LM555定时器数据手册:精准时序设计必备
需积分: 16 2 浏览量
更新于2024-07-21
收藏 1.38MB PDF 举报
LM555是一款经典的集成定时器,其datasheet提供了详尽的技术规格和功能概述,使得电子爱好者和硬件设计师能够充分利用这款器件进行各种设计。LM555最初由Texas Instruments (TI)公司推出,作为SE555/NE555的直接替代品,它在电路板上具有高度稳定性和广泛的应用灵活性。
1. **产品特点**:
- LM555具有高精度的定时功能,适用于需要准确时间延迟或振荡的电路设计。
- 它支持多种工作模式,包括Astable(多谐振荡器)和Monostable(单稳态)模式,这使得它能够在微秒级到小时的时间范围内提供灵活的时间控制。
- 在定时延迟模式下,仅需一个外部电阻和一个电容即可实现精确的时间设置,而振荡模式下,通过两个外部电阻和一个电容可以调整频率和脉冲宽度(即占空比)。
- 输出电流强大,能驱动200mA的负载,无论是作为电源输出还是信号源,都能满足一般电路的需求。
- 输出特性兼容TTL标准,便于与其他数字电路连接。
- 温度稳定性极高,典型情况下,温度变化每摄氏度对频率的影响小于0.005%,确保在不同环境下的性能一致性。
2. **应用领域**:
- LM555适用于多种电子应用,如计时器、延时电路、脉冲发生器、电压基准、PWM信号生成等。
- 在电子产品设计中,它可以用于控制继电器、LED灯的开关,以及在自动化设备中实现定时任务。
- 由于其小巧的8-pin VSSOP封装,使得它非常适合空间有限的嵌入式系统和便携式设备。
3. **文档与工具支持**:
- 提供的产品资料包括数据手册、示例电路和购买信息,方便用户获取完整的功能描述、安装指南以及购买途径。
- 配套的工具和软件可能包括模拟器、设计工具和驱动程序,帮助工程师更高效地进行电路设计和仿真。
4. **技术支持与社区**:
- TI公司为LM555提供技术支持,包括故障排查、更新和升级信息,同时,社区论坛也是学习和交流经验的好去处,用户可以分享设计案例和解决问题的方法。
LM555 datasheet是电子工程师必备的参考资料,无论是新手入门还是高级设计者,都能从中找到所需的信息来构建高效稳定的电子系统。它的广泛应用性和卓越性能使其成为电子设计领域的基石之一。
LM555
www.ti.com
SNAS548D –FEBRUARY 2000–REVISED JANUARY 2015
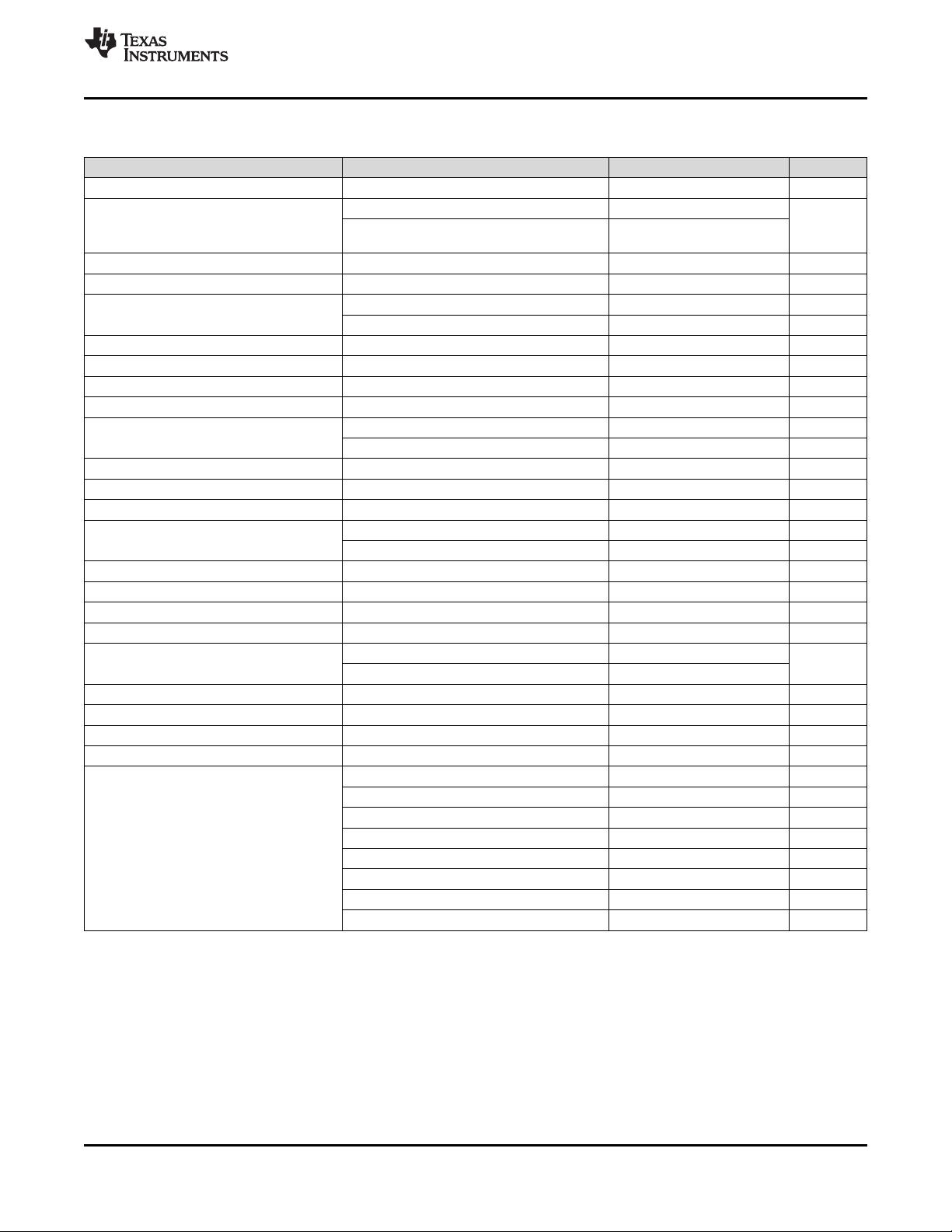
6.5 Electrical Characteristics
(T
A
= 25°C, V
CC
= 5 V to 15 V, unless otherwise specified)
(1)(2)
PARAMETER TEST CONDITIONS MIN TYP MAX UNIT
Supply Voltage 4.5 16 V
Supply Current V
CC
= 5 V, R
L
= ∞ 3 6
mA
V
CC
= 15 V, R
L
= ∞ 10 15
(Low State)
(3)
Timing Error, Monostable
Initial Accuracy 1 %
Drift with Temperature R
A
= 1 k to 100 kΩ, 50 ppm/°C
C = 0.1 μF,
(4)
Accuracy over Temperature 1.5 %
Drift with Supply 0.1 % V
Timing Error, Astable
Initial Accuracy 2.25
Drift with Temperature R
A
, R
B
=1 k to 100 kΩ, 150 ppm/°C
C = 0.1 μF,
(4)
Accuracy over Temperature 3.0%
Drift with Supply 0.30 % /V
Threshold Voltage 0.667 x V
CC
Trigger Voltage V
CC
= 15 V 5 V
V
CC
= 5 V 1.67 V
Trigger Current 0.5 0.9 μA
Reset Voltage 0.4 0.5 1 V
Reset Current 0.1 0.4 mA
Threshold Current
(5)
0.1 0.25 μA
Control Voltage Level V
CC
= 15 V 9 10 11
V
V
CC
= 5 V 2.6 3.33 4
Pin 7 Leakage Output High 1 100 nA
Pin 7 Sat
(6)
Output Low V
CC
= 15 V, I
7
= 15 mA 180 mV
