Greenplum哈希分布详解:调试与集群扩容实战
26 浏览量
更新于2024-08-28
收藏 715KB PDF 举报
Greenplum(GP)作为分布式数据库系统,其数据分布策略对于性能优化至关重要。本文主要探讨了Greenplum中的数据哈希分布,这是一种常用的分布策略,它根据用户指定的列(如`CREATE TABLE t1 AS SELECT gc1, g + 1 as c2 FROM generate_series(1, 10) g DISTRIBUTED BY (c1)`中的c1)进行数据的均匀分布,确保每个Segment(Greenplum的逻辑组成部分)处理相对均匀的数据量。
在实际操作中,当使用默认的Master节点连接Greenplum时,无法直接查看Segment中的数据分布。为了观察Segment级别的数据分布,可以通过PostgreSQL的utility模式连接到Segment实例,例如使用`PGOPTIONS='-cgp_session_role=utility' psql -p 6000 postgres`命令。这允许我们查看特定Segment上的数据情况,这对于理解和优化数据分布极其有用。
在集群管理中,如果需要扩容Greenplum系统,官方文档《GPDB 62 Docs》提供了详细的步骤。首先,需要进入`/home/gpadmin/`目录并使用`gpexpand`工具初始化新的Segment。用户会被提示是否开始扩容,以及输入新主机名和要添加的Primary Segments的数量。这一步骤将扩展Greenplum集群的规模,同时可能导致数据重新分配,以便保持负载均衡。
当集群扩容完成后,原有的数据分布可能会改变,这时可以再次检查表t1的数据分布情况,以验证数据是否均匀分布在新的Segment上。通过这种方式,我们可以更好地理解Greenplum的哈希分布机制,并在必要时调整表的分布策略,以提高查询性能和系统的整体稳定性。在整个过程中,理解数据分布原则和如何正确操作是至关重要的。
Greenplum初探初探-数据哈希分布与集群扩容数据哈希分布与集群扩容
Greenplum(GP)是分布式数据库,因此,数据的分布是基础。GP提供了多种分布策略:哈希分布、随机分布和复制表。其
中,最常用的就是哈希分布。本篇文章我将向大家介绍GP的哈希分布。
首先,我们先回顾一下上篇文章用于调试的那张表:
CREATE table t1 AS SELECT g c1, g + 1 as c2 FROM
generate_series(1, 10) g DISTRIBUTED BY (c1);
大家可以看到建表语句末尾有DISTRIBUTED BY (c1),这就表示上面这张表是一张哈希分布表,且通过列c1的值散列数据。
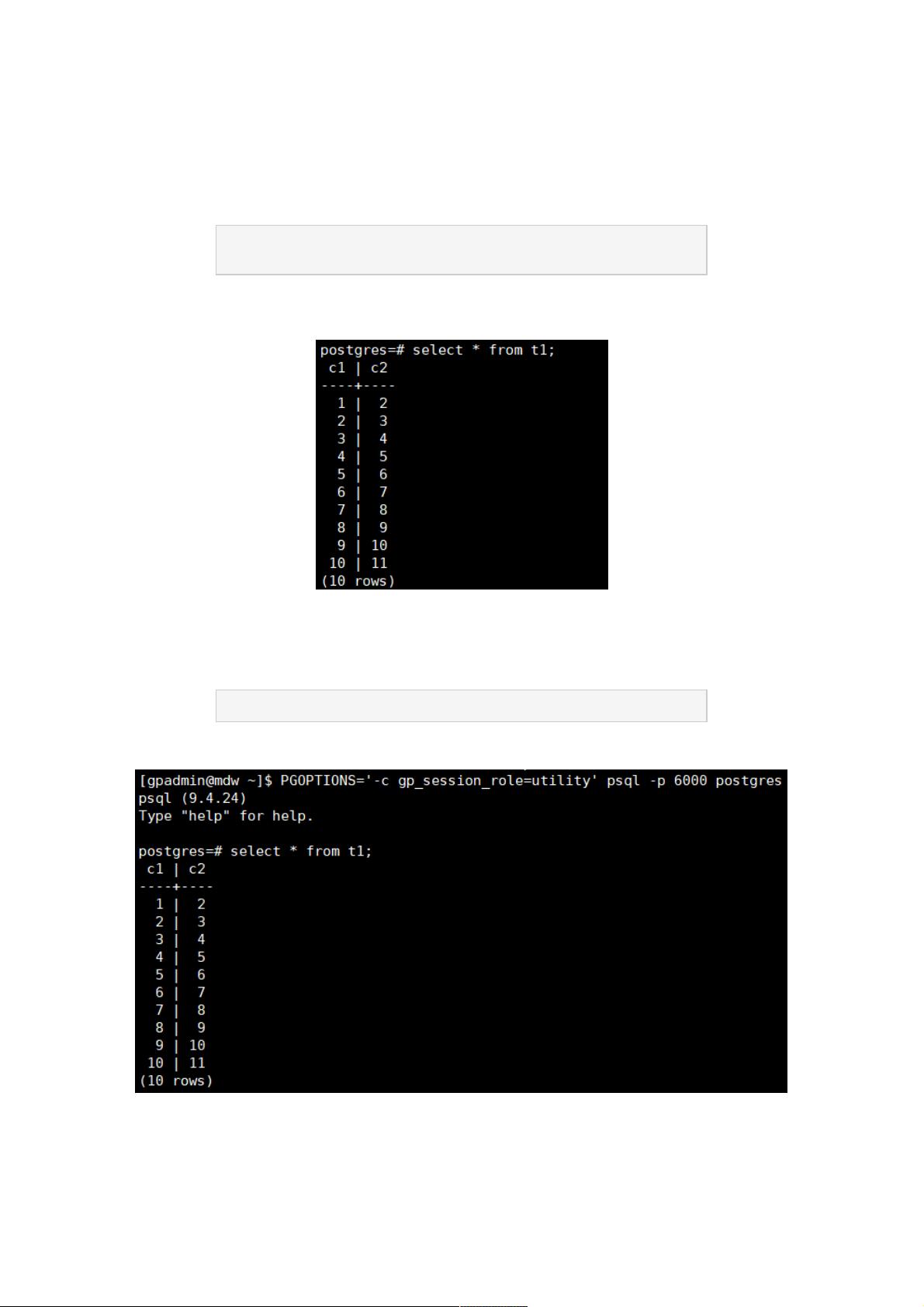
