硬件与软件推动的时序数据异常检测综述
需积分: 25 188 浏览量
更新于2024-07-17
2
收藏 1.08MB PDF 举报
时序数据异常检测是一篇综述性论文,发表于2014年的IEEE Transactions on Knowledge and Data Engineering,由Manish Gupta、Jing Gao(均为IEEE会员)和Charu Aggarwal、Jiawei Han(均为IEEE院士)共同撰写。该文章聚焦于几十年来统计学界对时间序列数据异常检测的研究,并特别强调了硬件和软件技术进步对这一领域的影响。
近年来,随着计算机硬件的发展,如新型数据收集机制的出现,以及软件技术的进步,如多样化的数据管理手段,催生了大量新的时序数据类型,如数据流、空间-时间数据、分布式流、时空网络和时间序列数据。这些数据来源于众多应用,推动了对时序异常检测的需求。文章的作者旨在提供一个结构化的概述,总结计算机科学领域针对这些时间序列数据集进行的异常检测工作。
论文关注的关键知识点包括:
1. **时间序列数据的特性**:研究者探讨了时间序列数据的特殊性,如趋势、周期性和季节性,这些特征如何影响异常检测算法的设计和性能。
2. **异常检测方法**:文章详细介绍了各种时序异常检测方法,如基于统计的方法(如Z-score、IQR)、基于机器学习的方法(如支持向量机、决策树)、以及基于深度学习的方法(如RNN、LSTM),这些方法如何处理非线性和复杂性。
3. **实时和在线检测**:由于数据流的实时性,论文讨论了如何在不断流动的数据中实时或近实时地发现异常。
4. **时空关联**:对于空间-时间数据,异常可能与地理位置、时间戳等因素相关联,论文分析了如何考虑这些因素进行联合检测。
5. **分布式和大规模数据**:随着数据规模的增长,如何设计分布式异常检测算法以处理海量时序数据成为关键问题。
6. **挑战与未来方向**:论文还评估了当前研究中的挑战,例如处理噪声、定义恰当的异常阈值,以及如何处理动态变化的环境中的异常。
通过这篇综述,读者可以了解到时序数据异常检测领域的最新进展,以及如何选择和应用适合特定应用场景的检测技术。对于数据科学家、数据工程师和机器学习从业者来说,这是一份重要的参考资料,有助于他们理解并改进在处理时序异常检测任务中的实践。
4 IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 25, NO. 1, JANUARY 2014
if the FSA reaches a state from where there is no
outgoing edge corresponding to the last symbol of the
current subsequence. FSAs have been used for outlier
detection in [23], [35], [36], [37]. The methods to gen-
erate the state transition rules depend on particular
application domains.
Some Markov methods store conditional informa-
tion for a fixed history size=k, while others use a
variable history size to capture richer temporal depen-
dencies. Ye [38] proposes a technique where a Markov
model with k=1 is used. In [39], [40], the conditional
probability distribution (CPD) are stored in proba-
bilistic suffix trees (PSTs) for efficient computations.
Sparse Markovian techniques estimate the conditional
probability of an element based on symbols within the
previous k symbols, which may not be contiguous or
immediately preceding to the element [41], [42].
HMMs can be viewed as temporal dependency-
oriented mixture models, where hidden states and
transitions are used to model temporal dependencies
among mixture components. HMMs do not scale well
to real life datasets. The training process may require
judicious selection of the model, the parameters, and
initialization values of the parameters. On the other
hand, HMMs are interpretable and theoretically well
motivated. Approaches that use HMMs for outlier
detection include [23], [43], [44], [45], [46].
Unsupervised OLAP based Approach
Besides traditional uni-variate time series data,
richer time series are quite popular. For example, a
time series database may contain a set of time series,
each of which are associated with multi-dimensional
attributes. Thus, the database can be represented
using an OLAP cube, where the time series could
be associated with each cell as a measure. Li et
al. [47] define anomalies in such a setting, where given
a probe cell c, a descendant cell is considered an
anomaly if the trend, magnitude or the phase of its
associated time series are significantly different from
the expected value, using the time series for the probe
cell c.
Supervised Approaches
In the presence of labeled training data, the fol-
lowing supervised approaches have been proposed in
the literature: positional system calls features with the
RIPPER classifier [48], subsequences of positive and
negative strings of behavior as features with string
matching classifier [34], [49], neural networks [50],
[51], [52], [53], [54], Elman network [53], motion fea-
tures with SVMs [55], bag of system calls features
with decision tree, Na
¨
ıve Bayes, SVMs [56]. Sliding
window subsequences have also been used as features
with SVMs [57], [58], rule based classifiers [59], and
HMMs [44].
2.1.2 Window based Detection of Outlier Time Series
Given: A database of time series
Normal
or Abnormal
Windows
Database
Test Sequence s
Windows
!
