Python爬虫实战:解析并获取马云微博全记录
需积分: 0 153 浏览量
更新于2024-09-01
收藏 245KB PDF 举报
"Python爬取马云微博功能的实现方法与步骤"
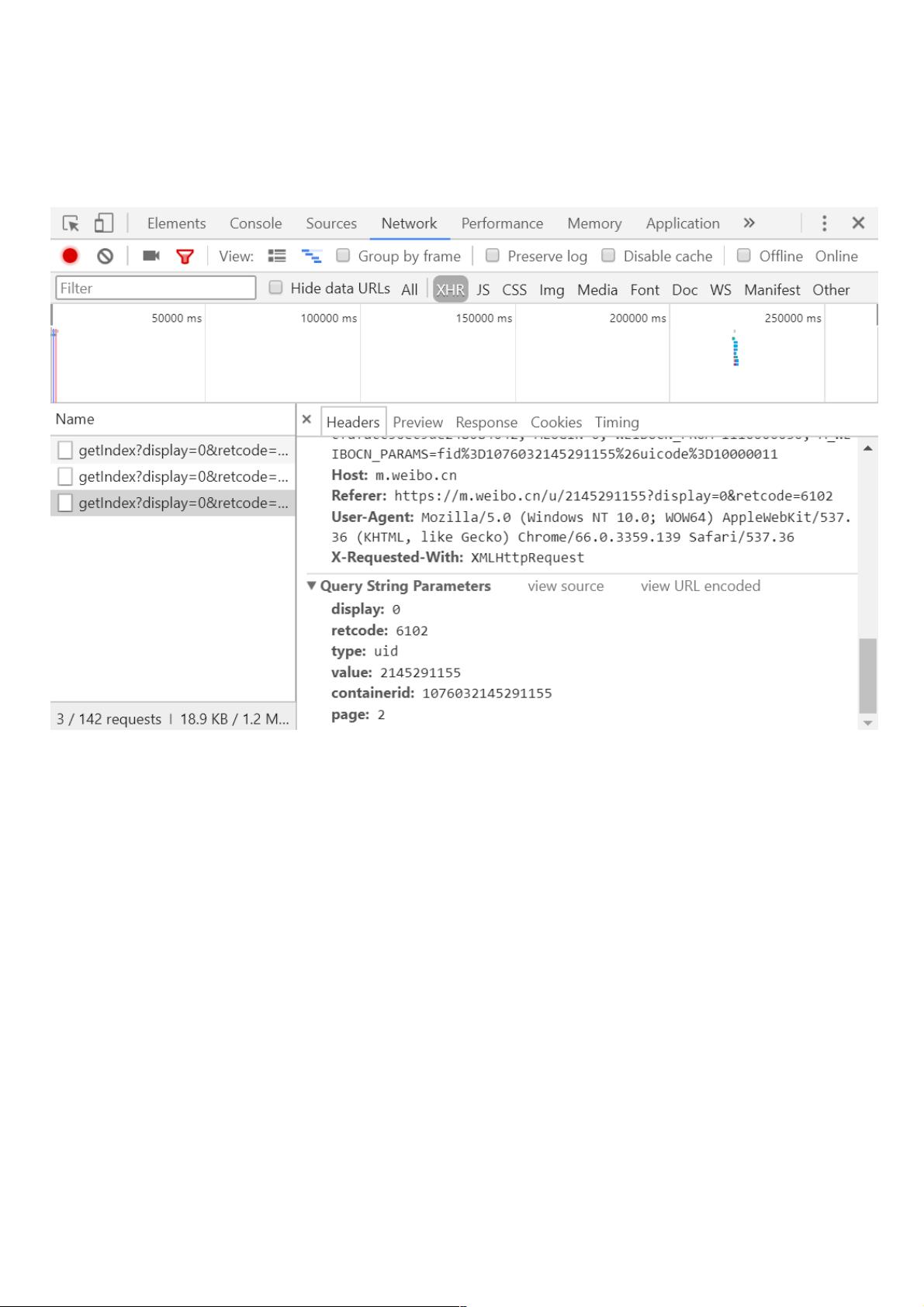
在Python中实现爬取马云的微博功能,主要涉及到网络请求、数据解析以及网页动态加载的理解。首先,我们需要分析微博网页的请求机制。在Chrome浏览器中开启Ajax的XHR过滤器,通过观察页面滚动时的网络请求,可以发现页面加载新内容时会发送GET请求。这些请求通常包含几个固定参数,如display、retcode、type、value、containerid和page,其中page参数是用于控制分页的关键。
接下来,我们需要分析响应内容。这些请求返回的是Json格式的数据,浏览器开发者工具会自动将其解析。Json数据中有两个关键部分:cardlistInfo和cards。cardlistInfo中的`total`字段表示微博总数,可以据此计算出需要的分页数。而cards则包含了每条微博的具体信息,如点赞(attitudes_count)、评论(comments_count)、转发(reposts_count)数量,发布时间(created_at)以及微博文本(text)等。
为了实现爬虫,我们需要模拟这些Ajax请求。在Python中,我们可以使用`requests`库发起HTTP请求,并使用`urllib.parse.urlencode`来处理请求参数。代码示例中,定义了一个方法来获取特定页码的微博数据,方法接收page参数,设置基础URL和必要的HTTP头部信息,如Host、Referer和User-Agent,以模拟浏览器行为。
完整的爬取过程可以使用一个循环,每次迭代增加page值,直到获取到的微博总数达到之前分析到的`total`值。在获取到响应内容后,可以使用`json.loads()`函数将Json字符串转换为Python字典,然后利用PyQuery或BeautifulSoup等库解析并提取所需数据。
需要注意的是,实际爬取过程中还需要考虑反爬策略,可能需要设置延迟或者使用代理IP,以及处理可能出现的验证码或登录验证。同时,应尊重网站的robots.txt规则,避免对服务器造成过大负担。在处理数据时,也要注意字符编码问题,确保正确解析中文内容。
Python实现爬取马云微博的功能涉及到网络请求库的使用、Json数据解析、网页动态加载的分析以及网页内容的提取。通过理解这些基本步骤,可以扩展到其他类似网站的爬取任务。
