Python JSON序列化与反序列化详解:实战与库用法
需积分: 0 85 浏览量
更新于2024-08-04
收藏 211KB DOCX 举报
本文将深入探讨Python中的JSON数据序列化与反序列化技术。JSON(JavaScript Object Notation),作为一种轻量级的数据交换格式,因其易读性、简洁性和跨语言兼容性而被广泛采用。在Python中,我们主要依赖`json`库来进行JSON数据的操作。
首先,理解什么是序列化和反序列化至关重要。序列化是指将Python数据结构(如字典或列表)转换为JSON格式的字符串,以便存储或在网络传输过程中保持数据结构。反之,反序列化则是将JSON字符串重新转换回Python对象,以便在程序中使用。Python的`json`库提供了两个核心函数:`dumps()`和`loads()`,用于执行这两种操作。
`json.dumps()`函数接收一个字典参数(如`{'name':'san','age':29}`),并将其转换为JSON字符串,返回值类型为`str`。例如:
```python
import json
a = {'name':'san','age':29}
b = json.dumps(a)
print(b, type(b)) # 输出: '{"name": "san", "age": 29}', <class 'str'>
```
`json.loads()`函数则负责将JSON字符串还原为Python字典对象,其输入为`str`类型,输出为`dict`类型:
```python
print(json.loads(b), type(json.loads(b))) # 输出: {'name': 'san', 'age': 29}, <class 'dict'>
```
然而,`dump()`和`load()`函数提供了更完整的功能,它们不仅支持字符串操作,还可以与文件对象一起工作,实现序列化到文件和从文件反序列化的过程。这些函数的用法如下:
- `json.dump(obj, fp, ...)`:序列化`obj`到文件对象`fp`,如`with open('data.json', 'w') as f: json.dump(a, f)`,会将字典写入名为`data.json`的文件中。
- `json.load(fp, ...)`: 从文件对象`fp`中反序列化数据,如`with open('data.json', 'r') as f: data = json.load(f)`,将读取的JSON数据恢复为Python对象。
此外,`dump()`和`load()`函数还有许多可选参数,如`indent`用于美化输出格式,`encoding`指定文件的字符编码等。这些选项允许用户根据需求定制序列化和反序列化的行为。
Python的`json`库提供了强大的JSON数据操作能力,使得在Python程序中处理JSON数据变得简单易行。掌握这些基本概念和函数,有助于开发人员在实际项目中高效地进行数据交换和持久化存储。
一、关于 JSON
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,易于人阅读和编写.是一种文件规范,绝大多数的编程
语言均可以轻松读写.当然 python 也不例外.
本文要讲的主要是 python 对 JSON 数据的序列化和反序列化.所谓序列化就是写入到文件,反序列化就是从文件中写读到
到程序中成为对应语言的数据类型.
python 数据类型与 JSON 格式的对照表:
Python
JSON
dict
object
list,tuple
array
str,unicode
string
int,long,float
number
True
true
False
false
None
null
二、python 中 json 库与函数
python 通过导入 json 库:import json 来解析操作与序列化 JSON 格式文件.
主要通过两个函数
json.dumps 是将 dict 转化成 str 格式,json.loads 是将 str 转化成 dict 格式。这一对是用来做编码或叫解析与反解析 JSON
数据.注意这里没有写入文件的功能,只是在 python 内部处理.因此这里我习惯叫做解析与反解析.
