Python数据处理与分析:Pandas库深入解析
发布时间: 2024-02-14 04:58:01 阅读量: 49 订阅数: 36 

Python进阶-Pandas数据分析库
# 1. 简介
## **介绍Python数据处理与分析的重要性**
在大数据时代,数据处理和分析已经成为各行各业的重要环节。随着数据量的不断增大和数据种类的不断增多,如何高效地处理和分析数据成为了每个数据专业人士的核心任务。Python作为一种功能强大的编程语言,具备了丰富的数据处理和分析工具,大大简化了这个任务。Python的处理和分析库之一就是Pandas。
## **引入Pandas库的背景和作用**
Pandas是Python中常用的数据分析和处理库。它使用NumPy作为基础,提供了高性能、易用且灵活的数据结构,使得数据的清洗、转换、统计和分析变得非常简单。Pandas库的引入,不仅使得数据处理和分析更加便捷高效,同时也促进了Python在数据科学领域的广泛应用。
接下来,我们将深入介绍Pandas库的特点和优势,并详细讲解其常用的数据结构:Series和DataFrame。
# 2. Pandas库简介
Pandas 是基于 NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。Pandas提供了大量能使我们快速便捷地处理数据的函数和方法,使得数据的清洗、转换、分析等工作变得更加简单。
### Pandas库的特点和优势
- 易于数据导入和导出:无论是从csv文件,Excel表格,数据库中导入数据,还是导出到这些文件格式,Pandas都提供了非常方便的函数和工具。
- 数据清洗和处理:Pandas库提供了丰富的功能来处理缺失值、异常值、重复值等问题,同时还能进行数据的规整和清洗。
- 灵活的数据结构:Pandas中的Series和DataFrame数据结构能够满足复杂数据处理和分析的需求,而且能够进行索引、切片、聚合等操作。
- 强大的数据分析能力:Pandas内置了许多统计和分析方法,能够对数据进行统计描述、聚合分析、数据透视表等操作。
- 丰富的可视化功能:Pandas可以结合其它可视化库(如Matplotlib)进行数据可视化,快速生成图表,直观展示数据分析结果。
### Pandas库的数据结构:Series和DataFrame
- Series:是一维带标签数组,能够保存任何数据类型,其标签可以定制或默认。Series对象由一组数据和与之相关的数据标签(即索引)组成。
- DataFrame:是由数据以行和列的形式组成的,是Pandas中最常用的数据结构。DataFrame既有行索引,也有列索引,可以看作是Series对象的字典。
Pandas库通过这两种数据结构提供了丰富的数据处理和分析能力,使得数据科学家和分析师能够轻松地进行数据处理和分析工作。
```python
# 代码示例
import pandas as pd
# 创建一个Series
s = pd.Series([1, 3, 5, 7, 9])
print(s)
# 创建一个DataFrame
data = {'Name': ['Tom', 'Jerry', 'Mickey', 'Minnie'],
'Age': [25, 30, 35, 40]}
df = pd.DataFrame(data)
print(df)
```
在上面的示例中,我们创建了一个Series和一个DataFrame,展示了Pandas库中两种最常用的数据结构。接下来,我们将介绍如何使用Pandas库进行数据的读取与写入。
# 3. 数据读取与写入
在数据处理与分析中,读取和写入数据是一个非常重要的环节。Pandas库提供了丰富的方法和功能,可以方便地读取和写入各种不同格式的数据文件。
#### 3.1 使用Pandas库读取不同格式的数据文件
Pandas库支持读取多种常用的数据文件格式,包括CSV、Excel、SQL、JSON等。下面我们将介绍如何使用Pandas库进行数据文件的读取。
##### 3.1.1 读取CSV文件
CSV(Comma-Separated Values)是一种常见的文本文件格式,数据以逗号作为分隔符进行存储。通过`read_csv()`方法可以读取CSV文件,并将数据转化为DataFrame对象。
```python
import pandas as pd
df = pd.read_csv('data.csv')
print(df)
```
上述代码会读取名为"data.csv"的CSV文件,并将数据存储在DataFrame对象df中。读取的结果可以通过打印df来查看。
