理解AdaBoost算法:从基础到证明
"AdaBoost算法是一种集成学习方法,通过组合多个弱分类器形成一个强分类器。该算法的核心思想是迭代地调整样本权重,让每次训练的弱分类器更关注那些之前被错误分类的样本。"
AdaBoost算法的流程如下:
1. **初始化样本权重**:在开始时,所有样本的权重相等,即每个样本的权重 [pic] 初始化为 [pic]。
2. **训练弱分类器**:在每一轮迭代中,针对当前的样本权重分布,训练一个弱分类器 [pic]。弱分类器的选择目标是最小化错误率,通常是一个二分类器,如决策树。弱分类器 [pic] 可以根据特征 [pic] 和阈值 [pic] 来定义,其中 [pic] 决定分类的边界方向。
3. **选择最优弱分类器**:在所有可能的弱分类器中,选取误差率 [pic] 最小的那一个作为这一轮的最优弱分类器。
4. **更新样本权重**:根据弱分类器的性能调整样本权重,错误分类的样本权重增加,正确分类的样本权重减小。权重更新公式为 [pic],其中 [pic] 是调整因子,[pic] 是归一化因子。
5. **计算调整因子** [pic]:调整因子通过优化误差率 [pic] 来确定,使得强分类器的总误差率快速下降。[pic] 为归一化因子,通过求解 [pic] 的最小值来确定。
6. **构建强分类器**:经过 T 轮迭代后,将所有弱分类器组合成一个强分类器,强分类器的输出是各弱分类器输出的加权和,即 [pic],其中 [pic] 是第 t 轮的弱分类器。
弱学习阶段,目标是找到错误率接近于 [pic] 的弱分类器。如果所有弱分类器的错误率都在 [pic] 的范围内,那么强分类器的总错误率可以通过组合这些弱分类器得到。
AdaBoost 算法中的关键在于,即使弱分类器错误率较大或较小,都能通过调整权重使其对最终分类的贡献减小,从而降低整体错误率。这可以通过分析 [pic] 关于 [pic] 的曲线图来理解,当错误率远离中间值时,算法会快速收敛。
为了寻找最优的弱分类器,通常会采用决策树算法,如 ID3、C4.5 和 C5.0。ID3 使用信息增益作为特征选择标准,C4.5 引入了增益比以减少偏重于取值多的特征,C5.0 则使用基尼指数,并且在生成树和修剪树的过程中有进一步的改进。
