Greenplum哈希分布详解:调试与集群扩容实践
43 浏览量
更新于2024-08-28
收藏 706KB PDF 举报
Greenplum(GP)作为分布式数据库系统,其数据分布策略对于性能优化至关重要。本文主要探讨了Greenplum中的哈希分布,这是一种常用的分布方式,它依据指定列(如建表语句中的DISTRIBUTED BY (c1))的值进行数据的散列,确保数据均匀地分布在各个Segment中。
在实际操作中,当我们使用Greenplum时,默认情况下通过Master节点访问整个数据库。然而,为了观察数据在Segment层面的分布,可以使用PostgreSQL的utility模式连接到单个Segment。通过这种方式,我们可以验证数据是否按照预期的哈希分布规则分布在各个Segment中。例如,如果只有一个Segment,数据会完全集中在该Segment上。
文章接下来介绍了如何进行Greenplum集群的扩容。官方文档《GPDB62 Docs》提供了详细的步骤,包括:
1. 初始化新Segment:创建新的Segment实例,这将生成一个输入文件gpexpand_inputfile_yyyymmdd_xxxx。
2. 执行扩容:根据输入文件中的信息来增加Segment,并监控扩容过程。
3. 数据重分布:扩容后,为了保持数据的均匀分布,需要执行数据重分布操作,确保旧数据在新Segment上的正确分布。
4. 清理扩容信息:删除与本次扩容相关的临时schema,以保持系统的整洁。
扩容完成后,可以通过检查后台进程数确认新Segment已经启动并加入集群。最后,作者通过连接不同的Segment来对比数据分布,发现数据在扩容后的两个Segment之间是不均衡的,这通常是因为哈希函数的结果导致的,尤其是在数据量较大时可能会出现数据倾斜问题。
理解Greenplum的哈希分布和集群扩容是优化数据库性能的关键,通过合理设计分布策略以及适时调整集群规模,可以提高查询效率并避免数据热点问题。
Greenplum初探初探-数据哈希分布与集群扩容数据哈希分布与集群扩容
Greenplum(GP)是分布式数据库,因此,数据的分布是基础。GP提供了多种分布策略:哈希分布、随机分布和复制表。其
中,最常用的就是哈希分布。本篇文章我将向大家介绍GP的哈希分布。
首先,我们先回顾一下上篇文章用于调试的那张表:
大家可以看到建表语句末尾有DISTRIBUTED BY (c1),这就表示上面这张表是一张哈希分布表,且通过列c1的值散列数据。
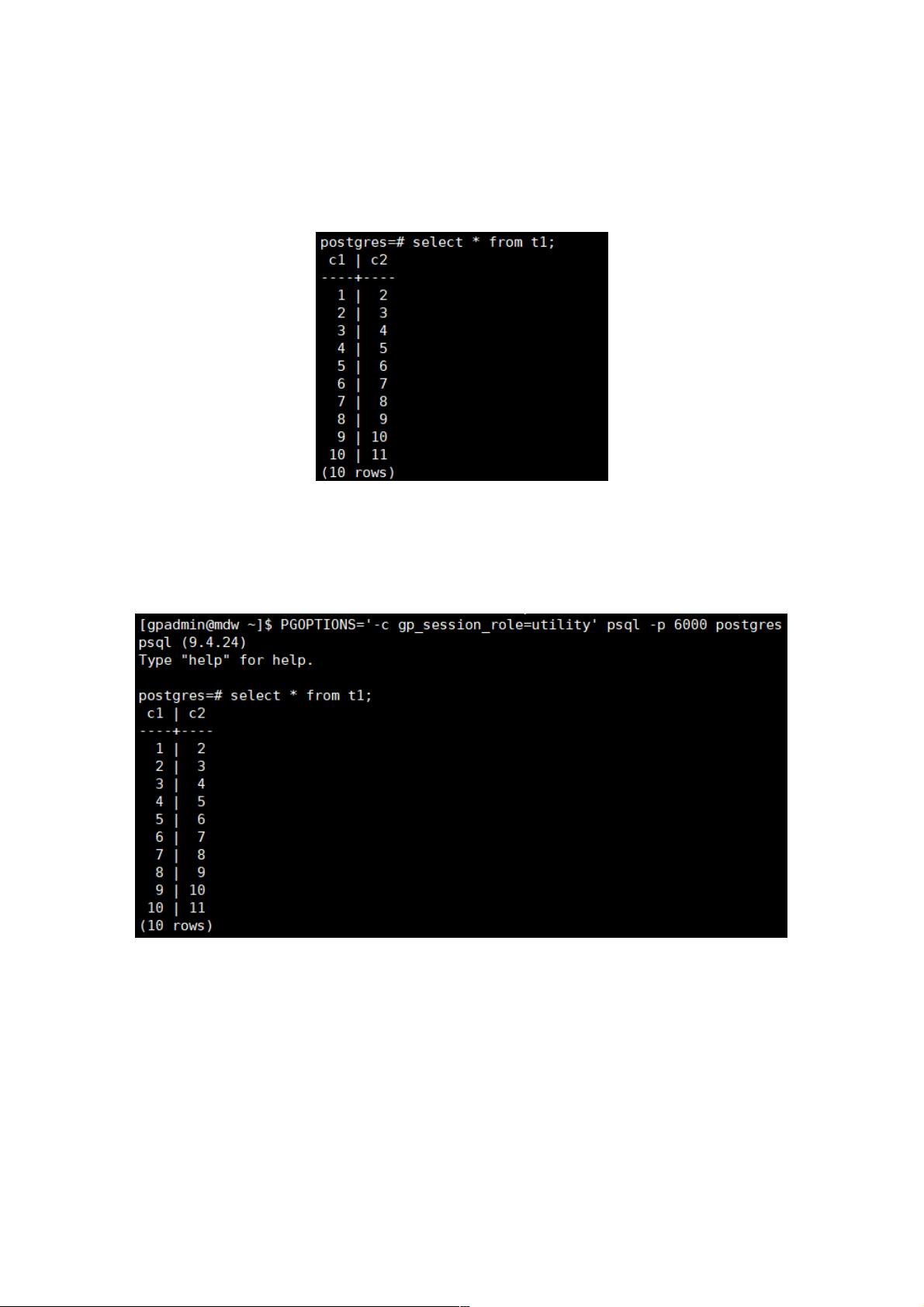
我们再来看下表里的数据:
因为psql默认连接的是Master,所以这里只能看到整张表的数据。如果我们想观察数据在Segment中的分布情况,那么有没有
办法只看某个Segment中存储的数据呢?答案是有的。由于Segment也是一个PostgresQL(PG)实例,psql提供了一个utility
