CentOS 6.3上编译安装Hadoop-2.2.0详细教程
需积分: 10 7 浏览量
更新于2024-09-11
收藏 475KB DOC 举报
"本文档详细介绍了在 CentOS 6.3 64位系统上编译安装 Hadoop-2.2.0 的过程,包括环境配置、用户创建、主机名与IP地址设置、SSH无密码登录的实现以及Java的安装。"
在开始Hadoop的编译安装之前,首先需要确保有一个合适的运行环境。在这个案例中,我们有三台运行 CentOS 6.3 64位的服务器,分别为Master、Slave1和Slave2,它们的IP地址分别是192.168.80.90、192.168.90.91和192.168.80.92。为了进行集群部署,所有节点都需要进行相同的配置步骤。
第一步,设置每台服务器的IP地址和主机名。在`/etc/sysconfig/network-scripts/ifcfg-eth0`文件中编辑网络接口配置,并在`/etc/sysconfig/network`中修改主机名。完成这两项修改后,需要重启服务器使更改生效。
第二步,创建名为'hadoop'的用户,这将在所有节点上执行,以便于管理和运行Hadoop服务。通过`useradd hadoop`命令来创建新用户。
第三步,添加hosts记录,将每台服务器的IP和主机名对应关系写入`/etc/hosts`文件,这样可以避免因DNS解析带来的延迟,提高集群通信效率。
第四步,建立Hadoop用户之间的信任关系,即实现SSH无密码登录。在hadoop用户下使用`ssh-keygen -t rsa`生成密钥对,并将公钥复制到其他节点的`.ssh/authorized_keys`文件中,确保文件权限为600。
第五步,安装Java环境,这是运行Hadoop的必要条件。可以从Oracle官网下载JDK,解压并设置环境变量。在`/etc/profile`文件中添加`JAVA_HOME`、`CLASSPATH`和`PATH`,然后使用`source /etc/profile`命令使更改生效。确保在root和hadoop用户下都执行此步骤,以便所有用户都能访问Java环境。
在完成了这些基础配置后,接下来可以进行Hadoop的编译和安装:
1. 解压Hadoop源码包,例如:`tar -xvf Hadoop-2.2.0-src.tar.gz`
2. 进入源码目录,配置编译选项,如:`./configure --prefix=/usr/local/hadoop`
3. 编译源码:`make`
4. 安装到指定目录:`make install`
最后,配置Hadoop的配置文件(如`hdfs-site.xml`、`core-site.xml`、`mapred-site.xml`等),启动Hadoop服务,并进行必要的测试,如`hadoop fs -ls`,以验证安装是否成功。
