Flink集群部署:Standalone与Yarn模式
需积分: 0 21 浏览量
更新于2024-08-05
收藏 823KB PDF 举报
"Flink集群的部署方法主要包括Standalone模式和Yarn模式,这两种模式各有特点,适用于不同的场景。在Standalone模式中,我们主要关注如何配置和启动Flink集群,而在Yarn模式下,Flink任务与Hadoop的集成成为重点。"
在【Flink篇02】中,我们首先讨论了Flink Standalone模式的部署步骤:
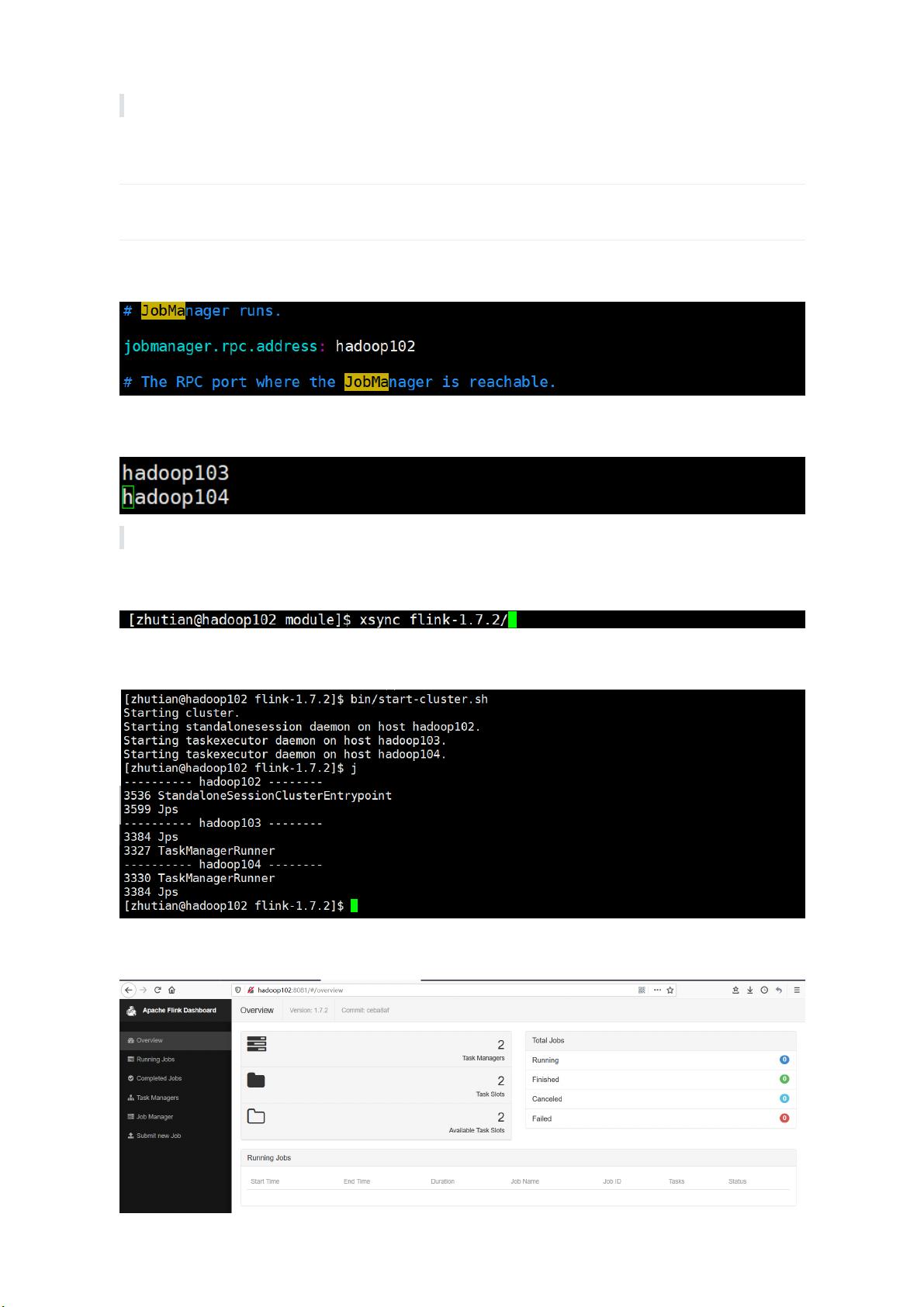
1. **修改配置文件**:在部署Flink集群时,首要任务是修改`flink-conf.yaml`配置文件。这个文件位于`flink/conf/`目录下,包含了Flink集群运行所需的各种参数,如job manager和task manager的内存设置、网络设置等。根据实际的硬件和需求进行调整。
2. **配置Slaves文件**:`slaves`文件列出了集群中作为TaskManager节点的主机名或IP地址。Flink的master/slaves机制即将被废弃,因此需要了解最新的配置方式。
3. **分发和启动**:将配置好的Flink目录分发到所有参与集群的机器上,并在每台机器上启动Flink服务。这通常通过SSH或类似的工具实现。
4. **访问Web界面**:启动后,可以通过浏览器访问Flink的Web界面来监控集群状态和任务执行情况,默认端口是8081。
5. **任务提交**:可以将准备好的数据文件分发到各TaskManager节点,然后通过Web界面或者命令行工具提交Flink作业。
接下来,我们转向Yarn模式的Flink部署:
1. **环境要求**:为了在Yarn上运行Flink,需要确保Flink版本兼容Hadoop 2.2以上,并且Hadoop集群已经安装了HDFS服务。
2. **Session-Cluster模式**:在这种模式下,Flink集群会在Yarn上预先启动,资源分配一旦确定就不会改变。所有作业共享Dispatcher和ResourceManager,适用于小型、短生命周期的作业。当资源不足时,新作业必须等待已有作业完成才能提交。
3. **Per-Job-Cluster模式**:每个作业都会启动自己的Flink集群,按需申请资源,执行完毕后集群自动关闭。这种方式适合大型、长期运行的作业,因为作业之间互不影响,易于管理和故障隔离。
在Yarn中部署Flink,例如SessionCluster模式,需要启动Hadoop集群,然后通过特定命令提交Flink作业,作业的执行和资源管理由Yarn负责。
总结来说,Flink的部署涉及到多个层面,包括配置文件的定制、集群资源的分配以及作业的提交方式。选择合适的部署模式对优化资源利用和任务管理至关重要。Standalone模式适合小型试验环境,而Yarn模式则提供了更高效和灵活的资源调度,适应大规模生产环境的需求。
下载后可阅读完整内容,剩余4页未读,立即下载
2021-10-12 上传
2021-01-27 上传
2022-08-04 上传
2021-10-03 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-05-24 上传

小崔个人精进录
- 粉丝: 39
- 资源: 316
 我的内容管理
展开
我的内容管理
展开







最新资源
- not-so-simple
- hostFolder
- hackernews-clone:Hackernews使用React,GraphQL,Prisma和Postgres进行克隆
- fastapi-celery-example
- 虚幻4自由视角镜头 Camera.7z
- usersList
- Social-iNet:具有boostrap 4和javascript的简单SPA
- Java垃圾收集必备手册.rar
- CareerPath:个人研究的此回购角色有关开发职业或其他任何问题的提示
- TotalControl:一款带手控的安卓游戏
- JavaAssessments
- Proyecto-Hotel:Proyecto#1(酒店)
- collection_exercises
- 【WordPress插件】2022年最新版完整功能demo+插件14 Mar.zip
- sequelize-search-builder:极简库,用于解析搜索请求以序列化查询
- Actions:作证行动