我们再来看下表里的数据:
因为psql默认连接的是Master,所以这里只能看到整张表的数据。如果我们想观察数据在Segment中的分布情况,那么有没有
办法只看某个Segment中存储的数据呢?答案是有的。由于Segment也是一个PostgresQL(PG)实例,psql提供了一个utility
模式,可以直接连接Segment(注意不要通过此模式,绕过Master,直接在Segment执行DDL或数据插入语句,这样做可能
会引发集群异常)。执行以下命令,直连Segment:
PGOPTIONS='-c gp_session_role=utility' psql -p 6000 postgres
连接上Segment后,再次查看Segment上t1表的数据:
由于我们上次搭建的环境只有一台Segment,表t1的数据理所当然全部存储在这台Segment上。所以,下面我们需要将集群扩
容,再将t1的数据重分布,然后再观察。
扩容
GP的官方文档中,有对扩容的详细介绍,具体可以查阅《GPDB62Docs》—— Chapter 4 Greenplum Database
Administrator Guide —— Managing a Greenplum System —— Expanding a Greenplum System。
1,初始化新的Segments
下载后可阅读完整内容,剩余6页未读,立即下载
2021-12-12 上传
2019-01-19 上传
2013-05-23 上传
2022-08-04 上传
2024-07-24 上传
点击了解资源详情
2023-07-28 上传
2021-04-09 上传

weixin_38748055
- 粉丝: 4
- 资源: 960
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国江河水系图层shp文件包下载
- 点云二值化测试数据集的详细解读
- JDiskCat:跨平台开源磁盘目录工具
- 加密FS模块:实现动态文件加密的Node.js包
- 宠物小精灵记忆配对游戏:强化你的命名记忆
- React入门教程:创建React应用与脚本使用指南
- Linux和Unix文件标记解决方案:贝岭的matlab代码
- Unity射击游戏UI套件:支持C#与多种屏幕布局
- MapboxGL Draw自定义模式:高效切割多边形方法
- C语言课程设计:计算机程序编辑语言的应用与优势
- 吴恩达课程手写实现Python优化器和网络模型
- PFT_2019项目:ft_printf测试器的新版测试规范
- MySQL数据库备份Shell脚本使用指南
- Ohbug扩展实现屏幕录像功能
- Ember CLI 插件:ember-cli-i18n-lazy-lookup 实现高效国际化
- Wireshark网络调试工具:中文支持的网口发包与分析