##### 3.1.2 读取Excel文件
Excel是一种常用的电子表格文件格式,它可以存储大量的数据和多个工作表。使用`read_excel()`方法可以读取Excel文件,并将其中的数据转化为DataFrame对象。
```python
import pandas as pd
df = pd.read_excel('data.xlsx')
print(df)
```
上述代码会读取名为"data.xlsx"的Excel文件,并将数据存储在DataFrame对象df中。读取的结果可以通过打印df来查看。
##### 3.1.3 读取SQL数据库
如果数据存储在SQL数据库中,可以使用Pandas库提供的`read_sql()`方法进行读取。首先需要创建一个SQL连接对象,然后使用`read_sql()`方法传入SQL语句和连接对象来读取数据。
```python
import pandas as pd
import sqlite3
# 创建SQL连接对象
conn = sqlite3.connect('data.db')
# 读取数据
df = pd.read_sql('SELECT * FROM table_name', conn)
print(df)
# 关闭连接
conn.close()
```
上述代码中需先创建一个名为"data.db"的SQLite数据库文件,并创建SQL连接对象conn。然后通过传入SQL语句和连接对象来读取数据,并将数据存储在DataFrame对象df中。
##### 3.1.4 读取JSON文件
JSON(JavaScript Object Notation)是一种常用的数据交换格式,与Python中的字典非常相似。使用`read_json()`方法可以读取JSON文件,并将数据转化为DataFrame对象。
```python
import pandas as pd
df = pd.read_json('data.json')
print(df)
```
上述代码会读取名为"data.json"的JSON文件,并将数据存储在DataFrame对象df中。读取的结果可以通过打印df来查看。
#### 3.2 数据读取过程中常用的参数和方法
在使用Pandas库读取数据的过程中,我们还可以通过一些参数和方法来灵活地控制和处理数据。
##### 3.2.1 参数设置
- `header`:指定数据文件中作为列名的行数,默认为0,即使用文件中的第一行作为列名。
- `sep`:指定数据的分隔符,默认为逗号(适用于CSV文件),也可以是其他字符或字符串。
- `index_col`:指定作为行索引的列,默认为None,表示使用默认的行索引。
- `skiprows`:跳过指定的行数或行索引。
- `nrows`:指定读取的行数。
##### 3.2.2 方法应用
- `head(n)`:查看前n行数据;如果不传入参数,默认查看前5行数据。
- `tail(n)`:查看后n行数据;如果不传入参数,默认查看后5行数据。
- `info()`:查看数据的基本信息,包括列名、数据类型、非空值的数量等。
- `describe()`:生成描述性统计信息,包括计数、均值、标准差、最小值、最大值等。
- `sample(n)`:随机抽样n行数据。
#### 3.3 将数据写入不同格式的文件
除了读取数据,Pandas库也支持将数据写入不同格式的文件。可以使用`to_csv()`、`to_excel()`、`to_sql()`和`to_json()`等方法进行数据写入。
```python
import pandas as pd
# 将数据写入CSV文件
df.to_csv('result.csv', index=False)
# 将数据写入Excel文件
df.to_excel('result.xlsx', index=False)
# 将数据写入SQL数据库
conn = sqlite3.connect('result.db')
df.to_sql('table_name', conn, if_exists='replace', index=False)
conn.close()
# 将数据写入JSON文件
df.to_json('result.json', orient='records')
```
上述代码分别将DataFrame对象df中的数据写入了一个名为"result.csv"的CSV文件、一个名为"result.xlsx"的Excel文件、一个名为"result.db"的SQL数据库和一个名为"result.json"的JSON文件。
