Hadoop中的HBase数据库应用案例
发布时间: 2024-02-14 05:26:12 阅读量: 60 订阅数: 33 

hbase 示例
# 1. HBase数据库简介
## 1.1 HBase数据库概述
HBase是一个高可靠性、高性能、可扩展的分布式列式存储数据库。它基于Hadoop文件系统(HDFS)构建,在大数据场景中被广泛应用。HBase具备强大的水平扩展能力,可以容纳海量的数据,并支持实时查询和快速存取。
## 1.2 HBase与传统关系型数据库的区别
HBase与传统的关系型数据库有着明显的区别。传统数据库采用行式存储,而HBase则采用列式存储。列式存储在大数据场景中具备优势,可以提供更高的查询性能和更高的数据压缩比。此外,HBase的数据模型更加灵活,可以以稀疏方式存储数据,并支持动态列族设计。
## 1.3 HBase在Hadoop生态系统中的定位
HBase作为Hadoop生态系统中的一员,扮演着重要的角色。它可以与其他Hadoop组件(如HDFS、MapReduce等)无缝集成,为大数据处理提供可靠的数据存储和实时查询的能力。HBase可以作为Hadoop生态系统中的主要NoSQL解决方案,为企业提供强大的数据存储和分析服务。
# 2. HBase数据库的核心概念
### 2.1 行键(Row Key)的设计原则
在HBase数据库中,行键(Row Key)是数据的唯一标识符。它在HBase表中具有唯一性,并且按照字典排序存储。设计良好的行键可以提高HBase的性能和查询效率。
一般来说,行键的设计应遵循以下原则:
- **唯一性**:行键应该足够唯一,以确保数据的正确区分。一般情况下,可以使用业务相关的唯一标识或者将不同维度的标识进行组合。
- **散列性**:行键的散列性决定了数据在HBase中的分布均匀程度。为了避免热点数据的产生,需要将数据均匀地分散在HBase集群的不同Region上。
- **有序性**:行键的有序性决定了数据在HBase中的存储布局。应尽量选择易于排序的行键,以减少查询时需要扫描的数据量。
### 2.2 列族(Column Family)与列修饰符(Column Qualifier)
在HBase数据库中,数据按照列族(Column Family)进行组织,列族是HBase表的最小单元,同时也是物理存储的最小单元。
每个列族可以包含多个列修饰符(Column Qualifier),列修饰符用于区分不同的数据列。不同列族的数据在存储和查询时是分开处理的,因此在设计时需要根据数据的特性来划分列族。
值得注意的是,一旦列族被创建,就无法删除或修改列族的定义,因此在创建表时需要提前考虑好列族的划分。
### 2.3 版本管理和时间戳
HBase数据库支持数据的版本管理,对于同一行键的多次写入操作,可以保存多个版本的数据。每个版本都有对应的时间戳(Timestamp),并且按照时间戳的逆序进行排序。
版本管理功能可以用于实现数据的版本控制、数据恢复和数据异构性等需求。在实际使用中,需要根据实际情况配置版本数量,以平衡存储空间和查询性能。
### 2.4 HBase数据模型的特点
HBase数据库的数据模型与传统关系型数据库有着显著的区别,主要包括以下特点:
- **稀疏性**:HBase数据库支持对海量数据进行存储和查询,其中很多字段可能是空值,因此可以有效节省存储空间。
- **列式存储**:HBase将同一个列族的多个列存储在一起,方便对该列族进行批量操作,提高查询效率。
- **灵活的架构**:HBase的表结构可以动态调整,可以根据实际需求进行列族的添加和删除,而无需整体重构表。
- **强一致性读写**:HBase数据库保证读写操作的强一致性,读取最新的写入结果。
以上是HBase数据库的核心概念介绍,下一章节将介绍HBase数据库的基本操作。
# 3. HBase数据库的基本操作
HBase作为一个高可靠、高性能、面向列的分布式存储系统,在大数据领域有着广泛的应用。本章将介绍HBase数据库的基本操作,包括安装与配置、HBase Shell的基本使用以及HBase客户端编程接口。
#### 3.1 HBase数据库的安装与配置
在开始HBase数据库的基本操作之前,首先需要完成HBase数据库的安装与配置。以下是安装HBase的基本步骤:
- 下载HBase安装包
- 解压安装包到指定目录
- 配置HBase环境变量
- 修改HBase配置文件
- 启动HBase集群
#### 3.2 HBase Shell的基本使用
HBase自带了一个交互式的Shell工具,可以方便地进行HBase数据库的管理和操作。以下是HBase Shell的基本使用:
- 连接HBase数据库
- 创建表
- 插入数据
- 查询数据
- 更新数据
- 删除数据
- 删除表
- 退出HBase Shell
```shell
# 连接HBase数据库
hbase shell
# 创建表
create 'student', 'info', 'score'
# 插入数据
put 'student', '001', 'info:name', 'Tom'
put 'student', '001', 'info:age', '18'
put 'student', '001', 'score:math', '85'
# 查询数据
get 'student', '001'
# 更新数据
put 'student', '001', 'info:age', '19'
# 删除数据
delete 'student', '001', 'info:age'
# 删除表
disable 'student'
drop 'student'
# 退出HBase Shell
exit
```
#### 3.3 HBase客户端编程接口
除了使用HBase Shell进行操作外,我们也可以通过HBase提供的Java客户端编程接口来进行数据库的操作。以下是一个简单的Java客户端示例:
```java
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
public class HBaseClient {
public static void main(String[] args) throws Exception {
Configuration conf = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(conf);
TableName tableName = TableName.valueOf("student");
Table table = connection.getTable(tableName);
// 插入数据
Put put = new Put(Bytes.toBytes("001"));
put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes("Tom"));
put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("age"), Bytes.toBytes("18"));
put.addColumn(Bytes.toBytes("score"), Bytes.toBytes("math"), Bytes.toBytes("85"));
table.put(put);
// 查询数据
Get get = new Get(Bytes.toBytes("001"));
Result result = table.get(get);
System.out.println("查询结果:" + result);
table.close();
connection.close();
}
}
```
以上就是HBase数据库的基本操作的一些内容。接下来,我们将继续探讨HBase数据库的应用案例。
# 4. HBase数据库的应用案例
HBase数据库是一种高可靠、高可扩展的分布式数据库,广泛应用于各种大数据场景中。本章将介绍HBase数据库在实际应用中的几个案例。
#### 4.1 实时日志分析系统
实时日志分析是HBase数据库的一个常见应用场景之一。在这个案例中,我们将使用HBase来存储和分析实时产生的日志数据