Python实现爬取马云的微博功能示例实现爬取马云的微博功能示例
本文实例讲述了Python实现爬取马云的微博功能。分享给大家供大家参考,具体如下:
分析请求分析请求
我们打开 Ajax 的 XHR 过滤器,然后一直滑动页面加载新的微博内容,可以看到会不断有Ajax请求发出。
我们选定其中一个请求来分析一下它的参数信息,点击该请求进入详情页面,如图所示:
可以发现这是一个 GET 请求,请求的参数有 6 个:display、retcode、type、value、containerid 和 page,观察这些请求可以发现只有 page
在变化,很明显 page 是用来控制分页的。
分析响应分析响应
如图所示:
下载后可阅读完整内容,剩余3页未读,立即下载
2019-08-10 上传
2017-09-15 上传
2021-10-02 上传
2023-09-27 上传
2023-06-10 上传
2023-09-27 上传
2023-11-11 上传
2023-06-03 上传
2023-09-14 上传

weixin_38656064
- 粉丝: 10
- 资源: 932
 我的内容管理
展开
我的内容管理
展开







最新资源
- 人工智能量化交易.zip
- CTS
- Guzzle,一个可扩展PHP HTTP客户端-PHP开发
- Whale-crx插件
- Gmail.zip_Email客户端_Visual_Basic_
- torch_scatter-2.0.8-cp39-cp39-linux_x86_64whl.zip
- ld42-pop-mayhem:爆米花混乱游戏
- 人工智能实践--tensorflow笔记(北大曹健).zip
- 你好,世界
- CSharp3.rar_网络编程_Visual_C++_
- matlab拟合差值代码-RTsurvival:一组R函数可对React时间(RT)数据进行生存分析
- 基于java gui的超市管理系统
- Deep-Learning-Regression-with-Admissions-Data:数据集来自kaggle,即研究生入学2,该方法使用神经网络对其进行分析。
- 人工智能导论课 期末设计 - 基于遗传算法的图像分割.zip
- Thermal_monitor
- matlab人脸检测框脸代码-FaceGenderAgeEmotionDetection:FaceGenderAgeEmotionDetect
