数据竞赛优秀论文:word2vec与xgboost在专家评价模型中的应用
版权申诉
61 浏览量
更新于2024-06-16
收藏 1.37MB PDF 举报
"全国大学生数据统计与分析竞赛21年A题本科生组的优秀论文,主要探讨了基于word2vec和xgboost的专家观点评价模型。论文涉及数据筛选、评分差异性分析、自然语言处理技术的应用以及模型构建与评估。"
在本论文中,参赛团队针对全国大学生数据统计与分析竞赛的A题进行了深入研究,主要分为以下几个方面:
1. **问题论文筛选**:
- 使用Python的pandas库对提供的数据进行预处理和分析。
- 根据学科分组,筛选出68篇具有问题的论文。
2. **评分数据分析**:
- 计算各项评分的平均值和总分平均值,以了解评分的整体情况。
- 采用统计方法探究评分的一致性和差异性,包括:
- 方差分析:度量评分之间的差异程度。
- 皮尔森相关系数:判断评分之间的相关程度。
- Kendall协调系数:评估评分的一致性。
- 基于JS散度的差异性度量:测量评分概率分布之间的距离。
3. **专家观点建模**:
- 应用自然语言处理(NLP)技术,对专家评语进行句子切分和停用词去除。
- 利用doc2vec(基于word2vec)对专家评语进行特征提取,将其转换为200维的特征向量。
- 使用xgboost回归模型构建基于这些特征的专家观点评价模型。
- 通过交叉验证评估模型性能,以RMSE(均方根误差)作为评估指标,测试误差处于[2,5]区间,训练误差小于0.1,表明模型表现良好。
4. **综合评分**:
- 结合问题三的模型结果,对所有评论进行评分,与原始评分加权平均得到最终的综合得分。
5. **论文特征分析**:
- 分析优秀论文与问题论文的特征,基于doc2vec生成的特征向量进行比较。
- 创建一个包含正面、负面和中性评语的语料库,通过比较优秀论文和问题论文的评语与语料库的相似度,发现问题论文的评语更倾向于负面,而优秀论文的评语则更接近中性。
关键词:Kendall系数、JS散度、doc2vec、xgboost回归、生成语料库、文本相似度。
这篇论文展示了如何运用数据分析、统计方法和机器学习技术解决实际问题,特别是利用word2vec和xgboost构建专家观点评价模型,为理解和改进学术评价提供了新的思路。