Output Low V
CC
= 4.5 V, I
7
= 4.5 mA 80 200 mV
Output Voltage Drop (Low) V
CC
= 15 V
I
SINK
= 10 mA 0.1 0.25 V
I
SINK
= 50 mA 0.4 0.75 V
I
SINK
= 100 mA 2 2.5 V
I
SINK
= 200 mA 2.5 V
V
CC
= 5 V
I
SINK
= 8 mA V
I
SINK
= 5 mA 0.25 0.35 V
(1) All voltages are measured with respect to the ground pin, unless otherwise specified.
(2) Absolute Maximum Ratings indicate limits beyond which damage to the device may occur. Recommended Operating Conditions indicate
conditions for which the device is functional, but do not ensure specific performance limits. Electrical Characteristics state DC and AC
electrical specifications under particular test conditions which ensures specific performance limits. This assumes that the device is within
the Recommended Operating Conditions. Specifications are not ensured for parameters where no limit is given, however, the typical
value is a good indication of device performance.
(3) Supply current when output high typically 1 mA less at V
CC
= 5 V.
(4) Tested at V
CC
= 5 V and V
CC
= 15 V.
(5) This will determine the maximum value of R
A
+ R
B
for 15 V operation. The maximum total (R
A
+ R
B
) is 20 MΩ.
(6) No protection against excessive pin 7 current is necessary providing the package dissipation rating will not be exceeded.
Copyright © 2000–2015, Texas Instruments Incorporated Submit Documentation Feedback 5
Product Folder Links: LM555
剩余24页未读,继续阅读
2023-07-25 上传
2023-06-10 上传
2023-05-30 上传
2023-05-31 上传
2023-07-07 上传
2023-06-11 上传

ayu_245
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 深入浅出:自定义 Grunt 任务的实践指南
- 网络物理突变工具的多点路径规划实现与分析
- multifeed: 实现多作者间的超核心共享与同步技术
- C++商品交易系统实习项目详细要求
- macOS系统Python模块whl包安装教程
- 掌握fullstackJS:构建React框架与快速开发应用
- React-Purify: 实现React组件纯净方法的工具介绍
- deck.js:构建现代HTML演示的JavaScript库
- nunn:现代C++17实现的机器学习库开源项目
- Python安装包 Acquisition-4.12-cp35-cp35m-win_amd64.whl.zip 使用说明
- Amaranthus-tuberculatus基因组分析脚本集
- Ubuntu 12.04下Realtek RTL8821AE驱动的向后移植指南
- 掌握Jest环境下的最新jsdom功能
- CAGI Toolkit:开源Asterisk PBX的AGI应用开发
- MyDropDemo: 体验QGraphicsView的拖放功能
- 远程FPGA平台上的Quartus II17.1 LCD色块闪烁现象解析
