深度学习笔记:机器翻译、注意力机制与Transformer详解
45 浏览量
更新于2024-08-30
收藏 355KB PDF 举报
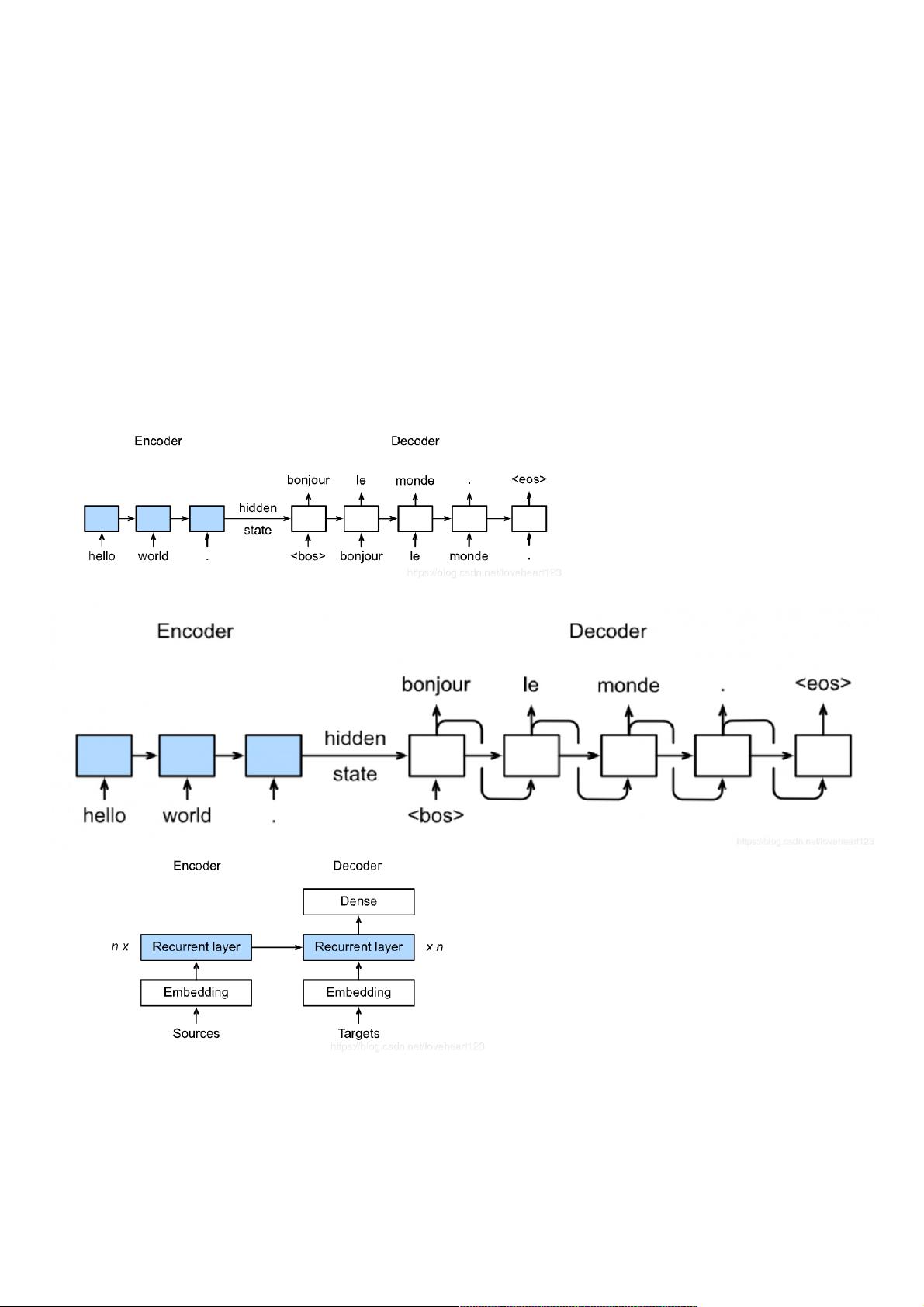
深度学习在机器翻译领域具有重要的地位,本笔记主要涵盖了机器翻译及相关技术、注意力机制与seq2seq模型,以及Transformer模型的学习内容。首先,我们从机器翻译的基础开始,理解SequencetoSequence模型(简称Seq2Seq)是深度学习中用于解决序列到序列问题的核心模型。Seq2Seq模型由编码器(Encoder)和解码器(Decoder)组成,其中:
- **编码器**将源语言的句子转换成固定长度的向量表示,而**解码器**则是基于这个向量逐步生成目标语言的单词。选项A和B是Seq2Seq模型在训练和预测阶段的正确用法:训练时,解码器的输出作为下一个时间步的输入,直到遇到特殊符号(如句子结束符);而在预测时,也是如此。
- 错误选项D提到每个batch的输入需要固定长度,这是不正确的,因为Seq2Seq处理可变长度的输入序列。
接着,笔记讨论了注意力机制,它是提高Seq2seq模型性能的关键。注意力机制允许模型在解码过程中动态关注源序列的不同部分,增强了模型对上下文的理解。注意力机制通过计算每个时间步的注意力权重,使得解码器能根据当前时刻的上下文选择最相关的输入信息。
Transformer模型是基于自注意力机制的革命性设计,它完全放弃了RNN和CNN中的循环结构,使得并行计算成为可能,显著提高了翻译速度。Transformer包含多头注意力机制,自注意力机制,以及前馈神经网络,构建出高效且性能卓越的模型架构。
此外,笔记还提到了几种常见的应用场景,如机器翻译(A、B)、对话机器人和语音识别任务(C、D),指出这些任务通常涉及输入和输出序列长度的可变性,而文本分类任务则不需要Encoder-Decoder结构,因为其输出是固定的类别。
关于搜索算法,集束搜索是Seq2Seq模型在解码阶段常用的优化方法,它结合了贪婪搜索和维特比算法,使用beamsize参数控制搜索范围,以找到更优解。选项A、B和C都准确描述了集束搜索的特点,而选项四错误地认为它总是能找到全局最优解。
最后,数据预处理是机器学习的重要步骤,包括建立词典、分词以及将单词转化为词向量。选项四认为“把单词转化为词向量”不属于数据预处理,这是错误的,因为词向量化是将文本数据转化为机器学习模型可以处理的形式。
本笔记深入浅出地介绍了深度学习在机器翻译中的应用,包括核心模型架构、注意力机制、Transformer模型以及关键的算法和技术细节,对于初学者来说是一份宝贵的参考资料。
《动手学深度学习《动手学深度学习——机器翻译及相关技术,注意力机制与机器翻译及相关技术,注意力机制与seq2seq模模
型,型,Transformer》笔记》笔记
动手学深度学习:机器翻译及相关技术,注意力机制与动手学深度学习:机器翻译及相关技术,注意力机制与seq2seq模型,模型,Transformer
初次学习机器翻译相关,把课程的概念题都记录一下。
