Adaboost算法详解与证明
"这篇内容主要介绍了Adaboost算法的工作流程及其数学证明,旨在帮助理解Adaboost算法如何通过集成多个弱分类器构建强分类器。"
Adaboost(Adaptive Boosting)是一种集成学习方法,它通过迭代地训练一系列弱分类器并将它们组合成一个强分类器来提高分类性能。在每一轮迭代中,Adaboost会调整训练数据的权重,使得那些被前一轮分类器错误分类的样本在下一轮中得到更多的关注。
1. **算法开始**:
- **训练集**:给定一个带标签的训练集,其中每个样本有一个正确的类别标签。
- **初始权重分布**:所有样本的初始权重相等,即每个样本都有相同的影响力。
2. **弱分类器的训练**:
- 对于每个特征,计算一个阈值和方向,以最小化误分类的样本数量。
- 构建弱分类器(如决策树的单个节点),选择具有最小错误率的特征作为弱分类器。
3. **权重更新**:
- 根据弱分类器的表现更新样本权重,错误分类的样本权重增加,正确分类的样本权重减少。
- 更新公式:[pic],其中αt是弱分类器ht的权重,η是学习率,错误率εt是ht的误分类比例。
4. **强分类器构建**:
- 经过T轮迭代,获得T个弱分类器,构成强分类器H。
- 强分类器的组合形式:[pic],其中每一个ht代表一个弱分类器。
5. **错误率分析**:
- 求强分类器的总错误率,目标是使其尽可能小。
- 弱分类器的错误率越小或越大,都能使得错误率快速下降,因为它们能够有效地识别正例和反例。
6. **找到最优弱分类器**:
- 使用决策树(如ID3、C4.5、C5.0)生成弱分类器,通过信息增益、增益比或基尼指数等度量选择最佳分割点。
- 可通过修剪策略(如规则修剪)优化决策树结构,减少过拟合。
7. **优化过程**:
- 通过数学推导,可以得出调整权重的过程实际上是寻找错误率最小的弱分类器。
- 利用导数求解,找到使总错误率下降最快的αt值。
8. **最终结果**:
- 经过T轮迭代后,组合得到的强分类器H的总错误率远低于单个弱分类器。
总结来说,Adaboost算法通过迭代和权重调整,让每次迭代都聚焦于前一轮分类错误的样本,从而构建一个对训练数据有高分类能力的强分类器。这一过程不仅依赖于弱分类器本身的性能,更依赖于如何选择和组合这些弱分类器。
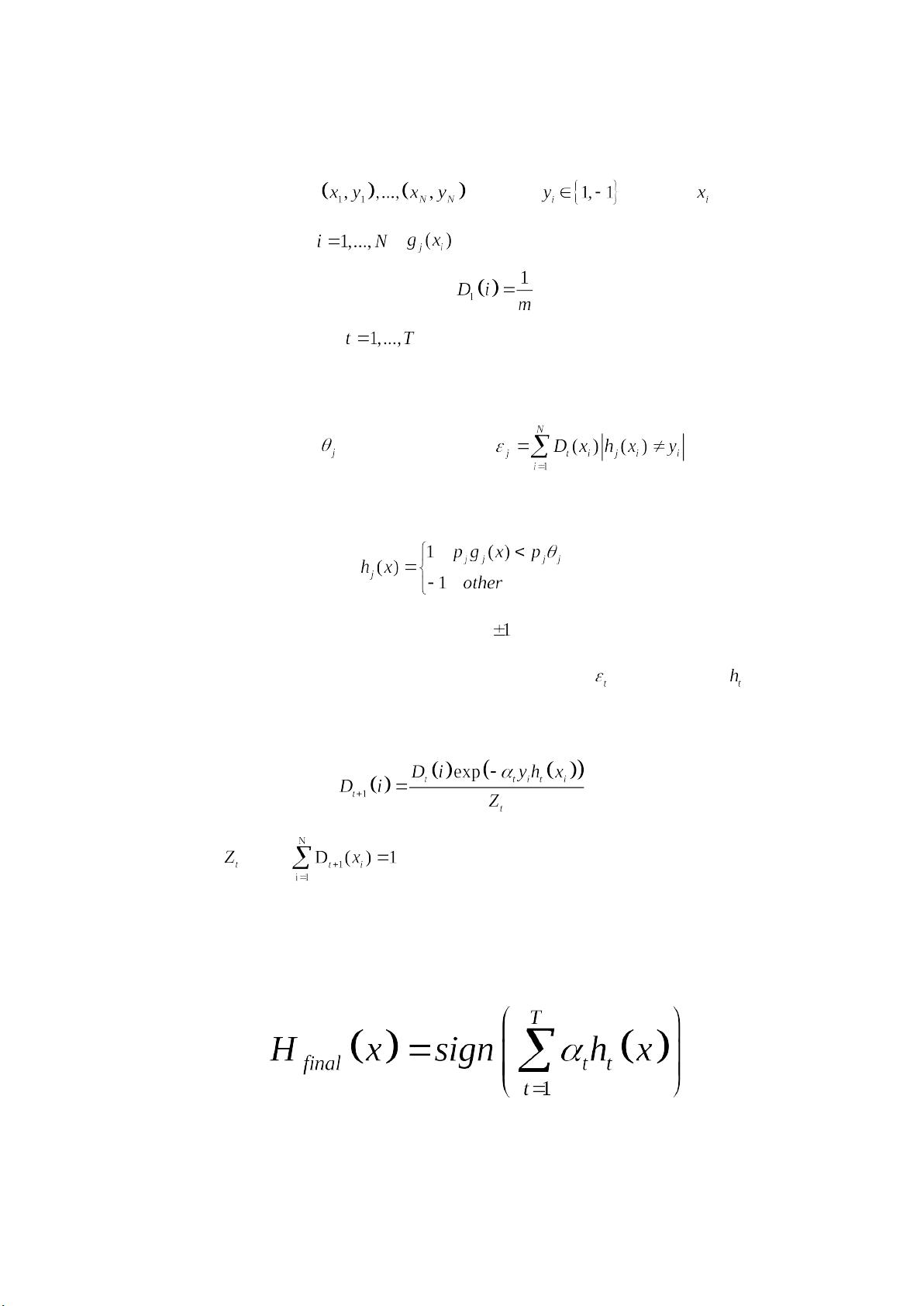
Discete-AdaBoost 算法
1、给定训练集: ,其中 ,表示 的正确
的类别标签, , 表示第 i 副图像的第 j 个特征值
2、训练集上样本的初始分布:
3、寻找若分类器 ht( )
(1)对于每个样本中的第 j 个特征,可以得到一个若分类器 hj,
即可得到阈值 和方向 Pj,使得 达到最小,
而弱分类器 hj 为:
其中 Pj 决定不等式的方向, 只有 两种情况。
4、将所有特征(j)中挑选出一个具有最小误差 的弱分类器 。
5、对所有的样本权重进行更新
其中 是使 得归一化因子。
6、经过 T 轮训练得到 T 个最优的弱分类器,此时组成一个强分
类器;
下载后可阅读完整内容,剩余4页未读,立即下载
2014-09-07 上传
2011-10-17 上传
2010-08-31 上传
2021-10-06 上传
点击了解资源详情

tyt184793441
- 粉丝: 2
- 资源: 15
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
