
虫,baidu 爬虫,Yahoo 爬虫等等。可以大致分为 批量型爬虫(Batch Crawler),
增量型爬虫(Incremental Crawler),垂直型爬虫(Focused Crawter).
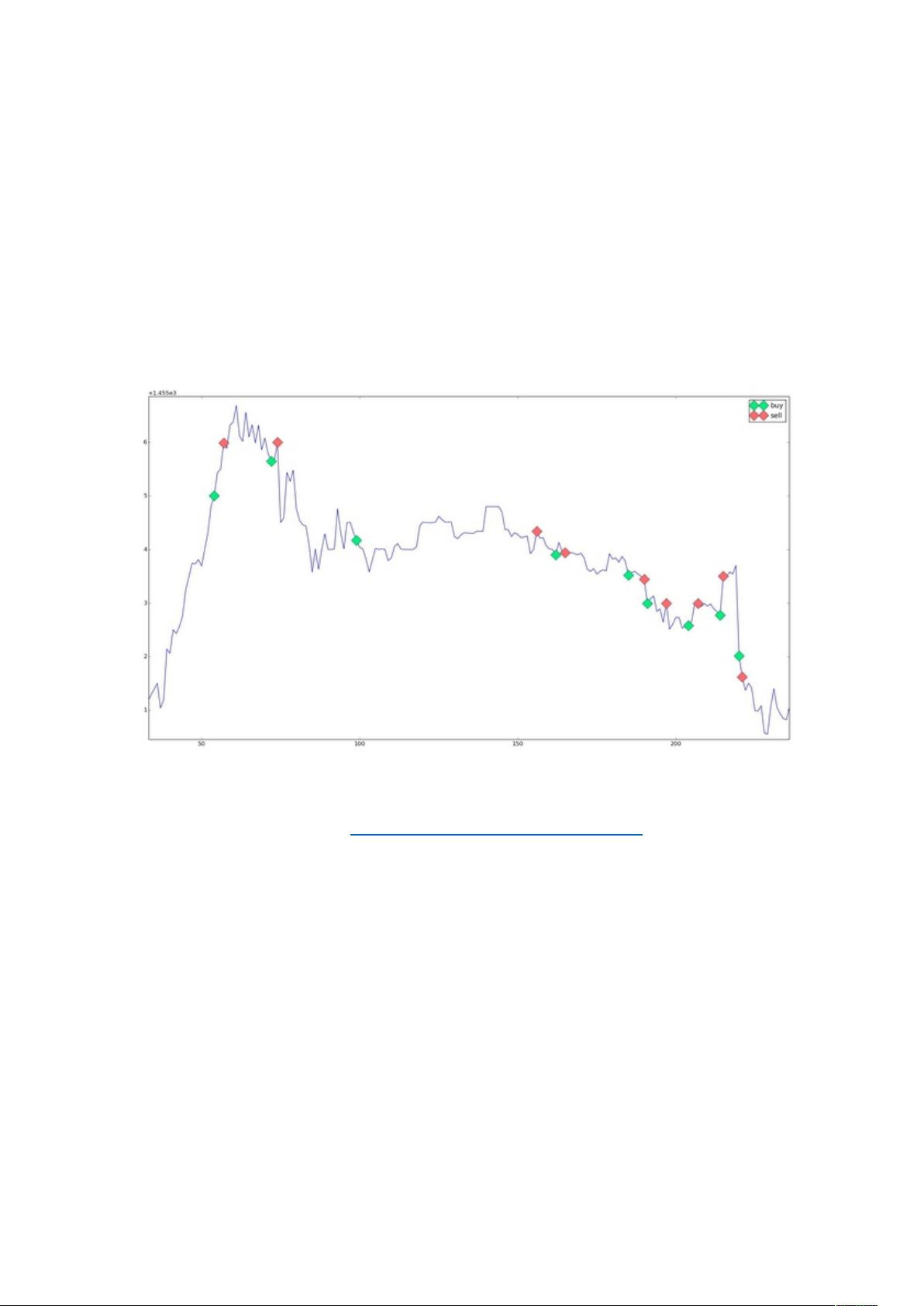
第二类建立自己的数据仓库,然后用各种机器学习模型来得出一些寻常无法得出
的预测和分析.我们可以通过这些数据集来进行预测.比如说股票,比特币和各种
风险交易。
只不过要达到这种水平,那么需要爬取到特别优质的数据集.而比特币市场比
起股票来说是一个很简单的市场,但是这也能证明爬虫在该方面的运用.
