Hadoop上安装与配置HBase及Java API使用指南
需积分: 50 20 浏览量
更新于2024-09-01
收藏 1003KB DOC 举报
本文档详细介绍了在Hadoop环境中安装HBase以及如何使用Java API进行基本操作,如创建表和数据修改。
在大数据处理领域,分布式数据库HBase是重要的存储解决方案,尤其适用于处理大规模非结构化数据。在Hadoop平台上安装HBase主要包括以下几个步骤:
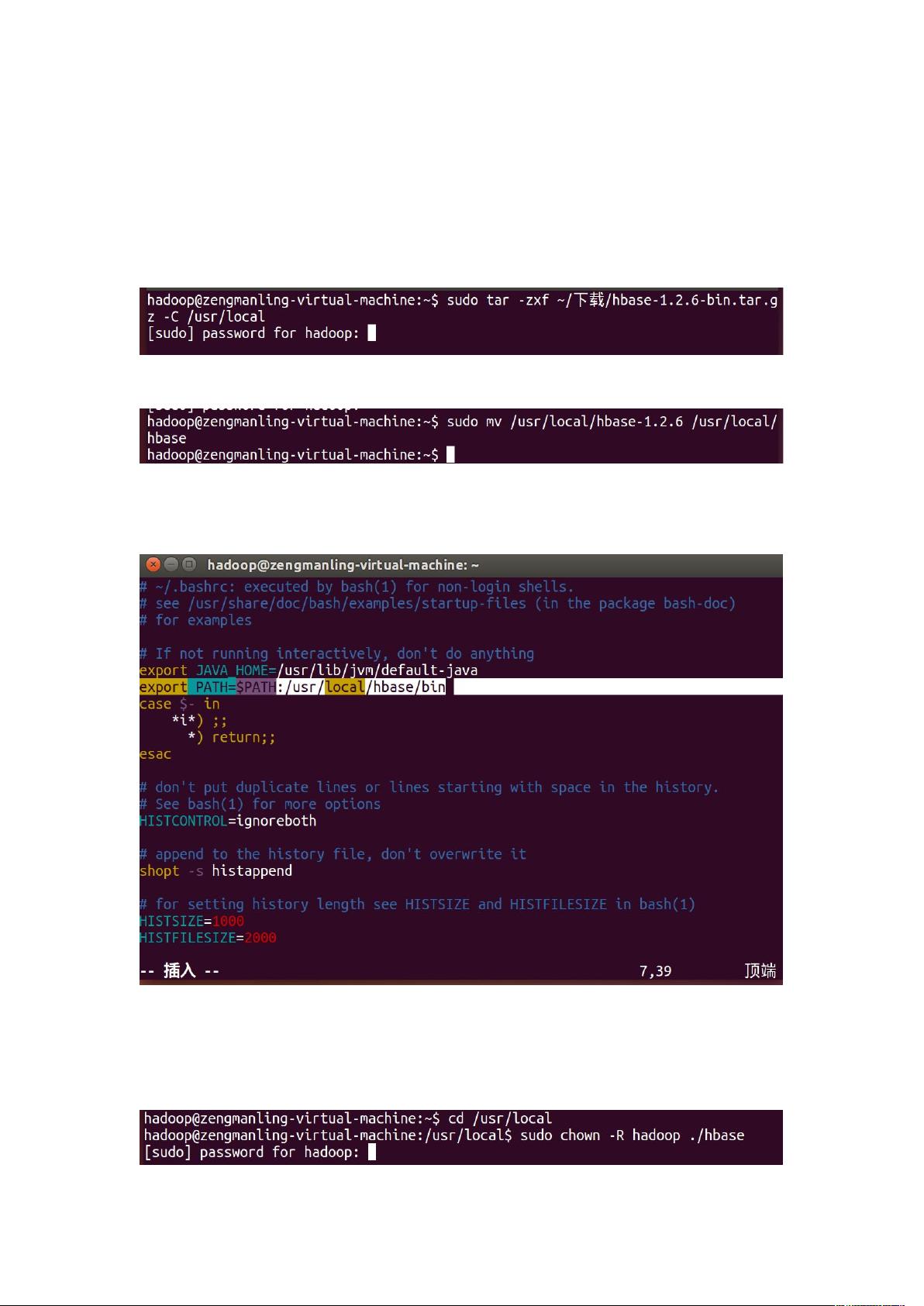
1. 解压安装包:首先,将HBase的安装包`hbase-1.2.6-bin.tar.gz`解压到`/usr/local`目录下,通过执行`sudo tar -zxf ~/下载/hbase-1.2.6-bin.tar.gz -C /usr/local`命令实现。
2. 重命名文件夹:为了方便后续使用,将解压后的文件夹`hbase-1.2.6`改名为`hbase`,使用`sudo mv /usr/local/hbase-1.2.6 /usr/local/hbase`命令完成。
3. 配置环境变量:为了能在系统中任意位置访问HBase,需要更新`bashrc`文件。打开`~/.bashrc`,在文件末尾添加`export PATH=$PATH:/usr/local/hbase/bin`,然后执行`source ~/.bashrc`使其生效。
4. 添加权限:确保Hadoop用户拥有对HBase的访问权限,通过`cd /usr/local`,然后执行`sudo chown -R hadoop ./hbase`命令赋权。
5. 检查HBase版本:运行`/usr/local/hbase/bin/hbase version`来验证HBase是否安装成功,如果显示版本信息,则表明安装完成。
接下来,进行HBase的相关配置:
6. 配置HBase环境变量:编辑`/usr/local/hbase/conf/hbase-env.sh`,设置`JAVA_HOME`环境变量,例如`export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64`,并设置`HBASE_MANAGES_ZK`为`true`,表示HBase管理ZooKeeper。
7. 配置HBase站点文件:编辑`/usr/local/hbase/conf/hbase-site.xml`,配置HBase的数据存储位置,如`<configuration><property><name>hbase.rootdir</name><value>hdfs://localhost:9000/hbase</value></property></configuration>`,这指定了HBase数据在HDFS上的位置。
8. 启动和停止HBase:在配置完成后,通过`cd /usr/local/hbase`切换到HBase目录,然后分别运行`bin/start-hbase.sh`启动HBase,`bin/hbase shell`进入HBase Shell。当需要关闭HBase时,使用`bin/stop-hbase.sh`命令。