通过Pandas库的读取和写入功能,我们可以方便地获取和处理不同格式的数据,并进行下一步的数据清洗与处理、数据分析与统计以及数据可视化与报告等工作。
#### 总结
本章介绍了Pandas库在数据读取和写入方面的基本用法。通过使用Pandas库提供的方法和功能,我们可以轻松地读取不同格式的数据文件,包括CSV、Excel、SQL和JSON等。同时,也可以将数据写入到不同格式的文件中,以方便后续的数据分析与处理工作。
# 4. 数据清洗与处理
数据清洗和处理是数据分析过程中非常重要的一环。使用Pandas库可以方便地进行数据清洗和处理操作,对于数据中的缺失值、重复值和异常值进行处理,以确保数据的完整性和准确性。
##### 4.1 数据的缺失值处理
在实际数据分析过程中,经常会遇到数据缺失的情况,即部分数据项的值为NaN(Not a Number)。这些缺失值对于数据分析和建模是不可忽视的,需要进行相应的处理。
在Pandas库中,使用`isna()`方法可以判断数据中的缺失值。针对缺失值,可以选择以下几种常见的处理方法:
- 删除缺失值:使用`dropna()`方法可以删除包含缺失值的行或列。
``` python
# 删除含有缺失值的行
df.dropna(axis=0, inplace=True)
# 删除含有缺失值的列
df.dropna(axis=1, inplace=True)
```
- 填充缺失值:使用`fillna()`方法可以对缺失值进行填充,可以选择填充固定值或使用统计指标进行填充。
``` python
# 使用固定值填充
df.fillna(value=0, inplace=True)
# 使用均值填充
df.fillna(df.mean(), inplace=True)
```
##### 4.2 数据的重复值处理
除了缺失值外,数据中的重复值也需要进行处理,以避免干扰数据分析和模型建立的准确性。
在Pandas库中,使用`duplicated()`方法可以判断数据中的重复值。针对重复值,可以选择以下几种常见的处理方法:
- 删除重复值:使用`drop_duplicates()`方法可以删除数据中的重复值。
``` python
# 删除重复行
df.drop_duplicates(inplace=True)
```
- 替换重复值:使用`replace()`方法可以将重复值替换为其他值。
``` python
# 将重复值替换为指定值
df.replace({"重复值": "新值"}, inplace=True)
```
##### 4.3 数据的异常值处理
在数据分析过程中,往往需要对数据中的异常值进行处理,以便于准确分析和建模。
在Pandas库中,可以使用以下方法对异常值进行处理:
- 删除异常值:使用条件过滤和`drop()`方法可以删除符合条件的异常值。
``` python
# 删除大于阈值的异常值
df = df[df["数值列"] < 阈值]
```
- 替换异常值:使用条件过滤和`replace()`方法可以替换符合条件的异常值为其他值。
``` python
# 将大于阈值的异常值替换为指定值
df["数值列"] = df["数值列"].replace(df[df["数值列"] > 阈值], 替换值)
```
综上所述,数据清洗和处理是数据分析过程中不可或缺的环节,通过Pandas库提供的方法,可以方便地处理数据中的缺失值、重复值和异常值,以确保数据的准确性和完整性。通过合适的数据处理方法,可以为后续的数据分析和建模提供可靠的数据基础。
# 5. 数据分析与统计
数据分析是数据处理与挖掘的重要环节,Pandas库提供了丰富的功能来进行数据分析与统计,包括数据的筛选和切片、数据的聚合和分组、数据的排序和排名以及数据的插值和填充等操作。
#### 5.1 数据的筛选和切片
Pandas库允许通过条件筛选来选择数据,这可以通过布尔索引来实现。例如,可以使用条件表达式对DataFrame进行筛选:
```python
import pandas as pd
# 创建示例DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Age': [25, 30, 35, 40],
'Score': [85, 92, 88, 95]}
df = pd.DataFrame(data)
# 筛选年龄大于30的数据
filtered_data = df[df['Age'] > 30]
print(filtered_data)