"
Train Sequences
Optional Processing like DWT
Processed Sequence
Processed Sequences
Normal
Samples
Detectors
Length-w
windows
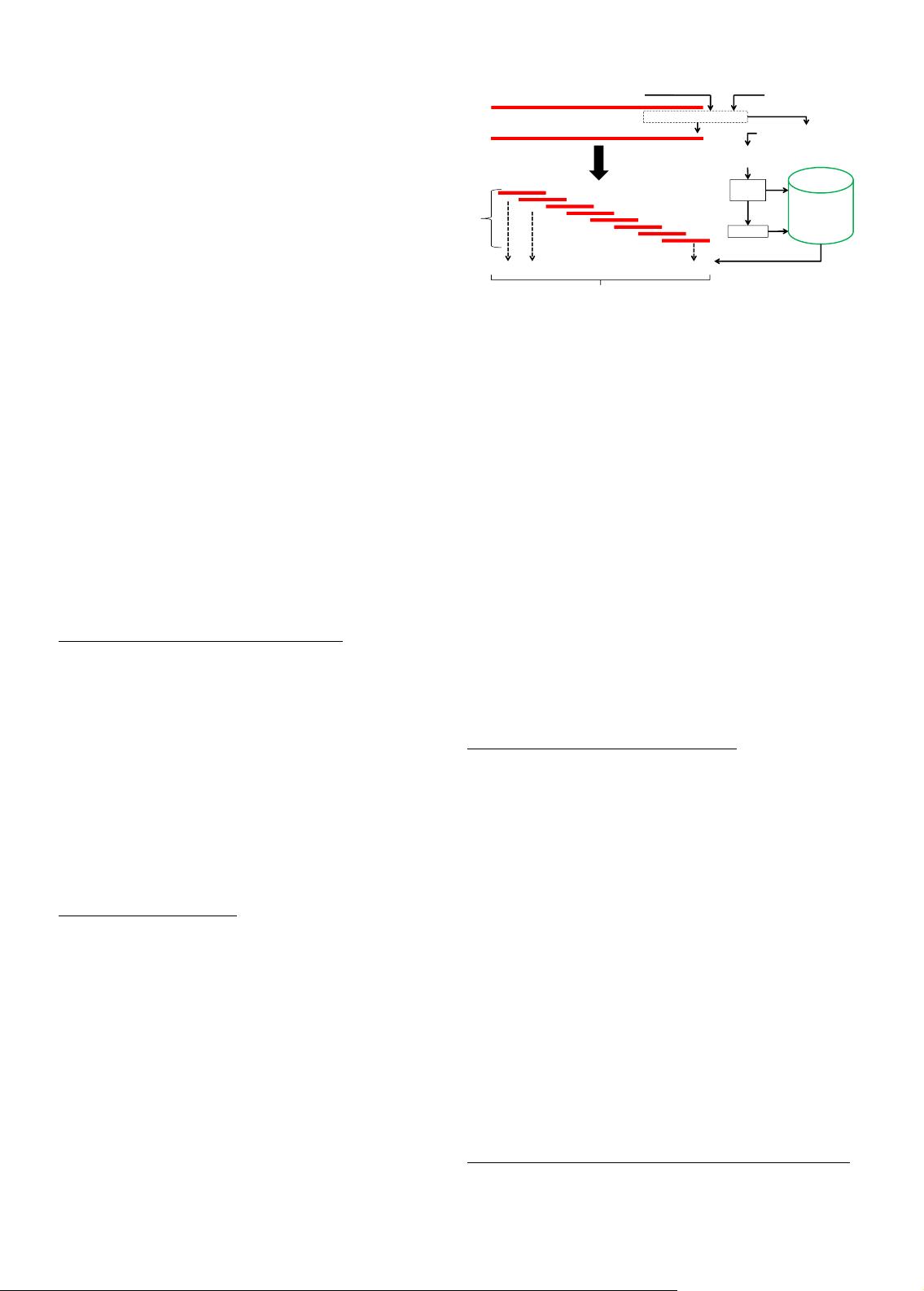
Fig. 2. Window Based Time Series Outlier Detection
Find: All anomalous time windows, and hence
anomalous time series
Compared to the techniques in the previous sub-
section, the test sequence is broken into multiple
overlapping subsequences (windows). The anomaly
score is computed for each window, and then the
anomaly score (AS) for the entire test sequence is
computed in terms of that of the individual windows.
Window-based techniques can perform better local-
ization of anomalies, compared to the techniques that
output the entire time series as outliers directly. These
techniques need the window length as a parameter.
Windows are called fingerprints, pattern fragments,
detectors, sliding windows, motifs, and n-grams in
various contexts. In this methodology, the techniques
usually maintain a normal pattern database, but some
approaches also maintain a negative pattern or a
mixed pattern database. Figure 2 shows a general
sketch of the method.
Normal Pattern Database Approach
In this approach, normal sequences are divided into
size w overlapping windows. Each such window sub-
sequence is stored in a database with its frequency. For
a test sequence, subsequences of size w are obtained,
and those subsequences that do not occur in normal
database are considered mismatches. If a test sequence
has a large number of mismatches, it is marked as
an anomaly [44], [49], [51], [53], [60]. Rather than
looking for exact matches, if a subsequence is not
in the database, soft mismatch scores can also be
computed [20], [61], [62], [63].
Besides contiguous window subsequences, a looka-
head based method can also be used for building
a normal database [64]. For every element in every
normal sequence, the elements occurring at distance
1,2,. . ., k in the sequence are noted. A normal database
of such occurrences is created. Given a new test
sequence, a lookahead of the same size k is used. Each
pair of element occurrence is checked with the normal
database, and the number of mismatches is computed.
Negative and Mixed Pattern Database Approaches
Besides the dictionaries for normal sequences,
anomaly dictionaries can also be created [34], [50],
[65], [66], [67]. All normal subsequences of length w
剩余19页未读,继续阅读
2019-09-06 上传
2021-02-03 上传
2022-04-16 上传
点击了解资源详情
2023-04-06 上传
2023-06-08 上传
2023-06-07 上传

z6203271
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
