深度学习与注意力机制:机器翻译的革新策略
11 浏览量
更新于2024-08-30
收藏 329KB PDF 举报
机器翻译/注意力机制
机器翻译(Machine Translation, MT)是一种利用计算机技术跨越语言障碍进行自动翻译的前沿技术,它涉及源语言和目标语言的双向转换。源语言(Source Language)是原始需要翻译的语言,目标语言(Target Language)则是翻译后的语言。它是自然语言处理(Natural Language Processing, NLP)领域中的关键研究课题,尤其是在处理多语言理解和生成任务上。
早期的机器翻译系统主要依赖于基于规则的方法,依赖语言学家手动构建源语言与目标语言之间的转换规则,并将这些规则编码至计算机。这种方法对语言学家的专业知识要求极高,且由于语言复杂性和多样性,很难形成全面的规则集,这成为传统机器翻译面临的重大挑战。
为解决规则获取困难的问题,统计机器翻译(Statistical Machine Translation, SMT)应运而生。SMT通过利用大量双语平行语料库,通过机器学习自动学习翻译规则,降低了对人工规则的依赖。然而,SMT依然面临一些问题,如特征设计的局限性、缺乏全局视角以及对预处理步骤的敏感性,如词语对齐、分词和语法分析等。
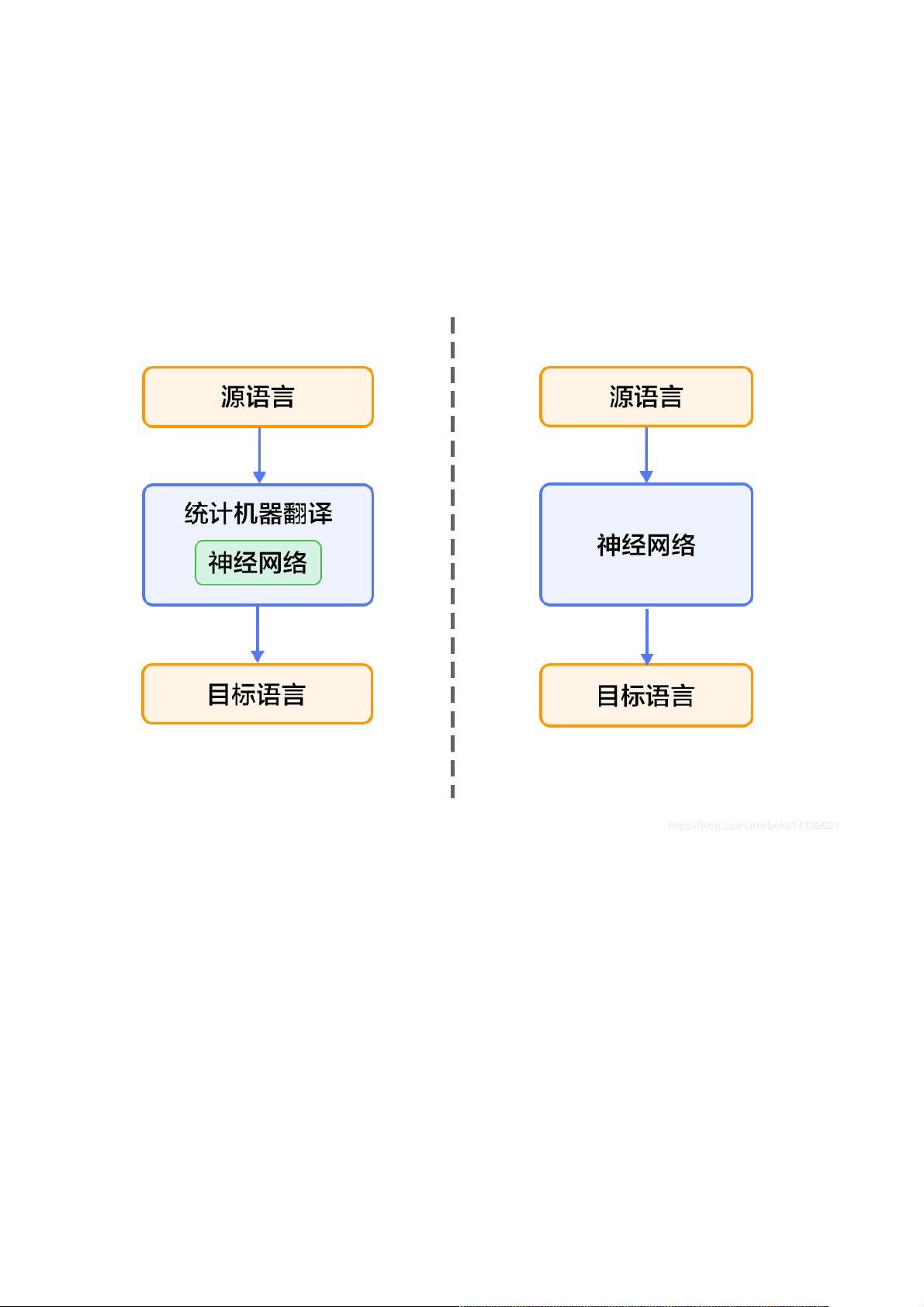
近年来,深度学习技术的引入彻底改变了机器翻译的格局。深度学习方法可以分为两大类:一是增强现有统计机器翻译架构,例如通过神经网络优化语言模型和排序模型(如图1左侧所示);二是采用端到端的神经网络机器翻译(End-to-End Neural Machine Translation, NMT),即直接使用神经网络模型将源语言输入转化为目标语言,如Transformer模型(图1右侧所示)。NMT模型通过自注意力机制(Attention Mechanism)解决了长距离依赖问题,使得翻译过程更加准确和流畅。
以中英翻译为例,当输入一句中文并设置搜索宽度为3时,NMT模型能生成接近原文意思的英语翻译,如“0-5.36816 These are signs of hope and relief.”这样的输出,显示出深度学习在机器翻译中的显著优势。
机器翻译的进步经历了从规则驱动到统计模型再到深度学习的转变,其中注意力机制作为核心组件,极大地提升了翻译的质量和效率。随着技术的不断发展,机器翻译有望进一步逼近人类翻译水平,成为全球跨文化交流的重要工具。
机器翻译机器翻译/注意力机制注意力机制
机器翻译机器翻译(machine translation, MT)是用计算机来实现不同语言之间翻译的技术。被翻译的语言通常称为源语言(source language),翻译成的结果语言称为目标语言
(target language)。机器翻译即实现从源语言到目标语言转换的过程,是自然语言处理的重要研究领域之一。
早期机器翻译系统多为基于规则的翻译系统,需要由语言学家编写两种语言之间的转换规则,再将这些规则录入计算机。该方法对语言学家的要求非常高,而且我们几乎无
法总结一门语言会用到的所有规则,更何况两种甚至更多的语言。因此,传统机器翻译方法面临的主要挑战是无法得到一个完备的规则集合。
为解决以上问题,统计机器翻译(Statistical Machine Translation, SMT)技术应运而生。在统计机器翻译技术中,转化规则是由机器自动从大规模的语料中学习得到的,而
非我们人主动提供规则。因此,它克服了基于规则的翻译系统所面临的知识获取瓶颈的问题,但仍然存在许多挑战:1)人为设计许多特征(feature),但永远无法覆盖所
