MoCoViT:融合CNN与Transformer的轻量级视觉模型
"本文探讨了如何结合卷积神经网络(CNN)和Transformer结构以创建轻量化的混合网络,以解决纯Transformer在小数据集上性能不足的问题。文章提到了MoCoViT,一种由ByteDance在ECCV 2022上发表的移动卷积视觉Transformer,它使用MobileTransformerBlock (MTB),包含移动自注意力(MoSA)和移动前馈网络(MoFFN)。MoSA通过Ghost模块减少计算成本,而MoFFN则优化了多层感知机(MLP)的效率。MoCoViT在早期阶段使用CNN块,后期阶段使用MTB块,实现了性能与复杂度的良好平衡。实验结果显示,MoCoViT在ImageNet-1K分类、COCO目标检测和实例分割等任务上超越了其他轻量级模型,如MobileNetV3、GhostNet和MobileFormer。"
在计算机视觉领域,CNN因其平移不变性和局部相关性的特性,成为处理图像任务的首选。然而,CNN的局限在于其感受野有限,难以捕捉全局信息。Transformer结构,尤其是视觉Transformer(ViT),通过自注意力机制可以捕获长距离依赖关系,但在小数据集上往往不如CNN。因此,研究者们开始探索将两者融合,以充分利用各自的优点。