安装Hadoop需要对操作系统环境进行一系列的预处理,包括网络配置、用户管理、SSH设置以及Java环境的安装。在完成这些准备工作后,才能进行Hadoop的编译和安装,确保其能够在多节点集群上稳定运行。
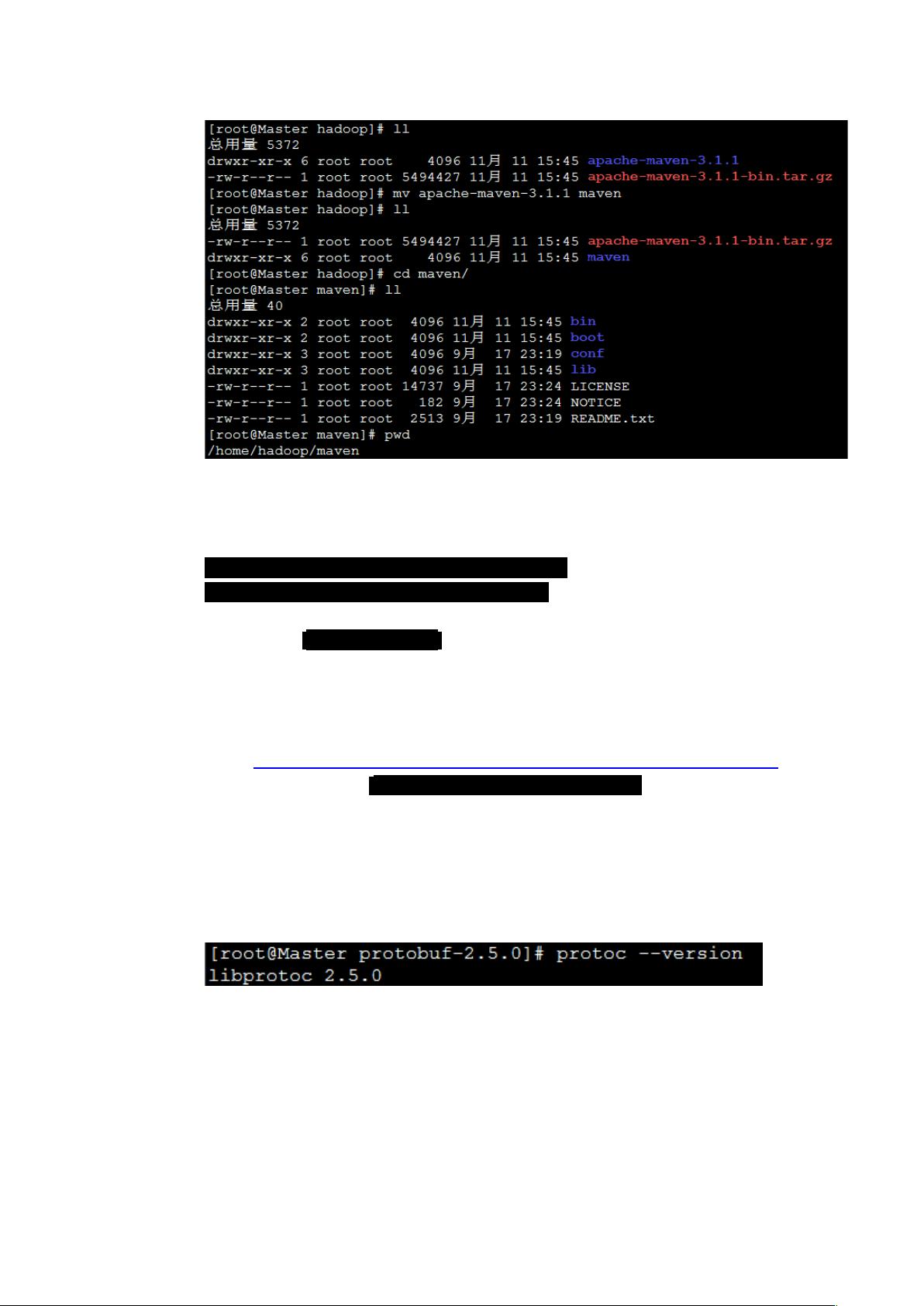
注意一下 maven 存放路径,可以自定义路径
添加变量:以 root 用户 vi /etc/profile
根据自己路径在最后添加以下两行
export MAVEN_HOME=/home/hadoop/maven
export PATH=$PATH:$MAVEN_HOME/bin
添加之后执行 sourc /etc/profile 重新加载
1.9 安装 protobuf(不安装,编译将无法完成)
下载:http://code.google.com/p/protobuf/downloads/detail?name=protobuf-2.5.0.tar.gz
解压,设置属主为 root chowd -R root.root protobuf-2.5.0
编译安装 protobuf
1 cd protobuf-2.5.0
2 ./configure
3 make
4 make install
检测 protoc --version
二,编译安装 hadoop-2.2.0
2.1 下载 hadoop-2.2.0-src.tat.gz
落叶 2013.11.13
剩余13页未读,继续阅读
2015-03-19 上传
2014-06-30 上传
点击了解资源详情
点击了解资源详情
115 浏览量
点击了解资源详情
2016-05-07 上传
155 浏览量
234 浏览量

slimina
- 粉丝: 423
 我的内容管理
展开
我的内容管理
展开







最新资源
- 网页自动刷新工具 v1.1 - 自定义时间间隔与关机
- pt-1.4协程源码深度解析
- EP4CE6E22C8芯片三相正弦波发生器设计与实现
- 高效处理超大XML文件的查看工具介绍
- 64K极限挑战:国际程序设计大赛优秀3D作品展
- ENVI软件全面应用教程指南
- 学生档案管理系统设计与开发
- 网络伪书:社区驱动的在线音乐制图平台
- Lettuce 5.0.3中文API文档完整包下载指南
- 雅虎通Yahoo! Messenger v0.8.115即时聊天功能详解
- 将Android手机转变为IP监控摄像机
- PLSQL入门教程:变量声明与程序交互
- 掌握.NET三层架构:实例学习与源码解析
- WPF中Devexpress GridControl分组功能实例分析
- H3Viewer: VS2010专用高效帮助文档查看工具
- STM32CubeMX LED与按键初始化及外部中断处理教程