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
该专栏是一个关于Python、Hadoop和Spark的教程和实际应用案例的平台。读者将通过专栏内的一系列文章,深入了解各种主题,如Python数据处理与分析、Python网络爬虫实战、Hadoop中的Hive数据仓库应用等等。这些教程将提供深入解析和实际案例,让读者能够快速掌握相关技能和知识。例如,读者将学习如何使用Pandas库进行数据处理和分析,如何使用BeautifulSoup和Scrapy进行网络爬虫,如何在Hadoop中应用Hive和HBase数据库,以及如何在Spark中实践分布式机器学习算法。此外,专栏还介绍了Python与数据库交互应用开发的实例。通过这些教程和案例,读者能够全面了解和应用Python、Hadoop和Spark在实际项目中的价值和应用。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
STM32时钟系统:快速上手手册中的时钟树配置
# 摘要
本文全面探讨了STM32微控制器的时钟系统,包括其基本架构、配置实践、性能优化和进阶应用。首先介绍了STM32的时钟系统概述和时钟树结构,详细分析了内部与外部时钟源、分频器的作用、时钟树各主要分支的功能以及时钟安全系统(CSS)。接着,重点阐述了时钟树的配置方法,包括使用STM32CubeMX工具和编程实现时钟树配置,以及如何验证和调试时钟设置。文章进一步讨论了时钟
【散列表深入探索】:C++实现与实验报告的实用技巧
/i.s3.glbimg.com/v1/AUTH_08fbf48bc0524877943fe86e43087e7a/internal_photos/bs/2021/K/I/bjyAPxSdOTDlaWv7Ajhw/2015-01-30-gpc20150130-1.jpg)
# 摘要
本文全面探讨了散列表的基础理论及其在C++中的实现。首先介绍了散列表的结构定
【IAR嵌入式系统新手速成课程】:一步到位掌握关键入门技能!
# 摘要
本文介绍了IAR嵌入式系统的安装、配置及编程实践,详细阐述了ARM处理器架构和编程要点,并通过实战项目加深理解。文章首先提供了IAR Embedded Workbench的基础介绍,包括其功能特点和安装过程。随后深入讲解了ARM处理器的基础知识,实践编写汇编语言,并探讨了C语言与汇编的混合编程技巧。在编程实践章节中,回顾了C语言基础,使用IAR进行板级支持包的开发,并通过一个实战项目演示了嵌入式系统的开发流程。最后,本文探讨了高级功能,如内存管理和性能优化,调试技术,并通过实际案例来解决常见问题。整体而言,本文为嵌入式系统开发人员提供了一套完整的技术指南,旨在提升其开发效率和系统性能
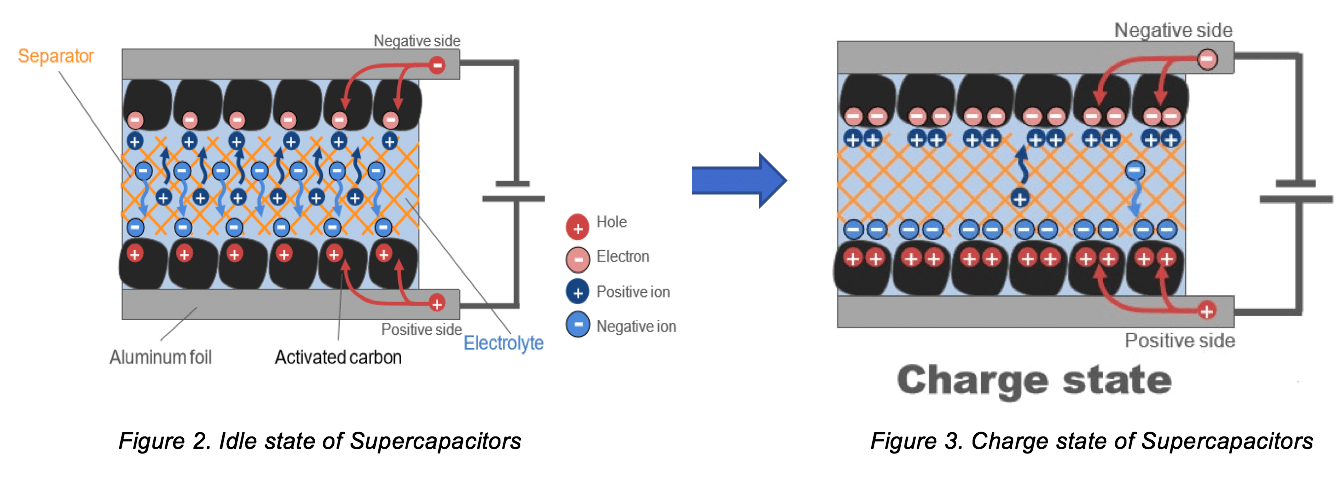
超级电容充电技术大揭秘:全面解析9大创新应用与优化策略
# 摘要
超级电容器作为能量存储与释放的前沿技术,近年来在快速充电及高功率密度方面显示出巨大潜力。本文系统回顾了超级电容器的充电技术,从其工作原理、理论基础、充电策略、创新应用、优化策略到实践案例进行了深入探讨。通过对能量回收系统、移动设备、大型储能系统中超级电容器应用的分析,文章揭示了充电技术在不同领域中的实际效益和优化方向。同时,本文还展望了固态超级电容器等新兴技术的发展前景以及超级电
PHY6222蓝牙芯片节电大作战:延长电池续航的终极武器

