有赞大数据实践:构建敏捷型数据仓库的关键与挑战
84 浏览量
更新于2024-08-28
收藏 1.09MB PDF 举报
"有赞大数据实践:敏捷型数据仓库的构建及其应用"
在互联网时代,精细化运营成为企业关注的焦点,而实现这一目标的关键在于构建高效、灵活的数据仓库。本资源探讨了有赞在构建敏捷型数据仓库过程中面临的挑战以及解决方案。
首先,数据仓库需要在海量数据的基础上提供高效的明细数据服务,满足不同层级的分析需求。这要求数据仓库具备强大的数据处理能力,并能够快速响应变化。为了达到这一目标,通常采用ETL(Extract, Transform, Load)流程,将原始数据抽取、转换并加载到数据仓库中。然而,来自不同部门和目的的数据请求可能导致数据口径不一致,因此,确保数据口径的一致性和数据含义的清晰性至关重要。这需要建立严格的数据治理机制,包括统一的数据标准和规范,以及数据质量的监控与校验。
其次,数据仓库的设计应考虑数据路径的可追溯性。这涉及到对数据生命周期的管理,从数据的源头到最终用户,每一个环节都需要有明确的记录,以便于追踪数据问题和进行审计。这可以通过元数据管理实现,记录数据的来源、处理过程及使用情况。
在技术架构层面,大数据平台成为互联网公司处理海量数据的核心。例如,有赞的大数据平台每天处理大量店铺、商品更新和用户日志数据,这些数据通过消息队列汇总到数据仓库。数据仓库的横向扩展能力和迭代计算能力使得它能有效支持业务和技术部门的数据需求,提供直接或间接的数据服务。
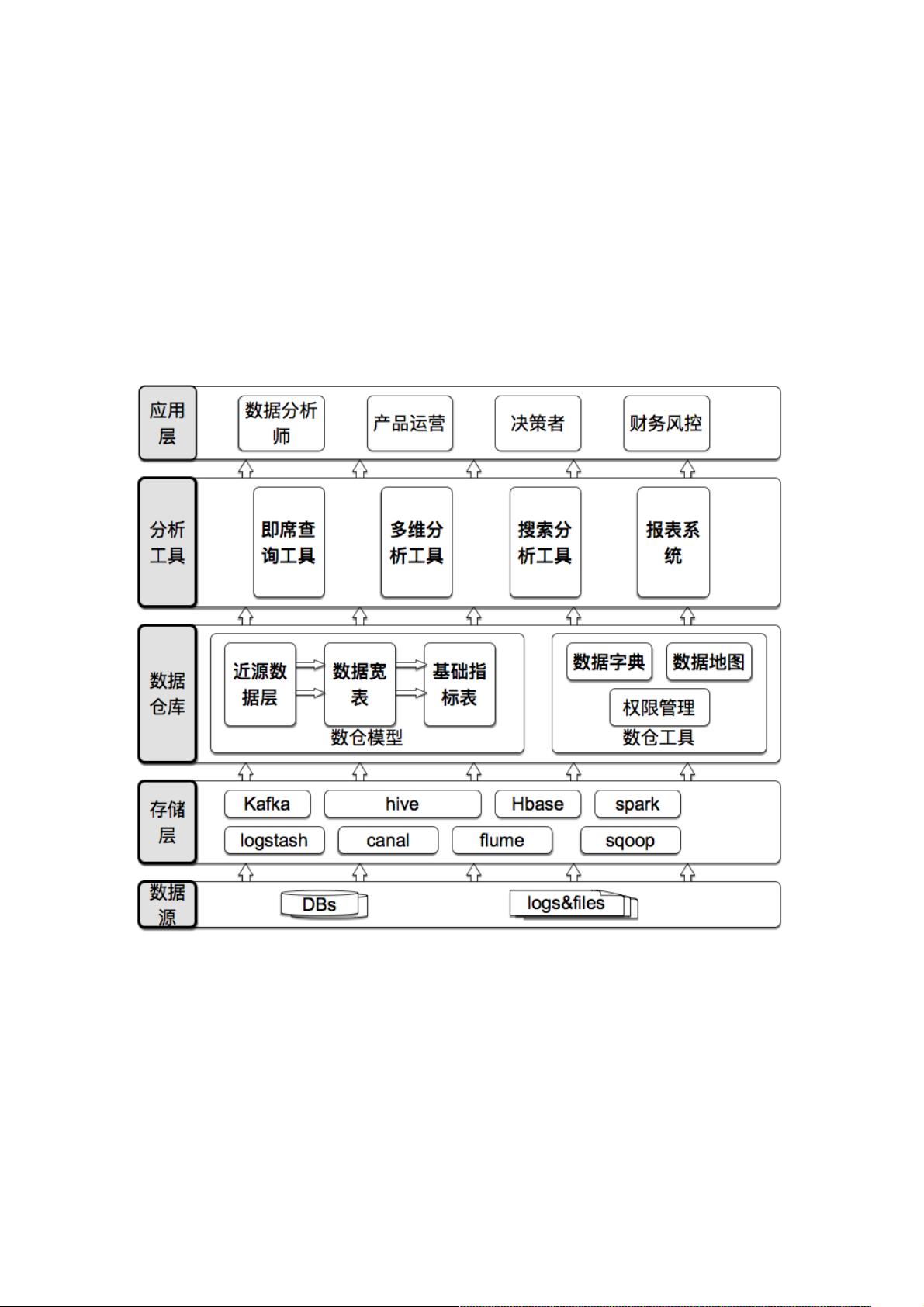
在数据仓库设计上,分为存储层、数据仓库层和数据分析层。存储层关注数据的采集和稳定传输,数据仓库层则关注数据建模和工具,以提高数据的可用性和易用性,而数据分析层则针对不同用户角色提供定制化的分析工具。数据建模是其中的关键,它包括星型模型、雪花模型等,旨在简化复杂业务数据,使其易于理解。同时,数据工具如SQL查询、数据可视化工具等,帮助用户更便捷地获取和分析数据。
以订单商品中间层为例,数据源通过消息队列进入Hadoop平台,近源数据层保留原始字段结构,但不处理脏数据和一致性问题,目的是快速构建基础数据平台,专注于大数据架构的正确性和稳定性。而对于缓慢变化维的处理,是为了确保数据能反映出业务的动态变化。
有赞通过构建敏捷型数据仓库,实现了对海量数据的有效管理和分析,以支持其精细化运营的需求。这涉及到从数据采集、处理、存储到使用的全过程管理,确保数据的质量、一致性和可追溯性,同时也强调了数据仓库的灵活性和扩展性,以适应不断变化的业务需求。
有赞大数据实践有赞大数据实践:敏捷型数据仓库的构建及其应用敏捷型数据仓库的构建及其应用
前言
互联网的运营人员从了解经营状况转化为精细化运营, 这就于要求数据仓库具有提供高效明细数据能力, 数据仓库如何在庞大数
据量的前提下, 实现满足不同层次的数据提出和分析, 是难点之二.
数据经过ETL最终到达使用数据者手里; 提取数据和提出数据的需求往往来自不同的部门和出于不同的目的. 这一般会导致数据