```
此外,Pandas还提供了iloc和loc等方法进行位置或标签的切片,以实现对数据的灵活定位和切割。
#### 5.2 数据的聚合和分组
Pandas库支持对数据进行聚合运算,比如求和、平均值、计数等,同时也提供了强大的分组功能。可以使用groupby方法来对数据进行分组,然后进行聚合运算:
```python
# 对数据按照年龄分组,并计算每组的平均分数
grouped_data = df.groupby('Age')['Score'].mean()
print(grouped_data)
```
#### 5.3 数据的排序和排名
Pandas库能够轻松地对数据进行排序和排名操作,使用sort_values方法可以按指定列对数据进行排序:
```python
# 按照分数对数据进行降序排序
sorted_data = df.sort_values(by='Score', ascending=False)
print(sorted_data)
```
另外,使用rank方法可以对数据进行排名,得到排名结果:
```python
# 对分数进行排名
ranked_data = df['Score'].rank(ascending=False)
print(ranked_data)
```
#### 5.4 数据的插值和填充
在数据处理过程中,经常会遇到缺失值需要进行插值或填充。Pandas库提供了fillna方法来填充缺失值,以及interpolate方法来进行插值操作:
```python
# 用平均值填充缺失的年龄
df['Age'].fillna(df['Age'].mean(), inplace=True)
print(df)
# 对分数进行线性插值
df['Score'].interpolate(method='linear', inplace=True)
print(df)
```
通过这些功能,Pandas库使得数据分析和统计变得更加高效和灵活,提高了数据处理的效率和准确性。
# 6. 可视化与报告
在数据处理与分析的过程中,可视化是一种非常重要的手段,能够直观地呈现数据的特征和规律。Pandas库提供了丰富的可视化方法,同时也可以与其他可视化库(如Matplotlib、Seaborn)结合使用,以满足不同的可视化需求。此外,Pandas库还支持生成报告和分析结果的自动化脚本,方便用户输出分析成果。
#### 6.1 使用Pandas库绘制数据可视化图表
Pandas库内置了多种数据可视化方法,例如折线图、柱状图、散点图等,可以直接对Series和DataFrame对象进行绘图。以下是一个简单的示例,演示如何使用Pandas库绘制柱状图:
```python
import pandas as pd
import matplotlib.pyplot as plt
# 创建示例数据
data = {'name': ['Tom', 'Jerry', 'Mickey', 'Minnie', 'Donald'],
'score': [85, 72, 90, 68, 77]}
df = pd.DataFrame(data)
# 绘制柱状图
df.plot(x='name', y='score', kind='bar', rot=45)
plt.title('Students\' Scores')
plt.xlabel('Name')
plt.ylabel('Score')
plt.show()
```
上述代码中,我们首先创建了一个包含学生姓名和成绩的DataFrame,然后使用`plot`方法绘制了柱状图,展示了每位学生的成绩情况。
除了柱状图之外,Pandas还支持绘制多种类型的图表,如折线图、饼图、箱线图等,用户可以根据需求选择合适的图表类型来展示数据。
#### 6.2 利用Pandas库生成报告和分析结果的自动化脚本
Pandas库结合了数据处理、分析和可视化的功能,使得用户能够通过编写脚本自动化地完成数据处理与分析的过程,并输出相应的报告和结果。利用Pandas库,用户可以在脚本中进行数据清洗、统计分析、图表绘制等操作,最终将分析结果输出为报告或特定格式的文件,例如PDF、Excel、HTML等。
以下是一个简单的示例,展示了如何使用Pandas库自动化地生成分析报告:
```python
import pandas as pd
import numpy as np
from pandas_profiling import ProfileReport
# 读取数据集
data = pd.read_csv('data.csv')