总结来说,AdaBoost 算法通过迭代地训练和组合弱分类器,不断调整权重,使得最终的强分类器能够有效地降低训练集上的错误率,从而提升模型的整体预测能力。
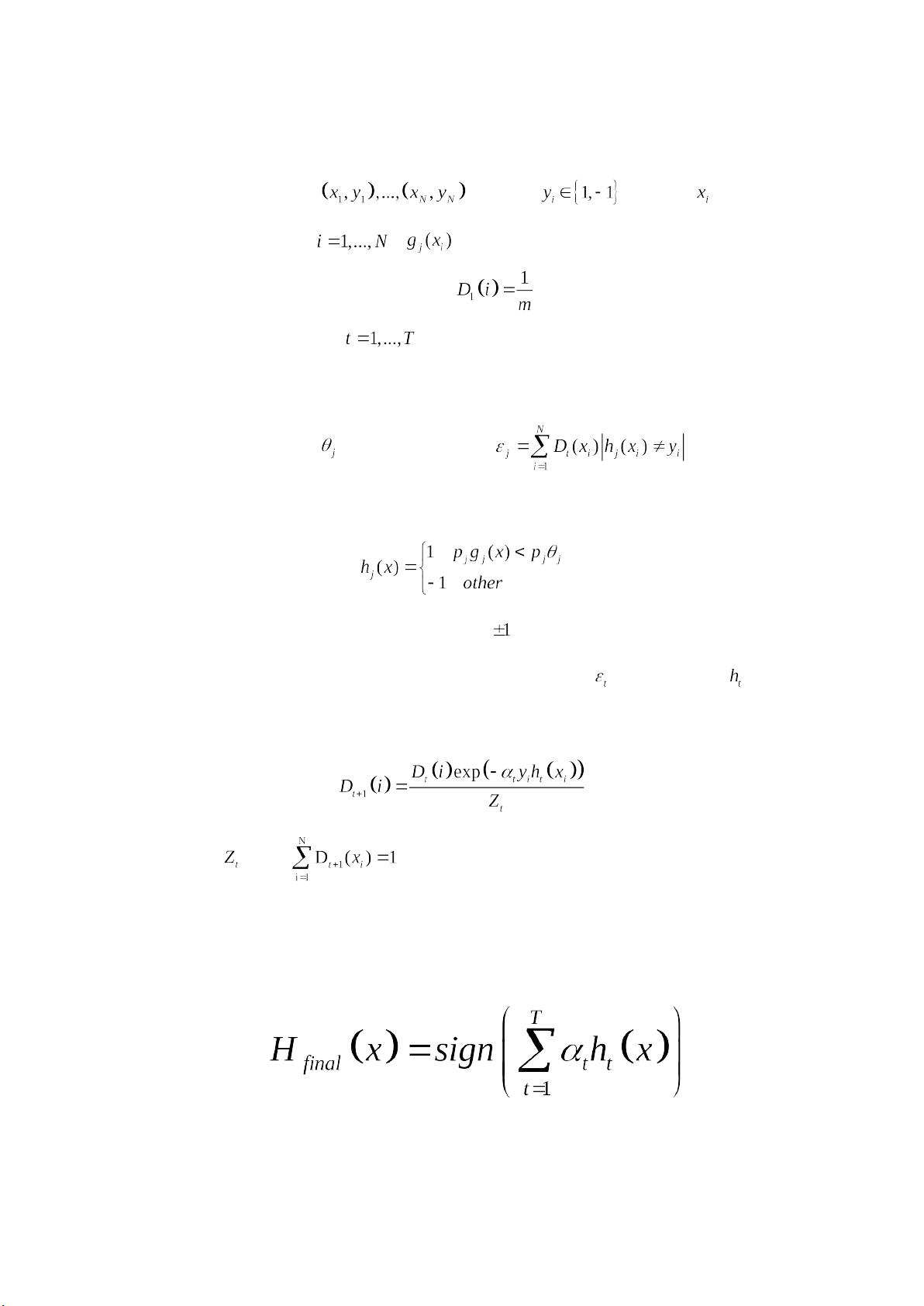
Discete-AdaBoost 算法
1、给定训练集: ,其中 ,表示 的正确
的类别标签, , 表示第 i 副图像的第 j 个特征值
2、训练集上样本的初始分布:
3、寻找若分类器 ht( )
(1)对于每个样本中的第 j 个特征,可以得到一个若分类器 hj,
即可得到阈值 和方向 Pj,使得 达到最小,
而弱分类器 hj 为:
其中 Pj 决定不等式的方向, 只有 两种情况。
4、将所有特征(j)中挑选出一个具有最小误差 的弱分类器 。
5、对所有的样本权重进行更新
其中 是使 得归一化因子。
6、经过 T 轮训练得到 T 个最优的弱分类器,此时组成一个强分
类器;
下载后可阅读完整内容,剩余4页未读,立即下载
691 浏览量
114 浏览量
122 浏览量
193 浏览量
2021-10-06 上传
237 浏览量
点击了解资源详情
点击了解资源详情

newtonjjn
- 粉丝: 1
- 资源: 10
 我的内容管理
展开
我的内容管理
展开







最新资源
- Object Oriented Analysis and Design ——Understanding System Development with UML 2.0
- 数据结构, 浙大的PPT哦,很值得一看, 不过是基础篇
- 软件工程实验指导书(包括两个实验)
- Linux系统指令大全.pdf
- javaScript+验证总结
- Java数据结构 线性表,链表,哈希表是常用的数据结构
- DDR2 SDRAM 操作时序规范 中文版
- A Beginner’s Introduction to Computer Programming
- 索引Index的优化设计
- 软件建模技术教程样节_3.2类.pdf
- 国防科技大学TSM(成功sql,db2,oracle)
- 微软Word_vba范例源代码
- 3G技术普及手册(华为内部版)
- AVS视频标准研究 pdf
- Autonomy白皮书
- Oracle 面试 22种问题