模式,可以直接连接Segment(注意不要通过此模式,绕过Master,直接在Segment执行DDL或数据插入语句,这样做可能
会引发集群异常)。执行以下命令,直连Segment:
连接上Segment后,再次查看Segment上t1表的数据:
由于我们上次搭建的环境只有一台Segment,表t1的数据理所当然全部存储在这台Segment上。所以,下面我们需要将集群扩
容,再将t1的数据重分布,然后再观察。
扩容
GP的官方文档中,有对扩容的详细介绍,具体可以查阅《GPDB62Docs》—— Chapter 4 Greenplum Database
Administrator Guide —— Managing a Greenplum System —— Expanding a Greenplum System。
1,初始化新的Segments
完成后,会在当前目录生成一个input file,gpexpand_inputfile_yyyymmdd_xxxx。
下载后可阅读完整内容,剩余4页未读,立即下载
点击了解资源详情
2019-01-19 上传
2013-05-23 上传
2022-08-04 上传
2024-07-24 上传
2023-07-28 上传
2021-04-09 上传
2021-04-09 上传
2019-04-30 上传

weixin_38742571
- 粉丝: 13
- 资源: 955
 我的内容管理
展开
我的内容管理
展开







最新资源
- wsn-(2).zip_matlab例程_matlab_
- RedisView:RedisView通过自定义的RESP协议解析,自定义的树模型和线程池,实现了开源,跨平台和高性能的Redis接口工具。 RedisView业余爱好通过自写RESP协议解析,自写树模型,线程池实现开源,跨平台,高级Redis界面图形化工具
- PyPI 官网下载 | tencentcloud-sdk-python-cfs-3.0.447.tar.gz
- TheSquirrelCafe:物联网松鼠喂食器
- ZDWW-OA:zdww-OA
- BMI计算器:BMI计算器
- powertabeditor:跨平台的吉他谱编辑器
- CTProjSim.zip_matlab例程_matlab_
- 参考资料-WI-NK0102档案分类及保管期限表.zip
- refactoring
- Tradedoubler for Publishers-crx插件
- KMV的MATLAB的代码-CarND-Behavioral-Cloning:CarND行为克隆
- BtShell-开源
- SigDigger:基于Qt的数字信号分析仪,使用Suscan内核和Sigutils DSP库
- x86.zip
- feedback:Laravel反馈请求包