在HBase中创建表是通过HBase Shell或Java API完成的。在Shell中,使用`create '表名', '列族名'`命令可以创建一个新表,例如`create 'myTable', 'cf1'`会创建一个名为`myTable`的表,包含一个列族`cf1`。
对于Java API的使用,可以创建一个HBase客户端,然后调用`HTable`类的`put`方法来插入数据,`get`方法来获取数据,以及`delete`方法来删除数据。例如,使用`table.put(new Put('rowKey').add('cf1', 'qualifier', 'value'))`可向表中添加一行数据。
总结来说,安装HBase需要经过解压、配置环境变量、赋权、设置配置文件等步骤,之后可以通过HBase Shell或Java API进行数据操作,如创建表、插入数据等。这在大数据处理中是基础且至关重要的步骤,确保了HBase能够正确地在Hadoop上运行并提供服务。
HBase 创建表与 Java API
1. HBase 安装
解压安装包 hbase-1.2.6-bin.tar.gz 至路径 /usr/local,命令如下:
$ sudo tar -zxf ~/下载/hbase-1.2.6-bin.tar.gz -C /usr/local
将将解压的文件名 hbase-1.2.6 改为 hbase,以方便使用,命令如下:
$ sudo mv /usr/local/hbase-1.2.6 /usr/local/hbase
配置环境变量
(1) 编辑~/.bashrc 文件; $ vi ~/.bashrc
(2) 在~/.bashrc 文件尾行添加; export PATH=$PATH:/usr/local/hbase/bin
(3) 编辑完成后,再执行 source 命令使上述配置在当前终端立即生效;
$ source ~/.bashrc
添加 HBase 权限:
$ cd /usr/local
$ sudo chown -R hadoop ./hbase
下载后可阅读完整内容,剩余3页未读,立即下载
2019-10-17 上传
2020-11-06 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-07-14 上传
2023-07-24 上传

WeAre星巴糯
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 李兴华Java基础教程:从入门到精通
- U盘与硬盘启动安装教程:从菜鸟到专家
- C++面试宝典:动态内存管理与继承解析
- C++ STL源码深度解析:专家级剖析与关键技术
- C/C++调用DOS命令实战指南
- 神经网络补偿的多传感器航迹融合技术
- GIS中的大地坐标系与椭球体解析
- 海思Hi3515 H.264编解码处理器用户手册
- Oracle基础练习题与解答
- 谷歌地球3D建筑筛选新流程详解
- CFO与CIO携手:数据管理与企业增值的战略
- Eclipse IDE基础教程:从入门到精通
- Shell脚本专家宝典:全面学习与资源指南
- Tomcat安装指南:附带JDK配置步骤
- NA3003A电子水准仪数据格式解析与转换研究
- 自动化专业英语词汇精华:必备术语集锦