口径不一致, 数据含义模糊, 甚至数据正确性很难校验. 数据仓库如何保证数据口径一致, 数据路径可追溯性, 是难点之三.
数据仓库的应用领域除了各个业务部门还包括技术部门本身. 由于海量数据处理, 互联网的技术架构越来越依赖大数据平台的支
持. 一个点上平台每天都会有数以万记的店铺和商品更新, 数以亿计的用户日志, 订单数据等. 这些数据在毫无保留的通过消息队
列汇总到数据仓库中. 如果使用数据仓库进行再生产是技术架构重点考虑的事情. 数据仓库拥有其他数据平台无法比拟的横向扩
展和迭代计算能力, 可以直接或者间接面向用户提供数据服务. 这也是大数据的机遇之一.
数据仓库设计
总体架构
存储层 主要解决ETL问题, 如何正确的埋点, 数据稳定正确的传输, 提供可靠的存储计算环境等等. 这部分内容比较复杂, 本文不
重点阐述.
数据仓库层 主要提供数据模型和数据工具两个内容. 数据模型解决数据可用的问题, 数据工具解决数据易用的问题. 本文会重点
介绍数据模型的设计方法和数据工具的作用.
数据分析层 主要解决各种角色如何使用数据仓库的问题. 后面有章节举例说明每个分析工具的优势和适用范围.
数据仓库实例
数据源主要有两种来源, 文件和DB. 通过消息队列收集到hadoop平台. 数据仓库的第一层是近源数据层, 这一层基本上和数据源
保持一样的字段结构. 我们看一下一个例子. 这个例子阐述我们如何构造"订单商品中间层".
下载后可阅读完整内容,剩余8页未读,立即下载
2019-01-15 上传
2024-04-24 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38560768
- 粉丝: 5
- 资源: 895
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端协作项目:发布猜图游戏功能与待修复事项
- Spring框架REST服务开发实践指南
- ALU课设实现基础与高级运算功能
- 深入了解STK:C++音频信号处理综合工具套件
- 华中科技大学电信学院软件无线电实验资料汇总
- CGSN数据解析与集成验证工具集:Python和Shell脚本
- Java实现的远程视频会议系统开发教程
- Change-OEM: 用Java修改Windows OEM信息与Logo
- cmnd:文本到远程API的桥接平台开发
- 解决BIOS刷写错误28:PRR.exe的应用与效果
- 深度学习对抗攻击库:adversarial_robustness_toolbox 1.10.0
- Win7系统CP2102驱动下载与安装指南
- 深入理解Java中的函数式编程技巧
- GY-906 MLX90614ESF传感器模块温度采集应用资料
- Adversarial Robustness Toolbox 1.15.1 工具包安装教程
- GNU Radio的供应商中立SDR开发包:gr-sdr介绍
