Apache Spark入门与核心功能详解
需积分: 9 119 浏览量
更新于2024-07-20
收藏 18.1MB PDF 举报
Apache Spark是一个强大的开源分布式计算框架,它在大数据处理领域中扮演着核心角色。本指南将深入探讨Mastering Apache Spark的主要知识点,包括其概述、Spark SQL、SparkSession的创建、数据处理和操作、以及高级特性的使用。
1. **概述**
Apache Spark 提供了一种内存计算模型,能够支持实时流处理和批处理,以高效的速度进行复杂的数据分析。它的设计理念是将计算任务分布在集群中的节点上,以并行方式执行,从而提高性能。
2. **Spark SQL**
Spark SQL 是Spark的一个关键组件,它允许用户在大规模数据集上执行结构化查询。它提供了DataFrame API,使数据处理更像SQL,支持标准的SQL语法,以及与关系型数据库的交互。
3. **SparkSession** 和 **Builder**
SparkSession是Spark编程的入口点,它封装了所有主要的Spark功能。Builder模式允许通过简洁的API构建自定义的SparkSession,以适应不同的应用场景。
4. **Datasets和DataFrames**
Datasets是Spark的数据抽象,它们是强类型版本的DataFrame,提供更好的类型安全性和优化。DataFrame是列式存储的二维表格,由Row对象组成,RowEncoder用于将数据转换为内部表示。
5. **Schema和Data Types**
Schema定义了DataFrame或Dataset的数据结构,包括字段名称、类型和约束。StructType和StructField用于表示复杂的结构,而DataTypes则提供了各种内置数据类型。
6. **DataFrame Operators和Column Operators**
DataFrame提供了丰富的操作符,如选择(ColumnOperators)、过滤(Selection)、聚合(Aggregation)和连接(Joins)。StandardFunctions提供了内置函数库,用于数据转换和处理。
7. **窗口操作和用户定义函数 (UDFs)**
WindowAggregateOperators支持窗口函数,用于分组统计分析,而UDFs允许开发者编写自定义操作来扩展Spark的功能。
8. **Caching**
Caching功能可以缓存中间结果,避免重复计算,提高性能。这对于大规模数据分析尤为重要。
9. **DataSource API**
DataSource API是Spark用于加载和保存数据的标准接口。DataFrameReader用于读取外部数据源,DataFrameWriter负责数据写入。
10. **高级特性**
- 数据源支持广泛,包括文件系统、数据库、流等。
- Spark的分布式计算能力和容错机制确保任务的可靠执行。
- 2.8.3.1至2.8.5.3部分详细介绍了更复杂的主题,如数据分区、动态分区和数据流处理。
11. **其他内容**
- 2.9可能涉及分布式计算和资源管理,2.10可能涵盖了性能调优、性能监控和最佳实践等内容。
Mastering Apache Spark指南涵盖了从基础概念到高级特性的全面知识,旨在帮助开发者熟练掌握Spark框架,以高效地处理和分析大规模数据。
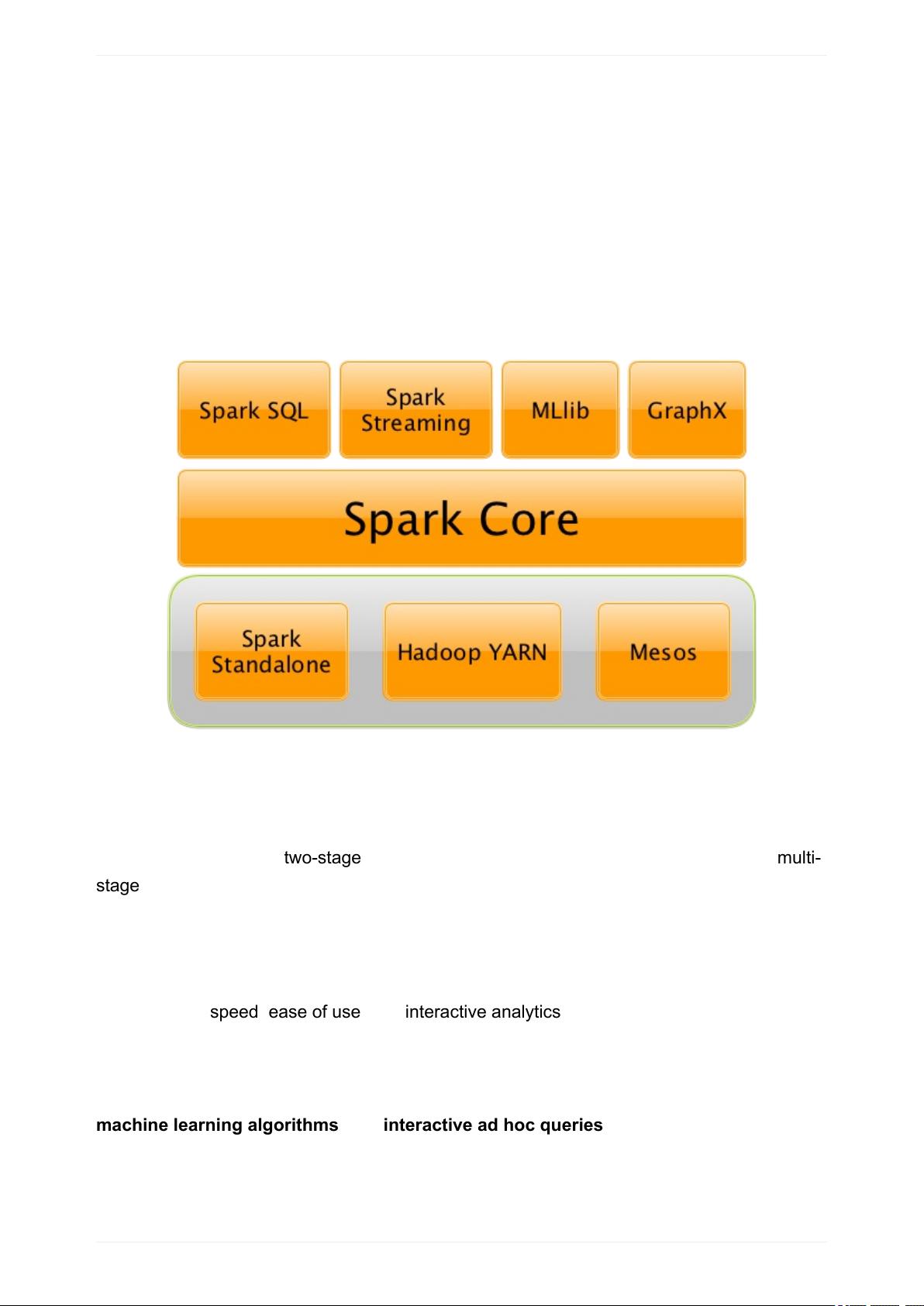
ApacheSpark
ApacheSparkisanopen-sourcedistributedgeneral-purposeclustercomputing
frameworkwithin-memorydataprocessingenginethatcandoETL,analytics,machine