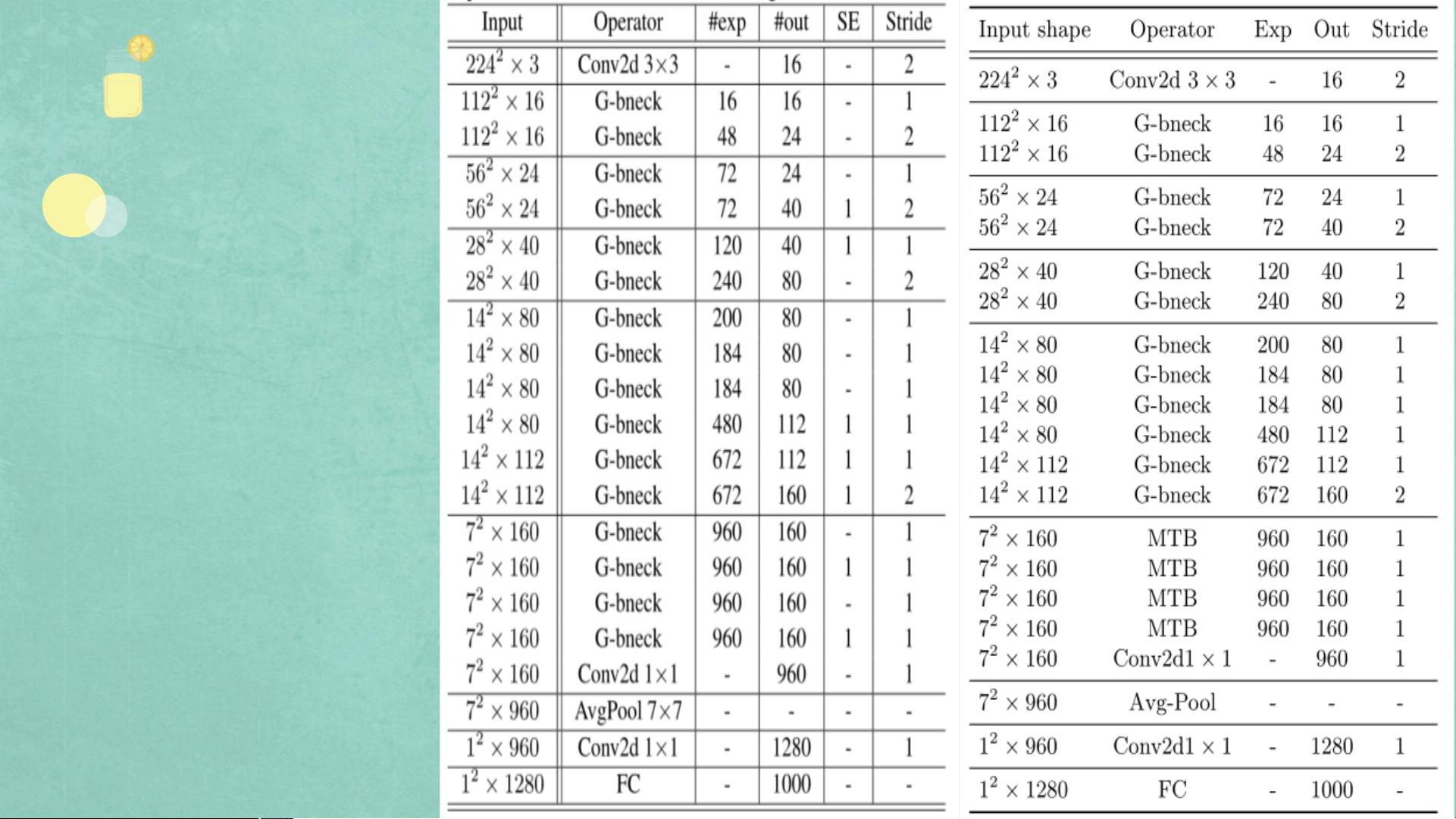
Transformer的原始设计源于自然语言处理,其核心是自注意力机制,允许模型关注输入序列中的不同位置。当Transformer应用于视觉任务时,它能够处理全局上下文,但需要大量数据进行训练。为了解决这个问题,MoCoViT引入了MobileTransformerBlock,其中的MoSA通过Ghost模块减轻计算负担,同时保持了注意力机制的语义保留能力。MoFFN则通过替换MLP中的线性层来提高效率。
Ghost模块是一种轻量级的卷积操作,通过简单的操作生成更多的特征映射,减少了计算量。MoSA通过Ghost模块在查询、键和值的计算中节省资源,同时利用分支共享机制复用权重。MoFFN则优化了Transformer中的MLP,使得整个网络更加轻量化而不牺牲太多性能。
MoCoViT的网络结构设计独特,它在早期阶段使用CNN块来捕获局部特征,而后期阶段采用MTB,利用Transformer的优势捕获全局信息。这种设计策略使得MoCoViT能够在保持高效的同时,提供与纯Transformer或纯CNN结构相当甚至更好的性能。
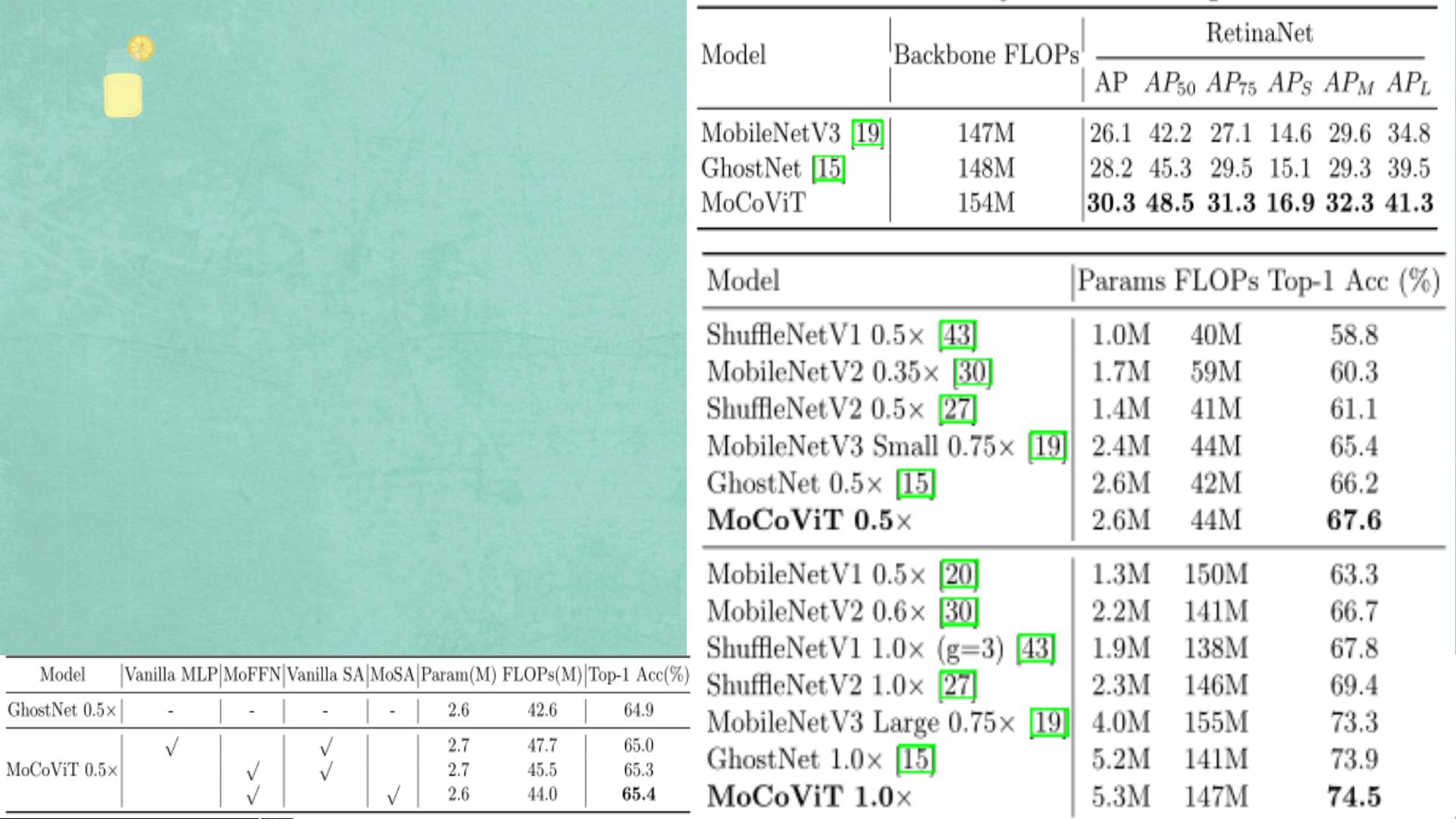
