
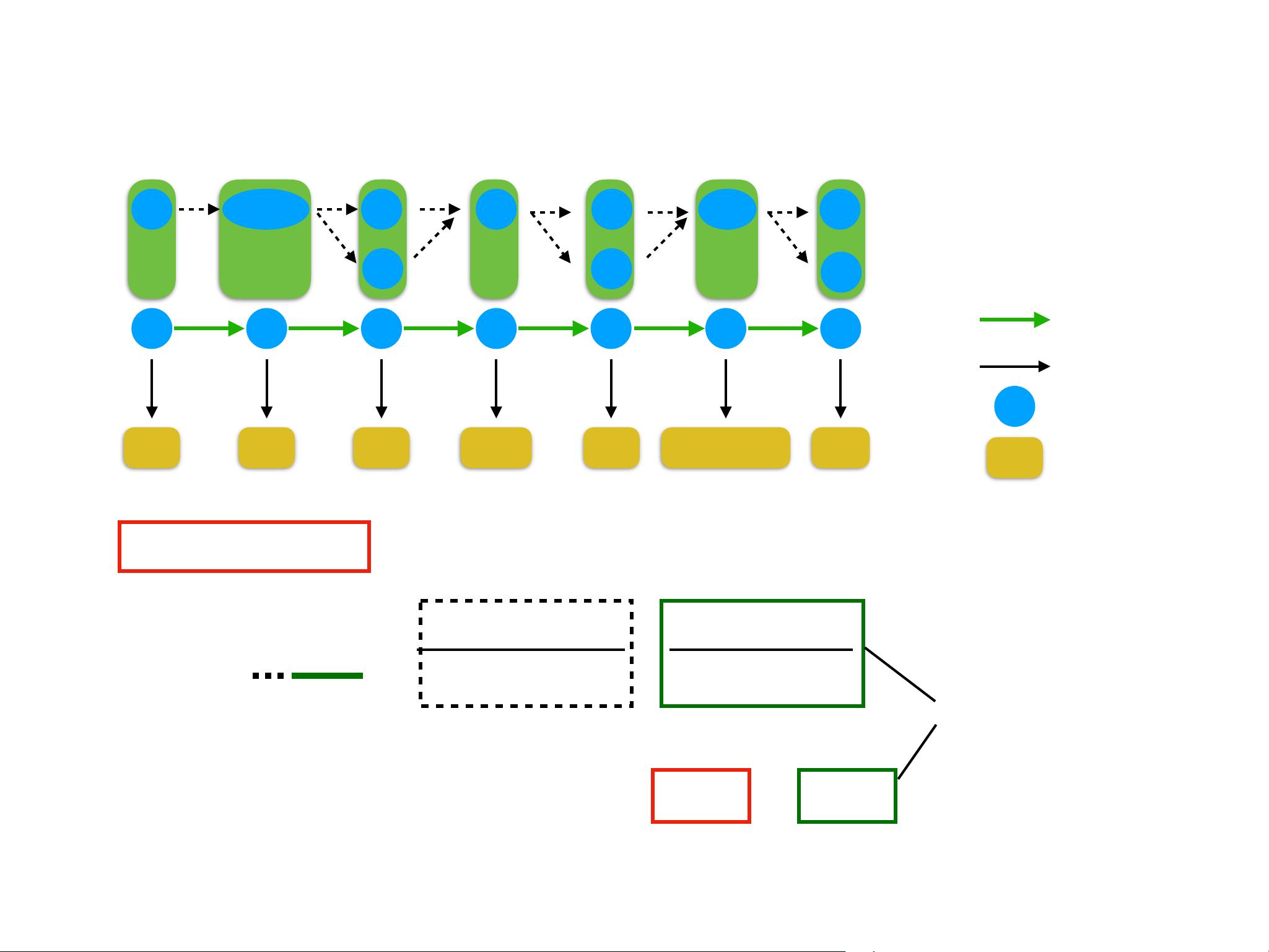
rr
vn
v v
vn
gm
vn
vv
S1
S2
S3
S4
S5
S6 S7
δ
1
(s
i
) = π
i
b
s
i
(z
i
) =
cou nt(s
i
)
∑
s
i
cou nt(s
i
)
×
cou nt(z
i
, s
i
)
cou ntr(s
i
)
δ
m
(s
i
) = arg max
s
i
[δ
m−1
(s
i−1
) × a
s
i−1
,s
i
] × b
i
(z
i
)
ude1
Viterbi algorithm

剩余54页未读,继续阅读

JM_steven
- 粉丝: 0
- 资源: 18
 我的内容管理
展开
我的内容管理
展开







最新资源
- 构建Cadence PSpice仿真模型库教程
- VMware 10.0安装指南:步骤详解与网络、文件共享解决方案
- 中国互联网20周年必读:影响行业的100本经典书籍
- SQL Server 2000 Analysis Services的经典MDX查询示例
- VC6.0 MFC操作Excel教程:亲测Win7下的应用与保存技巧
- 使用Python NetworkX处理网络图
- 科技驱动:计算机控制技术的革新与应用
- MF-1型机器人硬件与robobasic编程详解
- ADC性能指标解析:超越位数、SNR和谐波
- 通用示波器改造为逻辑分析仪:0-1字符显示与电路设计
- C++实现TCP控制台客户端
- SOA架构下ESB在卷烟厂的信息整合与决策支持
- 三维人脸识别:技术进展与应用解析
- 单张人脸图像的眼镜边框自动去除方法
- C语言绘制图形:余弦曲线与正弦函数示例
- Matlab 文件操作入门:fopen、fclose、fprintf、fscanf 等函数使用详解
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


