手写体识别MNIST数据集处理和CNN模型搭建
需积分: 0 34 浏览量
更新于2024-08-05
收藏 1.07MB PDF 举报
实验二 mnist 手写体识别1
本实验的主要目的是使用 CNN 模型来实现 mnist 手写体识别。实验中我们使用了 keras 库来实现模型的构建和训练。
首先,我们需要加载 mnist 数据集。mnist 数据集是一个常用的手写体识别数据集,由 60000 个训练样本和 10000 个测试样本组成。每个样本是一个 28x28 的图像,所属类别共有 10 种(0-9)。我们使用 tf.keras.datasets.mnist.load_data() 函数来加载数据集,得到训练集和测试集。
在数据预处理阶段,我们需要对数据进行标准化,以避免尺度差异对模型的影响。我们将所有像素值除以 255,以将其归一化到 0.0 到 1.0 之间。
在模型构建阶段,我们使用 keras 的 Sequential 模型来构建 CNN 模型。模型结构如下:
* 卷积层 -> 批标准化 -> 卷积层 -> 批标准化 -> 池化层 -> dropout
* 卷积层 -> 批标准化 -> dropout -> 扁平化 -> 全连接层 -> dropout -> 全连接层 -> 输出
在每个卷积层中,我们使用 64 个卷积核,卷积窗口大小为 5x5 或 3x3,激活函数选择 relu。relu 函数可以使网络训练更快、增加网络的非线性和防止梯度消失。
在批标准化层中,我们使用 BatchNormalization 来防止梯度爆炸或弥散、提高模型对不同超参数的鲁棒性、让大部分激活函数远离饱和区域。
在池化层中,我们使用 MaxPooling2D,池化窗口大小为 2x2,步长为 2x2。
在全连接层中,我们使用 dense 层,输出维度为 256 和 10,激活函数选择 relu 和 softmax。softmax 函数可以将神经网络的输出转换为概率分布。
在模型训练阶段,我们使用 Adam 优化器和 categorical_crossentropy 损失函数来训练模型。模型训练完成后,我们可以使用模型来识别手写体数字图像。
实验⼆ mnist ⼿写体识别
数据加载和数据预处理
数据加载
直接从包内导⼊数据集
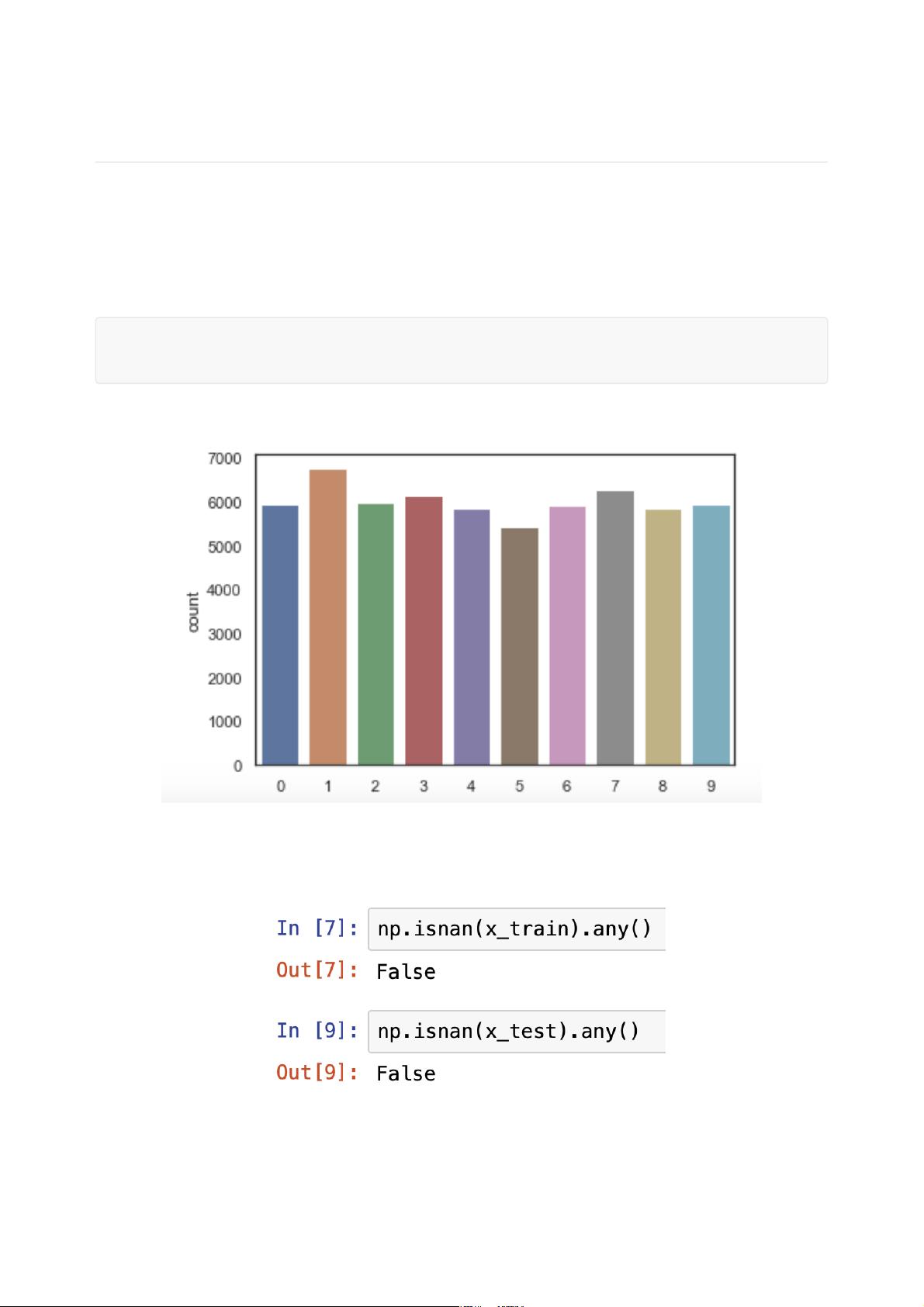
数据的类别分布情况如下图所示,可以看到⼗种类别每种的数⽬较平均
数据处理和分析
空值判断
可以看到不包含空值,所以不需要对于空值的预处理
标准化
标准化避免尺度差异造成的影响。CNN模型在标准化后⼀般运⾏效果更好。这⾥对于 MNIST 数据集,
我们希望每个值都在 0.0 和 1.0 之间。 由于所有值最初都在 0.0-255.0 范围内,因此除以 255.0。
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
下载后可阅读完整内容,剩余5页未读,立即下载
2022-04-16 上传
2022-05-01 上传
2020-09-17 上传
2024-10-26 上传
2019-07-02 上传
2019-07-02 上传
2024-06-13 上传
点击了解资源详情
点击了解资源详情