# 摘要
本文全面介绍了PHY6222蓝牙芯片的特性、功耗分析和节电策略,以及其在实际项目中的应用和未来展望。首先概述了蓝牙技术的发展历程和PHY6222的技术特点。随后,深入探讨了蓝牙技术的功耗问题,包括能耗模式的分类、不同模式下的功耗比较,以及功耗分析的实践方法。文章接着讨论了PHY6222蓝牙芯片的节电策略,涵盖节电模式配置、通信协议优化和外围设备管理。在实际应用部分,文章分析了PHY6222在物联网设备和移动
传感器集成全攻略:ICM-42688-P运动设备应用详解

# 摘要
ICM-42688-P传感器作为一种先进的惯性测量单元,广泛应用于多种运动设备中。本文首先介绍了ICM-42688-P传感器的基本概述和技术规格,然后深入探讨了其编程基础,包括软件接口、数据读取处理及校准测试。接着,本文详细分析了该传感器在嵌入式系统、运动控制和人机交互设备中的实践应用,并且探讨了高级功能开发,
【HDL编写在Vivado中的艺术】:Verilog到VHDL转换的绝技

# 摘要
Vivado是Xilinx公司推出的用于设计FPGA和SOC的集成设计环境,而硬件描述语言(HDL)是其设计基础。本文首先介绍了Vi
【声子晶体模拟全能指南】:20年经验技术大佬带你从入门到精通
# 摘要
声子晶体作为一种具有周期性结构的材料,在声学隐身、微波和红外领域具有广泛的应用潜力。本文从基础理论出发,深入探讨了声子晶体的概念、物理模型和声子带结构的理论解析,同时介绍了声子晶体的数值模拟方法,包括有限元方法(FEM)、离散元方法(DEM)和分子动力学(MD)。本文还提供了一套完整的声子晶体模拟实践指南,涵盖了模拟前的准备工作、详细的模拟步骤以及结果验证和案例分析。此外,文章探讨了声子晶体模拟的高级技巧和拓展
Origin脚本编写:提升绘图效率的10大秘诀
# 摘要
Origin是一款广泛应用于数据处理和科学绘图的软件,其脚本编写能力为用户提供了强大的自定义和自动化分析工具。本文从Origin脚本编写概述开始,逐步深入讲解了基础语法、数据处理、图表自定义、以及实战技巧。接着,文章探讨了进阶应用,包括错误处理、自定义函数、图形用户界面(GUI)的设计,以及优化脚本性能的关键技术。最后,通过多学科应用案例研究,展示了Origi
DSP28335在逆变器中的应用:SPWM波形生成与性能优化全解

# 摘要
本论文首先概述了DSP28335微控制器的特点及其在逆变器中的应用。接着详细介绍了正弦脉宽调制(SPWM)波形生成的理论基础,包括其基本原理、关键参数以及实现算法。文章进一步深入探讨了DSP28335如何编程实践实现SPWM波形生成,并提供了编程环境配置、程序设计及调试测试的具体方法。此外,还分析了基于DSP28335的逆变器性能优化策略,涉及性能评估指
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )