BP算法在数字识别中的应用与改进
需积分: 21 194 浏览量
更新于2024-07-15
1
收藏 348KB PDF 举报
人工神经网络(ANN)作为人工智能的重要组成部分,自20世纪初以来一直在不断发展和演进。早期的研究起源于跨学科的领域,如物理学、心理学和神经生物学,由赫尔曼·冯·亥姆霍兹、恩斯特·马赫和伊万·帕夫洛夫等学者奠定了基础。尽管早期的研究主要关注学习、视觉和条件反射等概念,但缺乏对神经元工作数学模型的具体描述。
Warren McCulloch和Walter Pitts在20世纪40年代的工作则开启了神经网络的数学建模时代,他们证明了人工神经网络理论上可以执行任意算术和逻辑运算,被认为是神经网络研究的基石。然而,20世纪50年代晚期Frank Rosenblatt的感知机网络和学习规则的应用带来了显著的关注,展示了神经网络在模式识别上的潜力。
然而,Minsky和Papert在随后的著作中揭示了单层感知器的局限性,这导致了对神经网络研究的质疑,许多人认为其发展可能受限。实际上,这一时期是研究的转折点,因为单层感知器的问题通过引入多层网络得到了解决,特别是Backpropagation (BP) 算法,它成为人工神经网络尤其是前向传播网络的核心部分,标志着深度学习和复杂网络结构的发展。
在本文中,作者聚焦于数字识别这一具体应用场景,通过构建数字库,运用BP算法对数字图形进行训练和识别。作者探讨了扩充样本集对识别率的影响,发现样本量的增加确实提高了识别率,但同时也可能导致学习速度变慢和容易陷入局部最优解。通过对比不同的训练算法函数,作者找到了Levenberg-Marquardt BP训练函数,该函数显著提高了训练速度,使得系统的误差精度达到预期。
实验结果显示,研究的数字识别系统具有较高的识别准确性和较快的训练效率,具备模糊识别能力,能有效处理未知数字样本。这种系统不仅技术上先进,而且实用性强,对于数字化时代的数据处理和分析具有重要意义。
本文深入剖析了人工神经网络的BP算法在数字识别中的应用,展示了其在解决复杂问题上的优势,同时也揭示了在实际操作中需要注意的挑战和优化策略,为后续的研究者提供了有价值的参考。
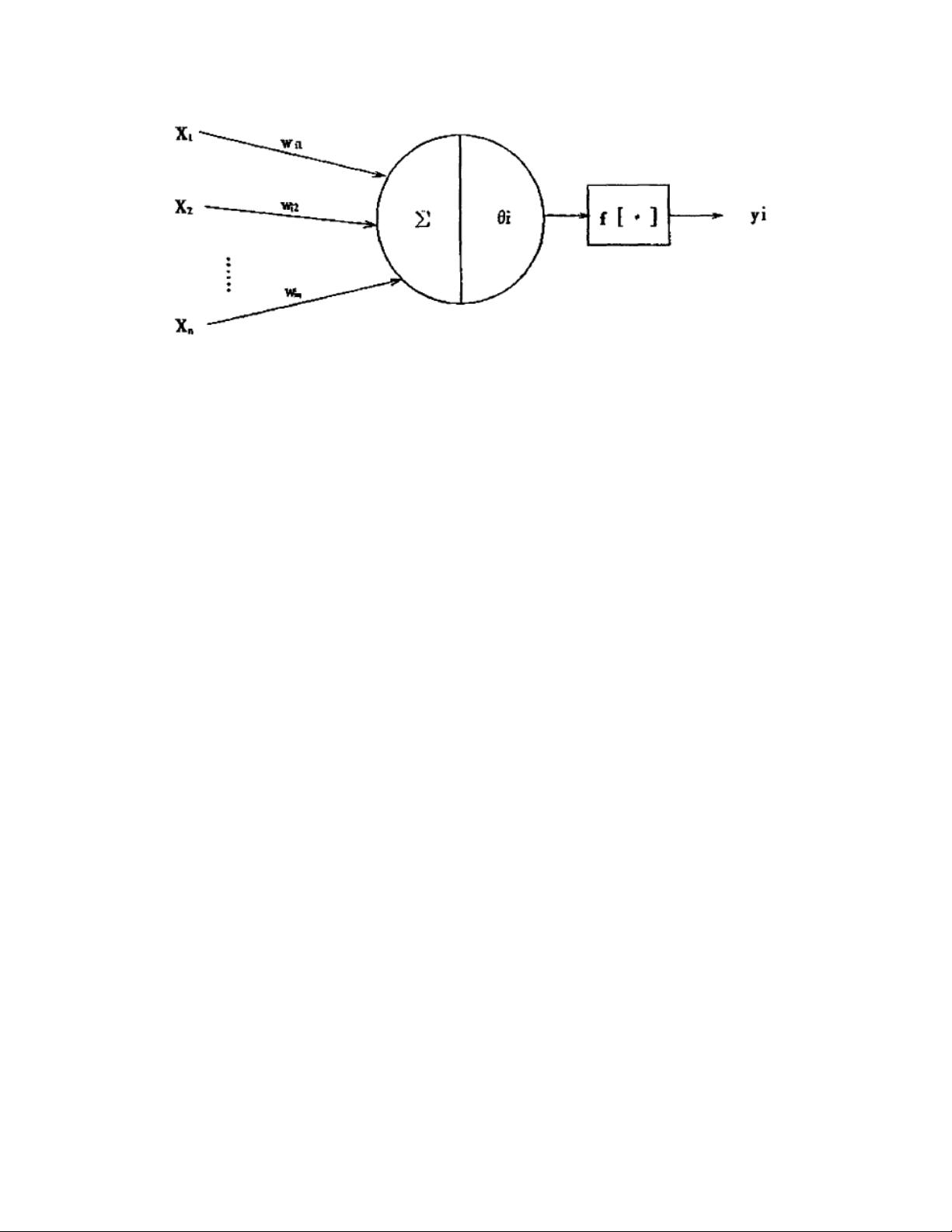
图 2-1 人工神经元模型
在上图中,X1, X2……,Xn 是神经元的输入,即是来自前级 n 个神经元的轴突