有的语言现象;2)难以利用全局的特征;3)依赖于许多预处理环节,如词语对齐、分词或符号化(tokenization)、规则抽取、句法分析等,而每个环节的错误会逐步累
积,对翻译的影响也越来越大。
近年来,深度学习技术的发展为解决上述挑战提供了新的思路。将深度学习应用于机器翻译任务的方法大致分为两类:1)仍以统计机器翻译系统为框架仍以统计机器翻译系统为框架,只是利用神经网
络来改进其中的关键模块,如语言模型、调序模型等(见图1的左半部分);2)不再以统计机器翻译系统为框架,而是直接用神经网络将源语言映射到目标语言,即端到端端到端
的神经网络机器翻译的神经网络机器翻译(End-to-End Neural Machine Translation, End-to-End NMT)(见图1的右半部分),简称为NMT模型。
图1. 基于神经网络的机器翻译系统
效果展示效果展示
以中英翻译(中文翻译到英文)的模型为例,当模型训练完毕时,如果输入如下已分词的中文句子:
这些 是 希望 的 曙光 和 解脱 的 迹象 .
如果设定显示翻译结果的条数(即柱搜索算法的宽度)为3,生成的英语句子如下:
0 -5.36816 These are signs of hope and relief .
1 -6.23177 These are the light of hope and relief .
2 -7.7914 These are the light of hope and the relief of hope .
左起第一列是生成句子的序号;左起第二列是该条句子的得分(从大到小),分值越高越好;左起第三列是生成的英语句子。另外有两个特殊标志:e 表示句子的结
尾,unk表示未登录词(unknown word),即未在训练字典中出现的词。
编码器编码器-解码器框架解码器框架
编码器-解码器(Encoder-Decoder)框架用于解决由一个任意长度的源序列到另一个任意长度的目标序列的变换问题。即编码阶段将整个源序列编码成一个向量,解码阶段
通过最大化预测序列概率,从中解码出整个目标序列。编码和解码的过程通常都使用RNN实现。
下载后可阅读完整内容,剩余3页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-01-06 上传
2023-05-24 上传
2021-01-06 上传
2021-01-06 上传
2021-01-06 上传
2021-01-06 上传

weixin_38745233
- 粉丝: 10
- 资源: 906
 我的内容管理
展开
我的内容管理
展开







最新资源
- 正整数数组验证库:确保值符合正整数规则
- 系统移植工具集:镜像、工具链及其他必备软件包
- 掌握JavaScript加密技术:客户端加密核心要点
- AWS环境下Java应用的构建与优化指南
- Grav插件动态调整上传图像大小提高性能
- InversifyJS示例应用:演示OOP与依赖注入
- Laravel与Workerman构建PHP WebSocket即时通讯解决方案
- 前端开发利器:SPRjs快速粘合JavaScript文件脚本
- Windows平台RNNoise演示及编译方法说明
- GitHub Action实现站点自动化部署到网格环境
- Delphi实现磁盘容量检测与柱状图展示
- 亲测可用的简易微信抽奖小程序源码分享
- 如何利用JD抢单助手提升秒杀成功率
- 快速部署WordPress:使用Docker和generator-docker-wordpress
- 探索多功能计算器:日志记录与数据转换能力
- WearableSensing: 使用Java连接Zephyr Bioharness数据到服务器
