详解消息队列与事件循环:网页动态响应背后的秘密
需积分: 0 100 浏览量
更新于2024-08-05
收藏 1.15MB PDF 举报
本文主要探讨了C#编程中的消息队列和事件循环在网页动态加载过程中的关键作用。首先,文章强调了在现代Web应用中,由于主线程的繁重任务(如DOM操作、样式计算、布局处理和JavaScript执行等),需要一个有效的系统来管理和调度这些任务,这就是消息队列和事件循环的职责。
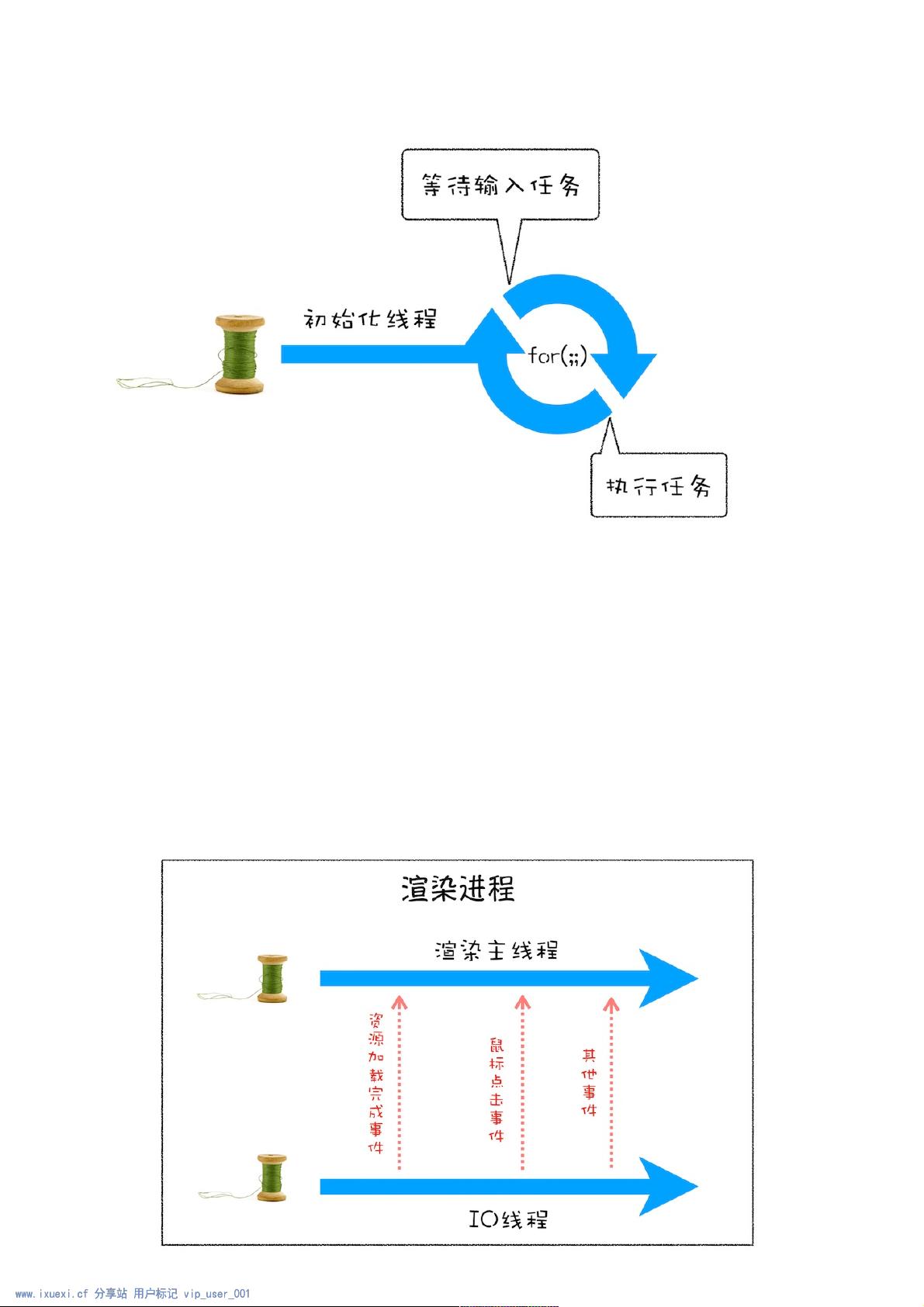
消息队列作为核心组件,允许非阻塞的异步任务处理。当一个新的IO线程产生任务时,这个任务不会立即阻塞主线程,而是被添加到消息队列的尾部。这样,主线程就可以专注于当前正在执行的任务,而不会因为等待新任务的完成而暂停。
事件循环是消息队列的具体实现,它是一种循环机制,负责不断地从队列的头部取出任务进行执行。当主线程空闲时,它会检查消息队列,发现有任务后立即执行,而不是等待所有任务都完成。这种方式确保了页面的实时响应,即使在处理用户输入或网络请求时,也能保持流畅的用户体验。
通过逐步分析,文章使用C++为例来说明这一过程,尽管读者无需深入C++知识,只需了解JavaScript或Python即可理解。在传统的单线程模型中,任务按顺序执行,但无法处理运行时产生的新任务。引入事件循环后,程序能够动态地接收和处理新任务,提高了效率和灵活性。
理解消息队列和事件循环对于掌握Web应用程序的后台机制至关重要,它决定了页面响应速度和整体性能。通过学习和实践这些概念,开发者可以更好地优化他们的代码,提升网站的性能和用户体验。
剩余10页未读,继续阅读
2022-08-04 上传
2022-08-04 上传
2022-08-04 上传
2023-06-10 上传
2023-05-24 上传
2023-05-24 上传
2023-05-24 上传
2023-07-14 上传
2023-06-12 上传

是因为太久
- 粉丝: 24
- 资源: 295
 我的内容管理
展开
我的内容管理
展开







最新资源
- 构建基于Django和Stripe的SaaS应用教程
- Symfony2框架打造的RESTful问答系统icare-server
- 蓝桥杯Python试题解析与答案题库
- Go语言实现NWA到WAV文件格式转换工具
- 基于Django的医患管理系统应用
- Jenkins工作流插件开发指南:支持Workflow Python模块
- Java红酒网站项目源码解析与系统开源介绍
- Underworld Exporter资产定义文件详解
- Java版Crash Bandicoot资源库:逆向工程与源码分享
- Spring Boot Starter 自动IP计数功能实现指南
- 我的世界牛顿物理学模组深入解析
- STM32单片机工程创建详解与模板应用
- GDG堪萨斯城代码实验室:离子与火力基地示例应用
- Android Capstone项目:实现Potlatch服务器与OAuth2.0认证
- Cbit类:简化计算封装与异步任务处理
- Java8兼容的FullContact API Java客户端库介绍