实验结果证实,MoCoViT在多个视觉任务中表现出色,不仅超越了其他轻量级CNN模型,也超过了轻量级Transformer模型。这表明,结合CNN和Transformer的混合网络设计是一种有效的方法,能够在资源受限的环境中实现高性能的计算机视觉应用。

相关推荐



羞儿
- 粉丝: 1856
 我的内容管理
展开
我的内容管理
展开







最新资源
- Subclipse 1.8.2版:Eclipse IDE的Subversion插件下载
- Spring框架整合SpringMVC与Hibernate源码分享
- 掌握Excel编程与数据库连接的高级技巧
- Ubuntu实用脚本合集:提升系统管理效率
- RxJava封装OkHttp网络请求库的Android开发实践
- 《C语言精彩编程百例》:学习C语言必备的PDF书籍与源代码
- ASP MVC 3 实例:打造留言簿教程
- ENC28J60网络模块的spi接口编程及代码实现
- PHP实现搜索引擎技术详解
- 快速香草包装技术:速度更快的新突破
- Apk2Java V1.1: 全自动Android反编译及格式化工具
- Three.js基础与3D场景交互优化教程
- Windows7.0.29免安装Tomcat服务器快速部署指南
- NYPL表情符号机器人:基于Twitter的图像互动工具
- VB自动出题题库系统源码及多技术项目资源
- AndroidHttp网络开发工具包的使用与优势