# 数据清洗与处理
# ...(省略数据清洗与处理的代码)...
# 数据统计与分析
# ...(省略数据统计与分析的代码)...
# 生成报告
report = ProfileReport(data)
report.to_file('analysis_report.html')
```
上述代码中,我们使用了Pandas库结合第三方库`pandas_profiling`,通过`ProfileReport`方法自动生成了数据集的分析报告,并将报告保存为HTML文件。通过这样的脚本,用户可以快速、高效地生成数据分析报告,提高工作效率。
#### 6.3 Pandas库与其他可视化库的结合应用
除了Pandas库内置的可视化功能外,Pandas库还可以与其他可视化库(如Matplotlib、Seaborn)结合使用,以实现更加复杂和多样化的数据可视化。使用Pandas库与其他可视化库结合的方式,能够充分发挥各库的优势,实现更个性化、专业化的数据展示。
以下是一个示例,演示了Pandas库与Matplotlib库结合绘制一个折线图的过程:
```python
import pandas as pd
import matplotlib.pyplot as plt
# 创建示例数据
data = {'year': [2010, 2011, 2012, 2013, 2014],
'sales': [450, 500, 520, 600, 550]}
df = pd.DataFrame(data)
# 使用Matplotlib绘制折线图
plt.plot(df['year'], df['sales'], marker='o')
plt.title('Sales Trend')
plt.xlabel('Year')
plt.ylabel('Sales ($)')
plt.show()
```
在上述示例中,我们使用Pandas库创建了一个包含年份和销售额的DataFrame,然后利用Matplotlib库的`plot`方法绘制了折线图,展示了销售额随年份变化的趋势。
通过Pandas库与其他可视化库的结合应用,用户可以充分发挥不同库的特点,实现更加灵活、丰富的数据可视化效果。
综上所述,Pandas库在数据可视化和报告生成方面具有丰富的功能和灵活性,为用户提供了强大的工具支持,能够满足不同领域、不同应用场景下的数据展示需求。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
该专栏是一个关于Python、Hadoop和Spark的教程和实际应用案例的平台。读者将通过专栏内的一系列文章,深入了解各种主题,如Python数据处理与分析、Python网络爬虫实战、Hadoop中的Hive数据仓库应用等等。这些教程将提供深入解析和实际案例,让读者能够快速掌握相关技能和知识。例如,读者将学习如何使用Pandas库进行数据处理和分析,如何使用BeautifulSoup和Scrapy进行网络爬虫,如何在Hadoop中应用Hive和HBase数据库,以及如何在Spark中实践分布式机器学习算法。此外,专栏还介绍了Python与数据库交互应用开发的实例。通过这些教程和案例,读者能够全面了解和应用Python、Hadoop和Spark在实际项目中的价值和应用。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
VisionPro故障诊断手册:网络问题的系统诊断与调试

# 摘要
网络问题诊断与调试是确保网络高效、稳定运行的关键环节。本文从网络基础理论与故障模型出发,详细阐述了网络通信协议、网络故障的类型及原因,并介绍网络故障诊断的理论框架和管理工具。随后,本文深入探讨了网络故障诊断的实践技巧,包括诊断工具与命令、故障定位方法以及
【Nginx负载均衡终极指南】:打造属于你的高效访问入口
.webp)
# 摘要
Nginx作为一款高性能的HTTP和反向代理服务器,已成为实现负载均衡的首选工具之一。本文首先介绍了Nginx负载均衡的概念及其理论基础,阐述了负载均衡的定义、作用以及常见算法,进而探讨了Nginx的架构和关键组件。文章深入到配置实践,解析了Nginx配置文件的关键指令,并通过具体配置案例展示了如何在不同场景下设置Nginx以实现高效的负载分配。
