FPGA上的CNN部署流程与挑战
需积分: 9 185 浏览量
更新于2024-07-18
1
收藏 4.03MB PDF 举报
"CNN_to_FPGA_Toolflows"
在当前人工智能领域,特别是机器学习和深度神经网络(DNN)的发展中,将卷积神经网络(CNN)部署到现场可编程门阵列(FPGA)上已经成为一个重要的研究方向。CNNs由于在图像识别、目标检测等领域展现出的优秀性能,如YOLOv2这样的实时检测模型,被广泛应用于各种实时或嵌入式系统。然而,将复杂的CNN模型移植到FPGA上,以实现硬件加速,面临着一系列的挑战和趋势。
首先,CNNs的结构通常包括特征提取层、全连接层等,这些层在FPGA上的实现需要高效的并行计算能力。FPGA的优势在于其可编程性,允许设计者定制硬件结构以适应特定的计算任务,从而实现更高的计算效率和能效比。在映射CNNs到FPGA的过程中,关键步骤包括模型的优化、硬件资源的分配以及布线设计。
工具流是将CNN部署到FPGA的关键,它涵盖了从训练和推理到硬件实现的全过程。早期的工作,如First Wave,主要由学术界推动,包括UC Berkeley、NYU/Facebook和Univ. of Montreal等机构。随着深度学习软件生态系统的成熟,如TensorRT(NVIDIA)、Neural Network Toolbox(MathWorks)等,使得CNN的优化和部署变得更加便捷。同时,产业界的参与,如Facebook、Google、Microsoft、Amazon和Apple等,也推出了各自的解决方案,如CoreML(Apple)和TensorRT(NVIDIA),这些工具支持高效的模型转换和推理。
CNN的部署流程通常包括以下步骤:用户首先通过深度学习框架(如TensorFlow、PyTorch等)构建和训练CNN模型,然后将训练好的权重导入,接着进行模型优化,这可能涉及到量化、剪枝等技术以减少计算量和存储需求,最后在FPGA上进行映射。在映射过程中,不仅要考虑CNN的结构,还要考虑目标硬件平台,例如CPU、GPU、NVIDIA的TK1、TX1和TX2,以及Qualcomm Snapdragon和Apple A11等移动处理器。这些平台的硬件特性差异很大,因此需要针对不同平台进行优化映射,以确保在满足性能需求的同时,尽可能降低功耗。