第 4 页 共 28 页
(方差分析,皮尔森系数,kendall 协同系数,基于 JS 散度的差异性度量)分别进行分
析。
方差分析
计算步骤如下:
( )( )
X X X
Var E X X
= − −
(2.1)
( )( )
1
X X X
d E Var E X X
N
= = − −
(2.2)
其中为
Var
方差,
N
为科目中论文的篇数
我们得到结果:
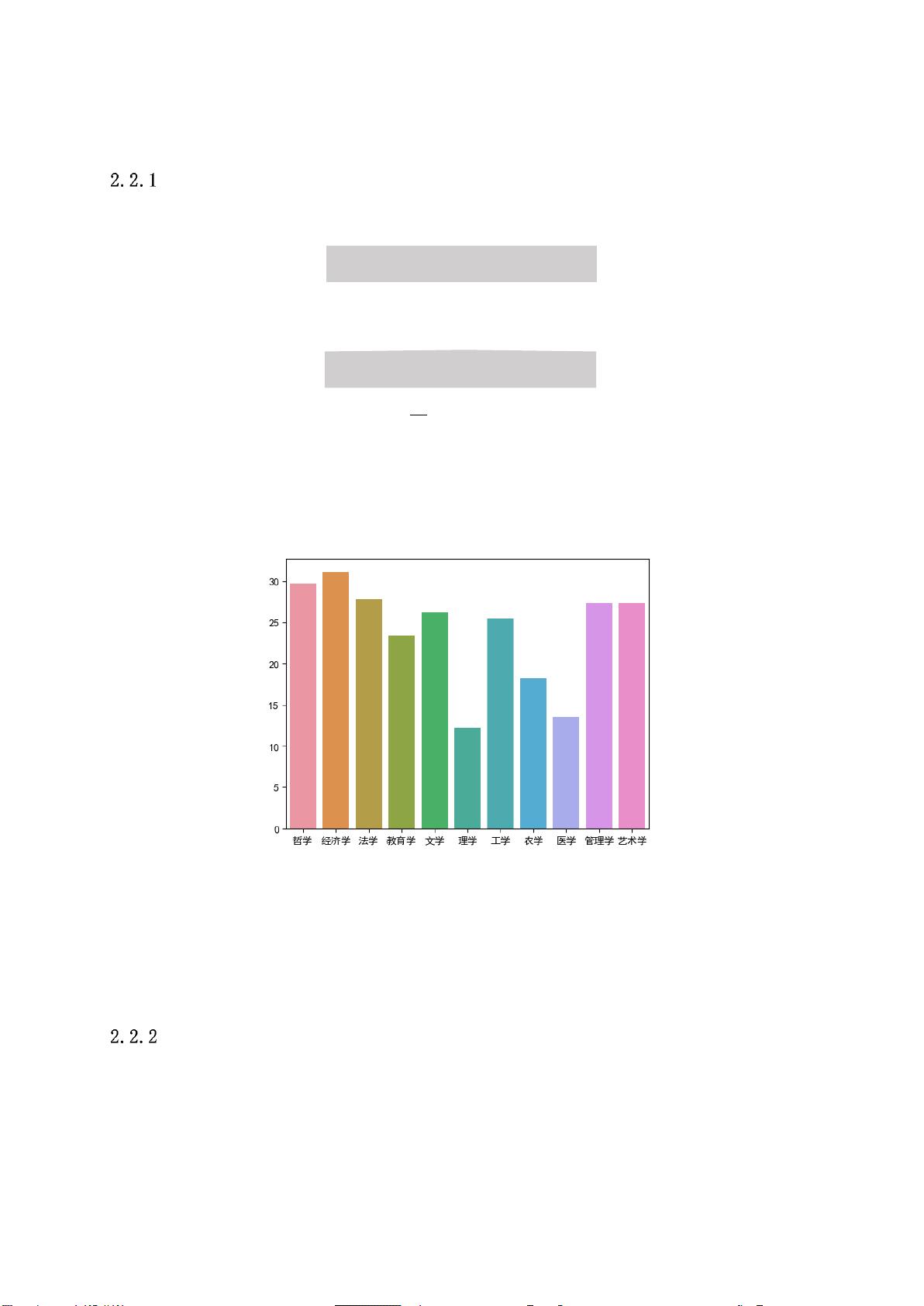
图表 7 方差分析
由图我们可以看到,经济学的论文评分的差异性最大,方差均值甚至超过了 30,这
说明有一些论文的评价很不确定(三个评审专家的观点有较大不同),而理学的差异性
相对较小。
皮尔森相关系数分析
皮尔森系数的计算如下:
1.计算每一篇论文评分的方差
2.计算学科内所有论文的均值
剩余29页未读,继续阅读
2024-03-10 上传
2024-08-24 上传
2023-10-18 上传
2023-10-06 上传
2023-12-20 上传
2023-08-12 上传
2023-07-15 上传

阿拉伯梳子
- 粉丝: 2252
- 资源: 5734
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript DOM事件处理实战示例
- 全新JDK 1.8.122版本安装包下载指南
- Python实现《点燃你温暖我》爱心代码指南
- 创新后轮驱动技术的电动三轮车介绍
- GPT系列:AI算法模型发展的终极方向?
- 3dsmax批量渲染技巧与VR5插件兼容性
- 3DsMAX破碎效果插件:打造逼真碎片动画
- 掌握最简GPT模型:Andrej Karpathy带你走进AI新时代
- 深入解析XGBOOST在回归预测中的应用
- 深度解析机器学习:原理、算法与应用
- 360智脑企业内测开启,探索人工智能新场景应用
- 3dsmax墙砖地砖插件应用与特性解析
- 微软GPT-4助力大模型指令微调与性能提升
- OpenSARUrban-1200:平衡类别数据集助力算法评估
- SQLAlchemy 1.4.39 版本特性分析与应用
- 高颜值简约个人简历模版分享