learningandgraphprocessingonlargevolumesofdataatrest(batchprocessing)orin
motion(streamingprocessing)withrichconcisehigh-levelAPIsfortheprogramming
languages:Scala,Python,Java,R,andSQL.
Figure1.TheSparkPlatform
YoucouldalsodescribeSparkasadistributed,dataprocessingengineforbatchand
streamingmodesfeaturingSQLqueries,graphprocessing,andMachineLearning.
IncontrasttoHadoop’stwo-stagedisk-basedMapReduceprocessingengine,Spark’smulti-
stagein-memorycomputingengineallowsforrunningmostcomputationsinmemory,and
henceveryoftenprovidesbetterperformance(therearereportsaboutbeingupto100times
faster-readSparkofficiallysetsanewrecordinlarge-scalesorting!)forcertainapplications,
e.g.iterativealgorithmsorinteractivedatamining.
Sparkaimsatspeed,easeofuse,andinteractiveanalytics.
Sparkisoftencalledclustercomputingengineorsimplyexecutionengine.
Sparkisadistributedplatformforexecutingcomplexmulti-stageapplications,like
machinelearningalgorithms,andinteractiveadhocqueries.Sparkprovidesanefficient
abstractionforin-memoryclustercomputingcalledResilientDistributedDataset.
OverviewofApacheSpark
16




剩余1285页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2018-04-03 上传
2018-12-25 上传
2017-01-14 上传
2018-03-24 上传
2015-10-29 上传

PyQter
- 粉丝: 14
- 资源: 39
 我的内容管理
展开
我的内容管理
展开







最新资源
- iBATIS-SqlMaps-2_cn.pdf
- C___Builder_5_开发人员指南
- C___Builder_5_开发人员指南
- C___Builder_5_开发人员指南
- IShort.pdf
- C___Builder_5_开发人员指南
- C___Builder_5_开发人员指南
- C___Builder_5_开发人员指南
- C___Builder_5_开发人员指南
- C___Builder_5_开发人员指南
- C___Builder_5_开发人员指南
- C___Builder_5_开发人员指南
- C___Builder_5_开发人员指南
- C___Builder_5_开发人员指南
- 五子棋 课程设计 c语言
- unix基础教程(很好,很基础)