云计算助力餐饮业:系统部署与管理的最佳实践
# 摘要
云计算作为一种先进的信息技术,在餐饮业中的应用正日益普及。本文详细探讨了云计算与餐饮业务的结合方式,包括不同类型和部署模型的云服务,并分析了其在成本效益、扩展性、资源分配和高可用性等方面的优势。文中还提供餐饮业务系统云部署的实践案例,包括云服务选择、迁移策略以及安全合规性方面的考量。进一步地,文章深入讨论了餐饮业务云管理与优化的方法,并通过案例研究展示了云计算在餐饮业中的成功应用。最后,本文对云计算在餐饮业中
【Nginx安全与性能】:根目录迁移,如何在保障安全的同时优化性能
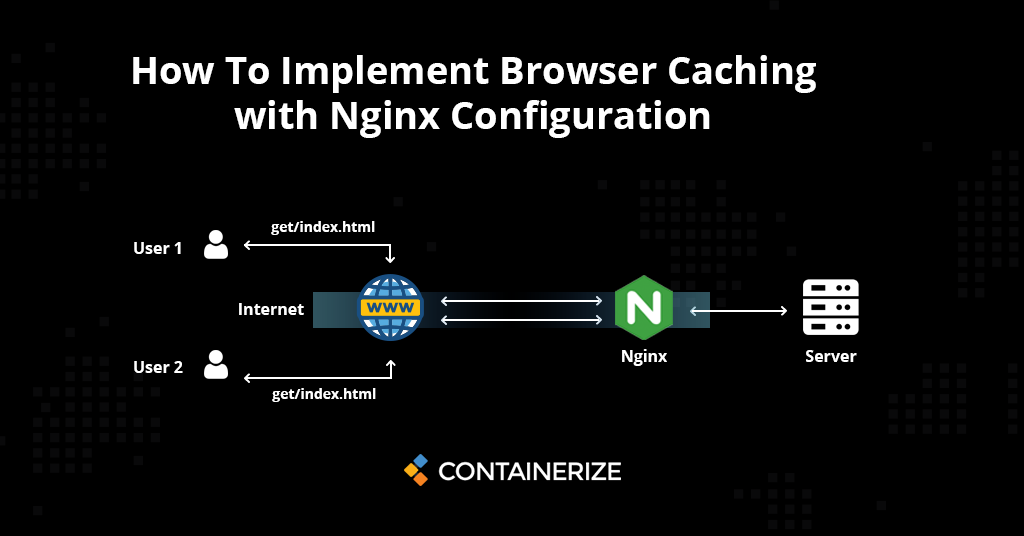
# 摘要
本文对Nginx根目录迁移过程、安全性加固策略、性能优化技巧及实践指南进行了全面的探讨。首先概述了根目录迁移的必要性与准备步骤,随后深入分析了如何加固Nginx的安全性,包括访问控制、证书加密、
RJ-CMS主题模板定制:个性化内容展示的终极指南

# 摘要
本文详细介绍了RJ-CMS主题模板定制的各个方面,涵盖基础架构、语言教程、最佳实践、理论与实践、高级技巧以及未来发展趋势。通过解析RJ-CMS模板的文件结构和继承机制,介绍基本语法和标签使用,本文旨在提供一套系统的方法论,以指导用户进行高效和安全的主题定制。同时,本文也探讨了如何优化定制化模板的性能,并分析了模板定制过程中的高级技术应用和安全性问题。最后,本文展望了RJ-CMS模板定制的
【板坯连铸热传导进阶】:专家教你如何精确预测和控制温度场

# 摘要
本文系统地探讨了板坯连铸过程中热传导的基础理论及其优化方法。首先,介绍了热传导的基本理论和建立热传导模型的方法,包括导热微分方程及其边界和初始条件的设定。接着,详细阐述了热传导模型的数值解法,并分析了影响模型准确性的多种因素,如材料热物性、几何尺寸和环境条件。本文还讨论了温度场预测的计算方法,包括有限差分法、有限元法和边界元法,并对温度场控制技术进行了深入分析。最后,文章探讨了温度场优化策略、
【性能优化大揭秘】:3个方法显著提升Android自定义View公交轨迹图响应速度

# 摘要
本文旨在探讨Android自定义View在实现公交轨迹图时的性能优化。首先介绍了自定义View的基础知识及其在公交轨迹图中应用的基本要求。随后,文章深入分析了性能瓶颈,包括常见性能问题如界面卡顿、内存泄漏,以及绘制过程中的性能考量。接着,提出了提升响应速度的三大方法论,包括减少视图层次、视图更新优化以及异步处理和多线程技术应用。第四章通过实践应用展示了性能优化的实战过程和
Python环境管理:一次性解决Scripts文件夹不出现的根本原因

# 摘要
本文系统地探讨了Python环境的管理,从Python安装与配置的基础知识,到Scripts文件夹生成和管理的机制,再到解决环境问题的实践案例。文章首先介绍了Python环境管理的基本概念,详细阐述了安装Python解释器、配置环境变量以及使用虚拟环境的重要性。随
通讯录备份系统高可用性设计:MySQL集群与负载均衡实战技巧

# 摘要
本文探讨了通讯录备份系统的高可用性架构设计及其实际应用。首先对MySQL集群基础进行了详细的分析,包括集群的原理、搭建与配置以及数据同步与管理。随后,文章深入探讨了负载均衡技术的原理与实践,及其与MySQL集群的整合方法。在此基础上,详细阐述了通讯录备份系统的高可用性架构设计,包括架构的需求与目标、双活或多活数据库架构的构建,以及监
【20分钟精通MPU-9250】:九轴传感器全攻略,从入门到精通(必备手册)

# 摘要
本文对MPU-9250传感器进行了全面的概述,涵盖了其市场定位、理论基础、硬件连接、实践应用、高级应用技巧以及故障排除与调试等方面。首先,介绍了MPU-9250作为一种九轴传感器的工作原理及其在数据融合中的应用。随后,详细阐述了传感器的硬件连
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )