机器学习:梯度下降详解与线性回归优化
版权申诉
89 浏览量
更新于2024-06-27
收藏 1.68MB PPTX 举报
在机器学习领域,梯度下降法是一种广泛使用的优化技术,主要用于寻找模型参数,使其预测结果与实际目标最小化误差。它主要应用于解决分类问题、回归问题以及一些复杂的非线性模型的参数优化。本资源聚焦于梯度下降法在机器学习中的应用,特别是在线性回归中的具体实现。
对于线性回归问题,梯度下降通过迭代调整参数(如权重和偏置项),以最小化预测值与实际观测值之间的误差平方和,即损失函数。损失函数的表达式可以通过矩阵形式简化,例如,对于单变量线性回归,损失函数可以写为 \( J(\theta_0, \theta_1) = \frac{1}{2m} \sum_{i=1}^m (h(x_i) - y_i)^2 \),其中 \( h(x_i) = \theta_0 + \theta_1x_i \),\( m \) 是样本数量,\( \theta_0 \) 和 \( \theta_1 \) 是待求参数。
当数据特征矩阵 \( X \) 为满秩或正定矩阵时,可以使用正规方程法找到模型参数的精确解。然而,在实际情况中,通常不满足这些条件,这时就需要使用梯度下降法。梯度下降的核心思想是沿着损失函数的负梯度方向更新参数,以逐步减小误差。学习率(通常用 \( \alpha \) 表示)是一个关键超参数,它控制了每次迭代的步长,合适的大小可以帮助算法更快地收敛到局部最优解。
梯度下降算法的流程包括初始化参数(通常随机设定),然后在每一步迭代中计算梯度,根据学习率调整参数值,直至达到全局最优解(可能不存在)、局部最优解,或者达到预设的最大迭代次数。这个过程适用于不仅限于线性回归,也适用于许多非线性模型,如神经网络,体现了梯度下降法的灵活性。
相比之下,最小二乘法是一种全局优化方法,它直接求解损失函数的最小值,适用于线性回归的模型假设,能够确保得到方差最小的无偏估计。然而,如果模型不符合这些假设,最小二乘方法的优势就不明显,而梯度下降法则可以处理更广泛的模型结构。
梯度下降法是机器学习中一个重要的工具,尤其在解决线性回归和其他优化问题时,通过迭代过程不断调整参数,使得模型的预测性能达到最优。理解其原理和应用有助于我们更好地设计和训练机器学习模型。
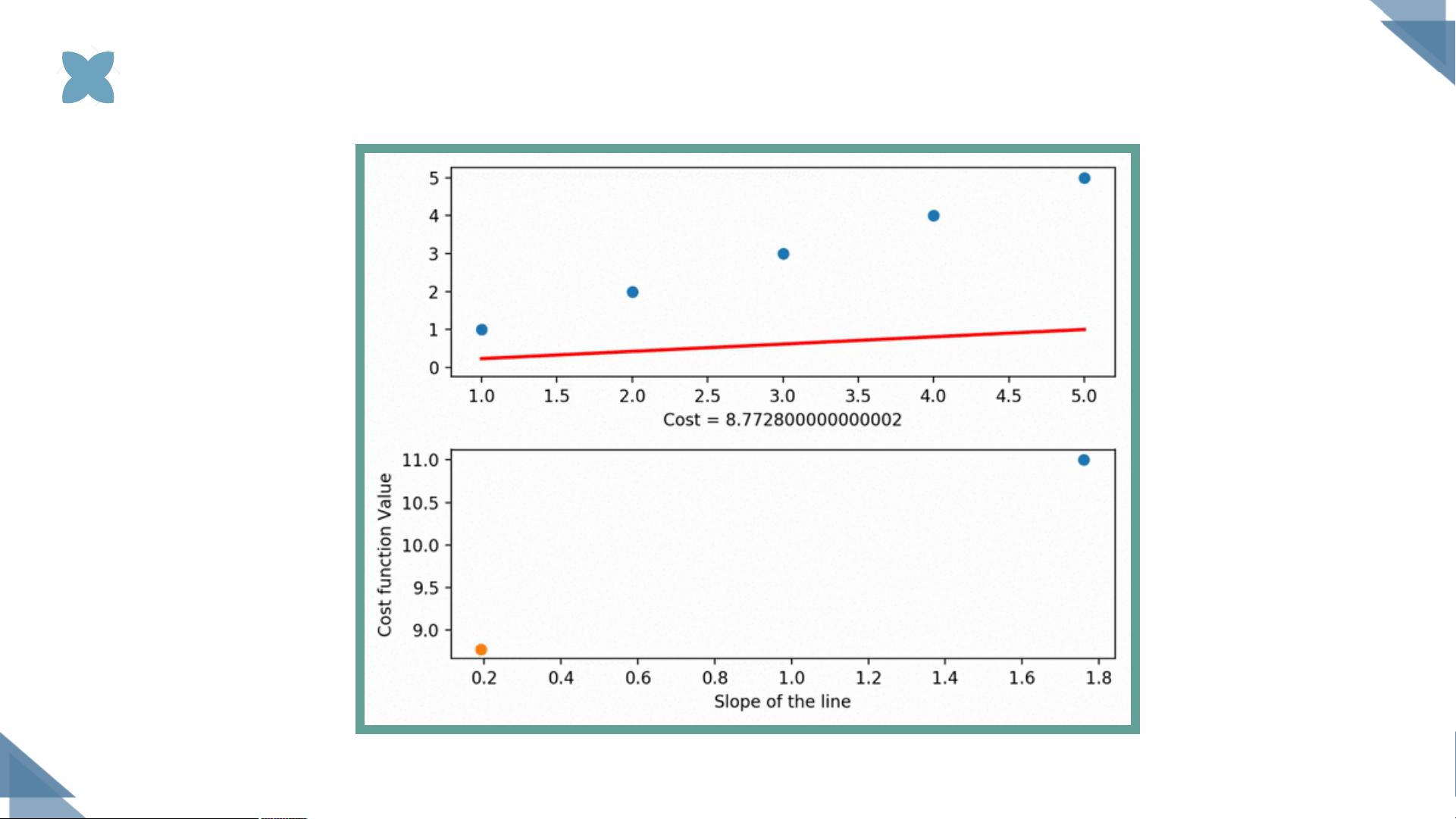
选择线的方法
来自不可思议的数据科学家BhaveshBhatt
剩余15页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-01-14 上传
2020-03-08 上传
2023-01-14 上传
2024-06-26 上传
2021-06-15 上传
2021-06-02 上传

知识世界
- 粉丝: 373
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国江河水系图层shp文件包下载
- 点云二值化测试数据集的详细解读
- JDiskCat:跨平台开源磁盘目录工具
- 加密FS模块:实现动态文件加密的Node.js包
- 宠物小精灵记忆配对游戏:强化你的命名记忆
- React入门教程:创建React应用与脚本使用指南
- Linux和Unix文件标记解决方案:贝岭的matlab代码
- Unity射击游戏UI套件:支持C#与多种屏幕布局
- MapboxGL Draw自定义模式:高效切割多边形方法
- C语言课程设计:计算机程序编辑语言的应用与优势
- 吴恩达课程手写实现Python优化器和网络模型
- PFT_2019项目:ft_printf测试器的新版测试规范
- MySQL数据库备份Shell脚本使用指南
- Ohbug扩展实现屏幕录像功能
- Ember CLI 插件:ember-cli-i18n-lazy-lookup 实现高效国际化
- Wireshark网络调试工具:中文支持的网口发包与分析