总结来说,CNN_to_FPGA的工具流涉及到AI、机器学习和深度学习的前沿技术,其目标是利用FPGA的灵活性和高效性来加速CNN的运算。这一过程涵盖模型训练、硬件映射优化、跨平台兼容等多个环节,涉及到多种工具和技术,是当前AI硬件加速研究中的一个重要课题。随着技术的不断进步,我们期待看到更高效、更易于使用的工具流出现,以推动CNN在更多领域的广泛应用。
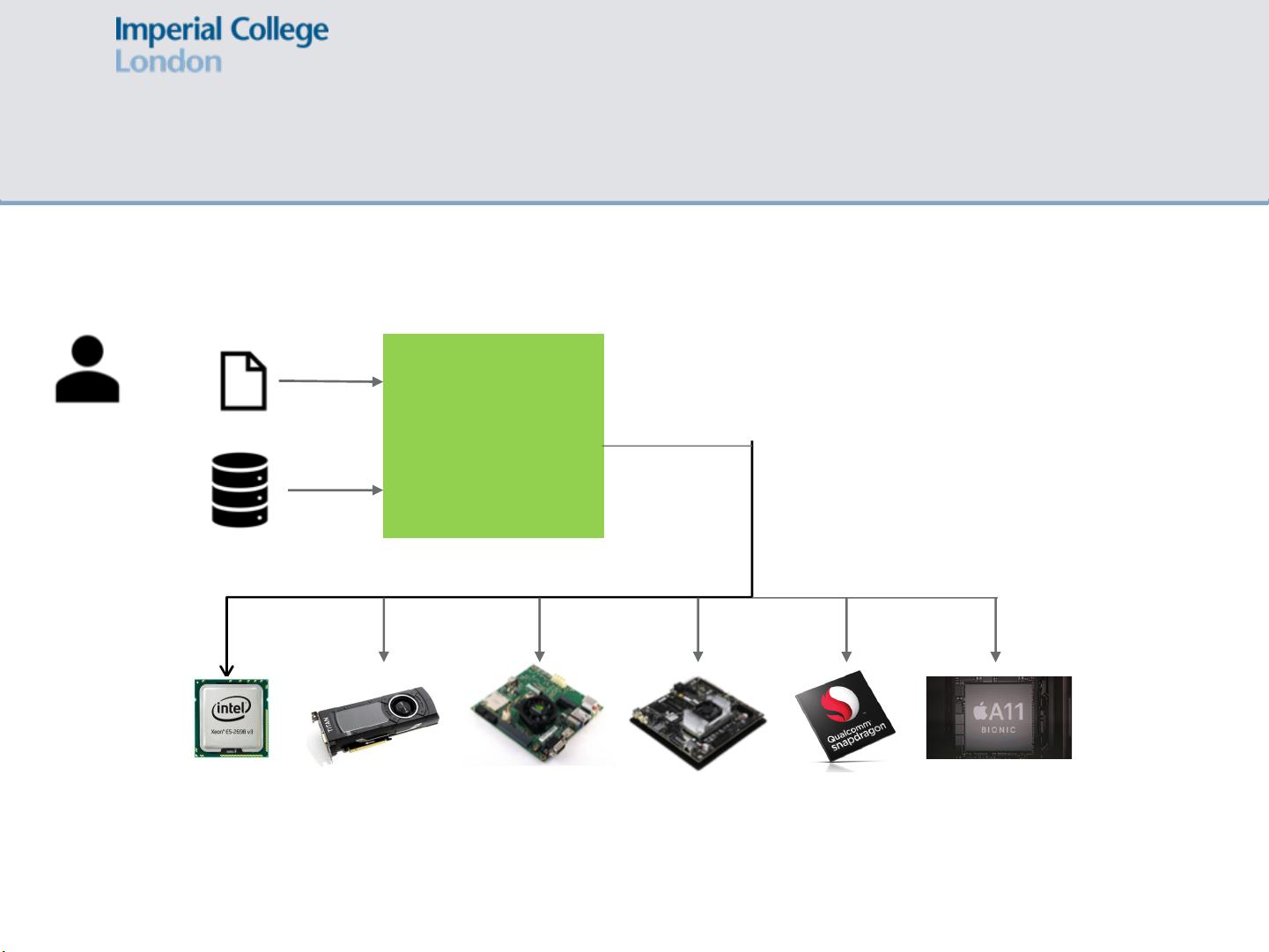
CNN Deployment Flow
6
Deep Learning
Framework
CNN Structure
User Input
Trained Weights
CPU
GPU
TK1
TX1 &
TX2
Qualcomm
Snapdrago
n
Apple A11
Optimised mapping
Christos Bouganis
剩余29页未读,继续阅读
2024-08-26 上传
2021-09-30 上传
251 浏览量
2024-10-17 上传
2024-10-24 上传
271 浏览量
2023-05-25 上传
154 浏览量
110 浏览量
115 浏览量

syj0815
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- 深入解析JavaWeb中Servlet、Jsp与JDBC技术
- 粒子滤波在视频目标跟踪中的应用与MATLAB实现
- ISTQB ISEB基础级认证考试BH0-010题库解析
- 深入探讨HTML技术在hundeakademie中的应用
- Delphi实现EXE/DLL文件PE头修改技术
- 光线追踪:探索反射与折射模型的奥秘
- 构建http接口以返回json格式,使用SpringMVC+MyBatis+Oracle
- 文件驱动程序示例:实现缓存区读写操作
- JavaScript顶盒技术开发与应用
- 掌握PLSQL: 从语法到数据库对象的全面解析
- MP4v2在iOS平台上的应用与编译指南
- 探索Chrome与Google Cardboard的WebGL基础VR实验
- Windows平台下的IOMeter性能测试工具使用指南
- 激光切割板材表面质量研究综述
- 西门子200编程电缆PPI驱动程序下载及使用指南
- Pablo的编程笔记与机器学习项目探索
