CUDA编程:GPU加速的关键技术与应用
需积分: 9 15 浏览量
更新于2024-07-23
收藏 4.52MB PPT 举报
CUDA(Compute Unified Device Architecture)是一种由NVIDIA公司开发的并行计算平台和编程模型,专为利用图形处理单元(GPU)的强大并行处理能力进行通用计算而设计。它是在多核时代的背景下出现的,旨在解决CPU在某些特定计算场景中效率较低的问题,如大规模数据处理和并行计算密集型任务。
在CUDA程序设计中,首先引入了GPGPU(General-Purpose Computing on Graphics Processing Units),这是一种将原本用于图形渲染的GPU资源扩展到执行非图形相关计算任务的理念。GPGPU的核心思想是通过图形编程语言(如OpenGL或CUDA本身)来表达通用计算问题,并将数据映射到GPU上的vertex(顶点)或fragment(像素)处理器上。这种设计的优势在于GPU拥有众多并行核心,能够同时处理大量数据,提高了计算效率。
然而,GPGPU也存在一些挑战,包括硬件资源可能并未充分利用,内存访问模式受到限制,以及调试和错误排查的困难。此外,对图形处理和编程技巧的要求较高,因为程序员需要理解和利用GPU特有的并行计算模型。
CUDA通过Compute Unified Device Architecture实现了CPU和GPU的有效结合,它将传统的CPU和GPU工作负载分离。在CUDA编程中,串行部分的任务会在CPU上执行,而那些适合并行处理的计算任务则在GPU上运行。例如,一个CUDA程序通常包含CPU上的serial code(串行代码)和GPU上的parallel kernel(并行内核),通过grid和block的概念组织这些并行任务。kernel函数<<<nBlk,nTid>>>(args)中,nBlk代表块的数量,nTid代表每个块内的线程数量,args则是传递给内核的参数。
GPU与CPU在硬件架构上有着显著区别。CPU更侧重于控制和指令处理,拥有更多的缓存资源和流控制能力,适合处理非规则数据结构、递归算法和分支密集型任务,但这些任务往往不适合大规模并行化。相反,GPU设计上更倾向于数据计算,其ALU(算术逻辑单元)密集,内存容量大但带宽高,适合处理规则数据结构和可预测的数组运算,常被用于大规模数据并行处理,如石油勘探、金融分析、医疗成像等领域的计算密集型任务。