代码:
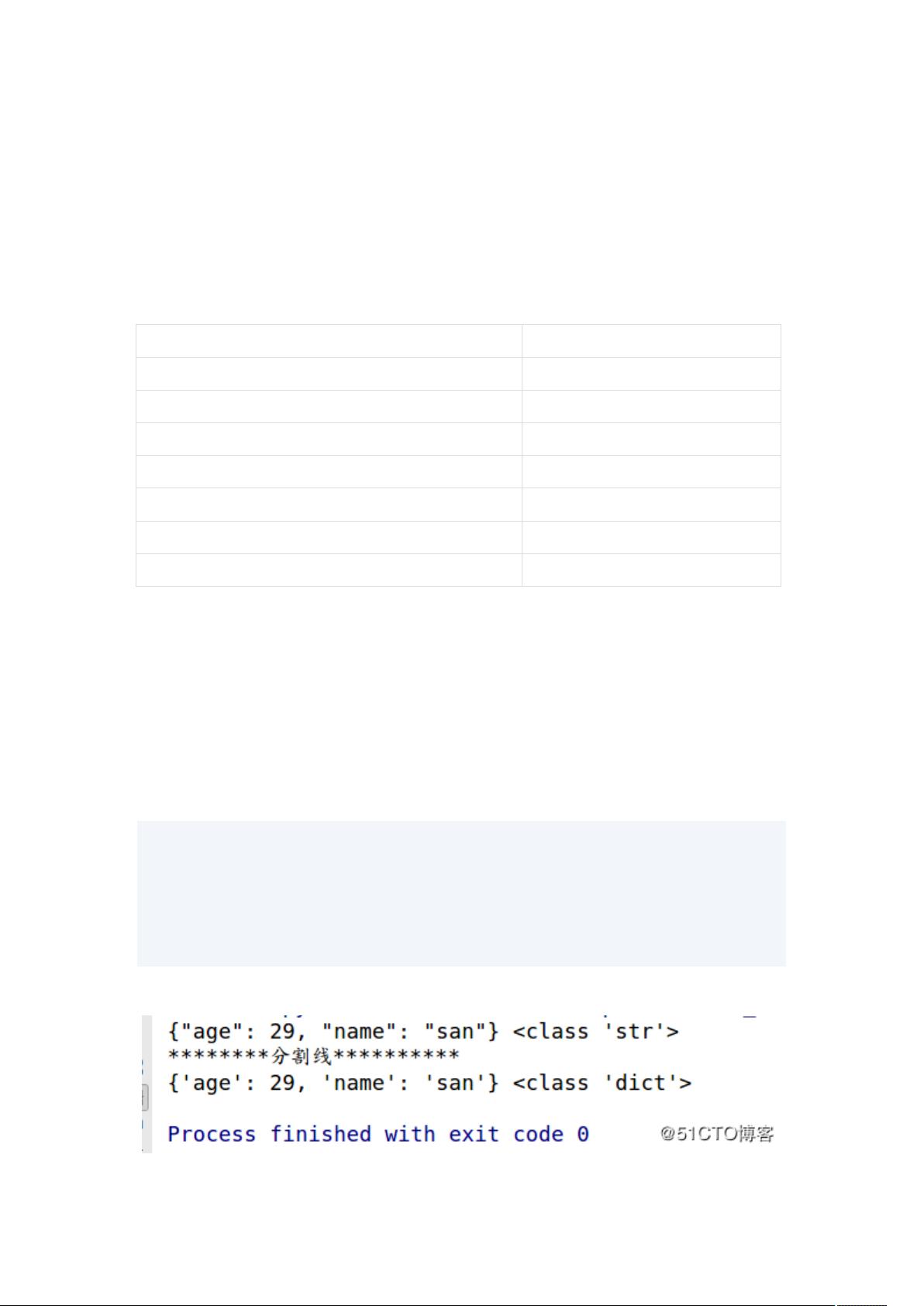
import json
a = {'name': 'san', 'age': 29}
b = json.dumps(a)
print(b, type(b))
print("********分割线**********")
print(json.loads(b),type(json.loads(b)))
输出结果:
下载后可阅读完整内容,剩余4页未读,立即下载
2022-08-03 上传
2021-08-08 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

小埋妹妹
- 粉丝: 30
- 资源: 343
 我的内容管理
展开
我的内容管理
展开







最新资源
- react-mobx-sample:React Mobx示例应用程序
- 行业分类-设备装置-航天器姿态控制系统的间歇性故障容错分析方法.zip
- Timer
- booInvestments.github.io:CS 422 Stratton Oakmont网站
- new1
- Clean WeChat X.exe
- Project3
- MM32SPIN0x(q) 库函数和例程.rar
- tuneout:一个 Apple 脚本,用于将 iTunes 歌曲和艺术家信息写入文本文件,以便与 OBS 流媒体软件的“文件中的文本”功能一起使用。 TuneOut 和 OBS 一起使用,将在流期间显示 iTunes 正在播放的信息
- NASS-SBoH-2021-1-client-server:客户端服务器
- 套接字服务器
- G2M-insight-for-Cab-Investment-firm-
- money-back-guarantee-contract
- 行业分类-设备装置-航天光学遥感器在轨连续调焦的闭环动态仿真测试方法.zip
- Python库 | sqlalchemy_drill-0.2.1.dev0-py3-none-any.whl
- java版商城源码-mgmsmartcity:管理智慧城市