注:该 MIT 论文的链接是 https://arxiv.org/pdf/1410.1231v1.pdf
第三类为各种论文以及文章提供有力的数据支撑。
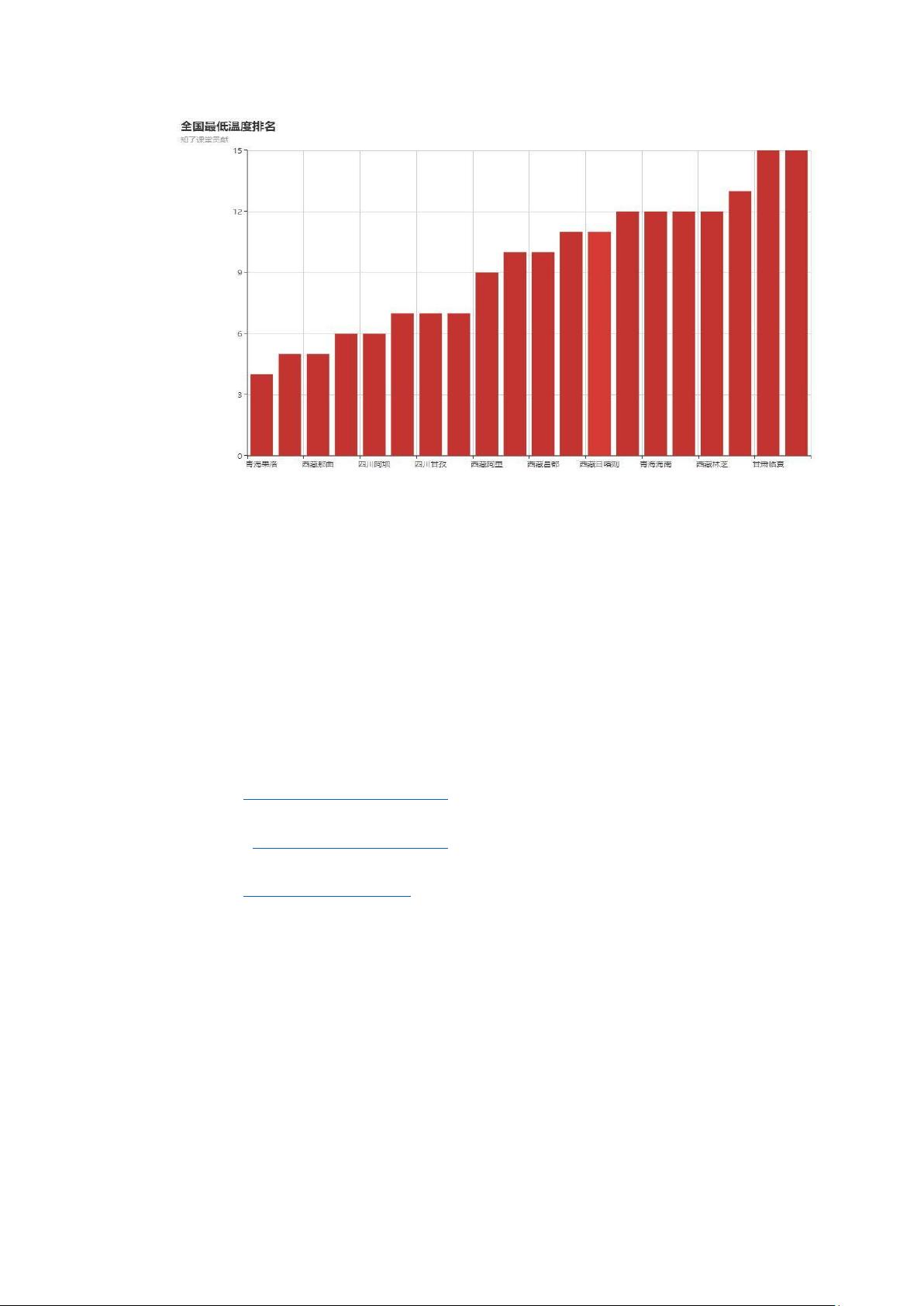
比如,我们要找出全国气温最低的地方并直观的表示出来,那么我们仅仅需要
爬取一下全国的气象信息,然后通过类似于 D3.js 这种可视化 JavaScript 库就可以
得到一张柱状图.如下图所示,这样,全国最低气温就能直观的显示出来。同时
也可以用过各种气象论文中论点的有力支撑.

剩余64页未读,继续阅读
2022-08-08 上传
2022-08-03 上传
2013-05-11 上传
2022-08-08 上传
2021-09-17 上传
2012-02-16 上传
2011-09-17 上传
2021-09-18 上传

空城大大叔
- 粉丝: 30
- 资源: 313
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索数据转换实验平台在设备装置中的应用
- 使用git-log-to-tikz.py将Git日志转换为TIKZ图形
- 小栗子源码2.9.3版本发布
- 使用Tinder-Hack-Client实现Tinder API交互
- Android Studio新模板:个性化Material Design导航抽屉
- React API分页模块:数据获取与页面管理
- C语言实现顺序表的动态分配方法
- 光催化分解水产氢固溶体催化剂制备技术揭秘
- VS2013环境下tinyxml库的32位与64位编译指南
- 网易云歌词情感分析系统实现与架构
- React应用展示GitHub用户详细信息及项目分析
- LayUI2.1.6帮助文档API功能详解
- 全栈开发实现的chatgpt应用可打包小程序/H5/App
- C++实现顺序表的动态内存分配技术
- Java制作水果格斗游戏:策略与随机性的结合
- 基于若依框架的后台管理系统开发实例解析