总结来说,CUDA程序设计是一种利用GPU进行高性能计算的技术,它通过GPU并行计算模型优化了对规则数据结构的处理,但同时也面临资源利用效率、内存访问和调试等问题。掌握CUDA编程对于提升特定计算任务的性能至关重要,特别是在需要处理大量并行任务的应用场景中。
| © 2010 LenovoLenovo Confidential
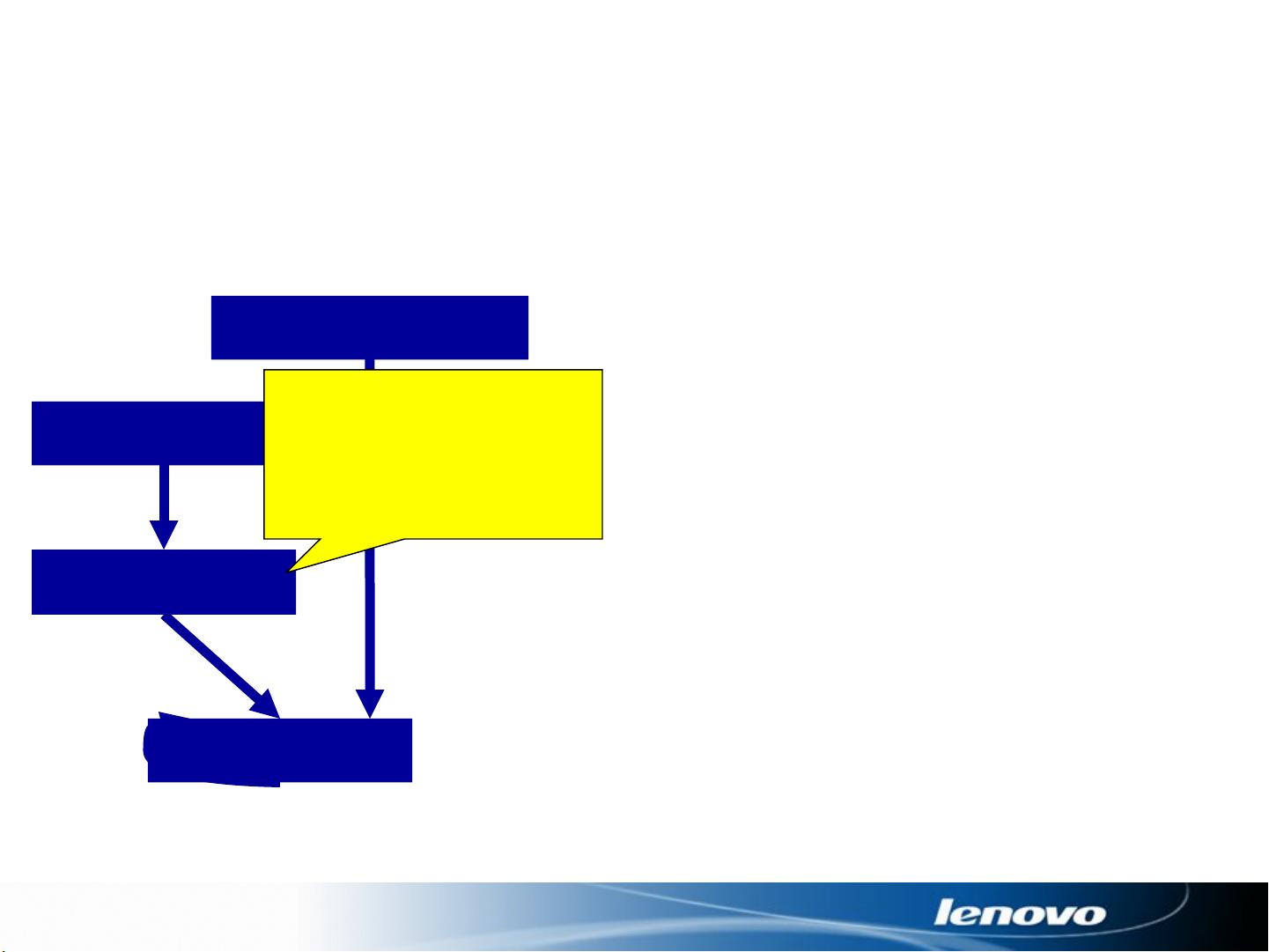
Advanced MRI Reconstruction
kx
ky
FFT
Cartesian Scan Data
(a)
Spiral Scan Data
Iterative
Reconstruction
(c)
kx
ky
Gridding
(b)
(b)
kx
ky
Spiral scan data + Iterative recon
Reconstruction requires a lot of computation

剩余63页未读,继续阅读
2011-03-11 上传
2024-07-09 上传
2023-05-22 上传
2023-06-27 上传
2023-06-24 上传
2023-09-06 上传
2023-06-25 上传
2023-10-18 上传
2024-01-26 上传

twohead
- 粉丝: 4
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- WPF渲染层字符绘制原理探究及源代码解析
- 海康精简版监控软件:iVMS4200Lite版发布
- 自动化脚本在lspci-TV的应用介绍
- Chrome 81版本稳定版及匹配的chromedriver下载
- 深入解析Python推荐引擎与自然语言处理
- MATLAB数学建模算法程序包及案例数据
- Springboot人力资源管理系统:设计与功能
- STM32F4系列微控制器开发全面参考指南
- Python实现人脸识别的机器学习流程
- 基于STM32F103C8T6的HLW8032电量采集与解析方案
- Node.js高效MySQL驱动程序:mysqljs/mysql特性和配置
- 基于Python和大数据技术的电影推荐系统设计与实现
- 为ripro主题添加Live2D看板娘的后端资源教程
- 2022版PowerToys Everything插件升级,稳定运行无报错
- Map简易斗地主游戏实现方法介绍
- SJTU ICS Lab6 实验报告解析