的信息:8i 是 i 神经元的阀值:Wil, Wi2,…… Win 分别是 i 神经元对 Xl , X2……,
Xn 的权系数,也即突触的传递效率;Yi 是 i 神经元的输出; f[·]是激活函数,它决定
i 神经元受到输人 X1, X2,……,Xn 的共同刺激达到阀值时以何种方式输出。上述的
神经元模型,其数学模型表达式:
=
−=
∑
=
)(
1
ii
n
j
ijiji
ufy
xwu
θ
(公式: 2.1)
其中,Ui 又被称为诱导局部域。激活函数 f[·]通过诱导局部域 Ui 定义神经元
的输出。常用的激活函数有下面几种:
1)阀值函数
2)分段线性函数
3)sigmoid 函数
4)双曲函数
5)辐射基函数
2.2 神经元中的激发函数
神经元中常用的基本激励函数有以下三种
1.阀值函数(Threshold Function)[5]
<
≥
=
00
0,1
)(
v
v
vf
,若
若
(公式: 2.2)
剩余24页未读,继续阅读
2021-12-24 上传
2021-09-27 上传
2021-10-08 上传
2021-09-26 上传
2021-10-02 上传
2021-09-25 上传
2021-10-02 上传
2021-09-25 上传

123eedz
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索数据转换实验平台在设备装置中的应用
- 使用git-log-to-tikz.py将Git日志转换为TIKZ图形
- 小栗子源码2.9.3版本发布
- 使用Tinder-Hack-Client实现Tinder API交互
- Android Studio新模板:个性化Material Design导航抽屉
- React API分页模块:数据获取与页面管理
- C语言实现顺序表的动态分配方法
- 光催化分解水产氢固溶体催化剂制备技术揭秘
- VS2013环境下tinyxml库的32位与64位编译指南
- 网易云歌词情感分析系统实现与架构
- React应用展示GitHub用户详细信息及项目分析
- LayUI2.1.6帮助文档API功能详解
- 全栈开发实现的chatgpt应用可打包小程序/H5/App
- C++实现顺序表的动态内存分配技术
- Java制作水果格斗游戏:策略与随机性的结合
- 基于若依框架的后台管理系统开发实例解析