目录:目录:
1、机器翻译及相关技术、机器翻译及相关技术
2、注意力机制与、注意力机制与seq2seq模型模型
3、、Transformer
1、机器翻译以及相关技术、机器翻译以及相关技术
1、机器翻译以及相关技术
1、关于Sequence to Sequence模型说法错误的是:
A 训练时decoder每个单元输出得到的单词作为下一个单元的输入单词。
B 预测时decoder每个单元输出得到的单词作为下一个单元的输入单词。
C 预测时decoder单元输出为句子结束符时跳出循环。
D 每个batch训练时encoder和decoder都有固定长度的输入。
选项一:错误,参考Sequence to Sequence训练图示。
选项二:正确,参考Sequence to Sequence预测图示。
选项三:正确,参考Sequence to Sequence预测图示。
选项四:正确,每个batch的输入需要形状一致。
Sequence to Sequence模型模型
模型:模型:
**
训练
预测
具体结构:
不属于Encoder-Decoder应用的是
A 机器翻译
B 对话机器人
C 文本分类任务
D 语音识别任务
注:
Encoder-Decoder常应用于输入序列和输出序列的长度是可变的,如选项一二四,而分类问题的输出是固定的类别,不需要使用Encoder-Decoder
2、关于集束搜索(Beam Search)说法错误的是:
A 集束搜索结合了greedy search和维特比算法。
B 集束搜索使用beam size参数来限制在每一步保留下来的可能性词的数量。
C 集束搜索是一种贪心算法。
D 集束搜索得到的是全局最优解。
选项一:正确,参考视频末尾Beam Search。
选项二:正确,参考视频末尾Beam Search。
下载后可阅读完整内容,剩余3页未读,立即下载
2021-01-06 上传
2021-01-07 上传
点击了解资源详情
点击了解资源详情
2021-01-06 上传
2021-01-06 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38659789
- 粉丝: 4
- 资源: 923
 我的内容管理
展开
我的内容管理
展开







最新资源
- 网上书店可行性分析与需求分析
- C语言编程规范.pdf
- SQL server服务器大内存配置
- 世界上最全的oracle笔记 oracle 资料
- Programming C#
- MIT Linear Programming Courseware- example
- 一份在线考试系统的详细开发文档C#
- 在线考试系统需求说明
- 企业网站推广经合与体会
- convex optimization
- 芯源电子单片机教程(推荐).pdf
- c语言学习300例(实例程序有源码)
- thinking in java
- How to create your library
- Microsoft Windows CE学习资料
- _CC2001教程_研究与思考.pdf
