深度学习新突破:ReZero解决梯度问题
版权申诉
65 浏览量
更新于2024-08-14
收藏 674KB PDF 举报
"神经网络之解决梯度消失或爆炸.pdf"
深度学习的神经网络在诸如计算机视觉和自然语言处理等领域取得了显著成就,这主要得益于其强大的表达能力,尤其是随着网络深度增加而指数增长的表达力。然而,这种深度也带来了挑战,其中最著名的就是梯度消失和梯度爆炸问题。这两个问题会导致深层网络中的权重更新变得微不足道或不可控,进而影响模型的学习和优化。
为了解决这些问题,研究者提出了一系列技术,如权值初始化策略、批量归一化(BatchNorm)和层归一化(LayerNorm)。这些方法虽然在一定程度上缓解了梯度问题,但它们可能会增加计算复杂性,或者本身存在局限性。
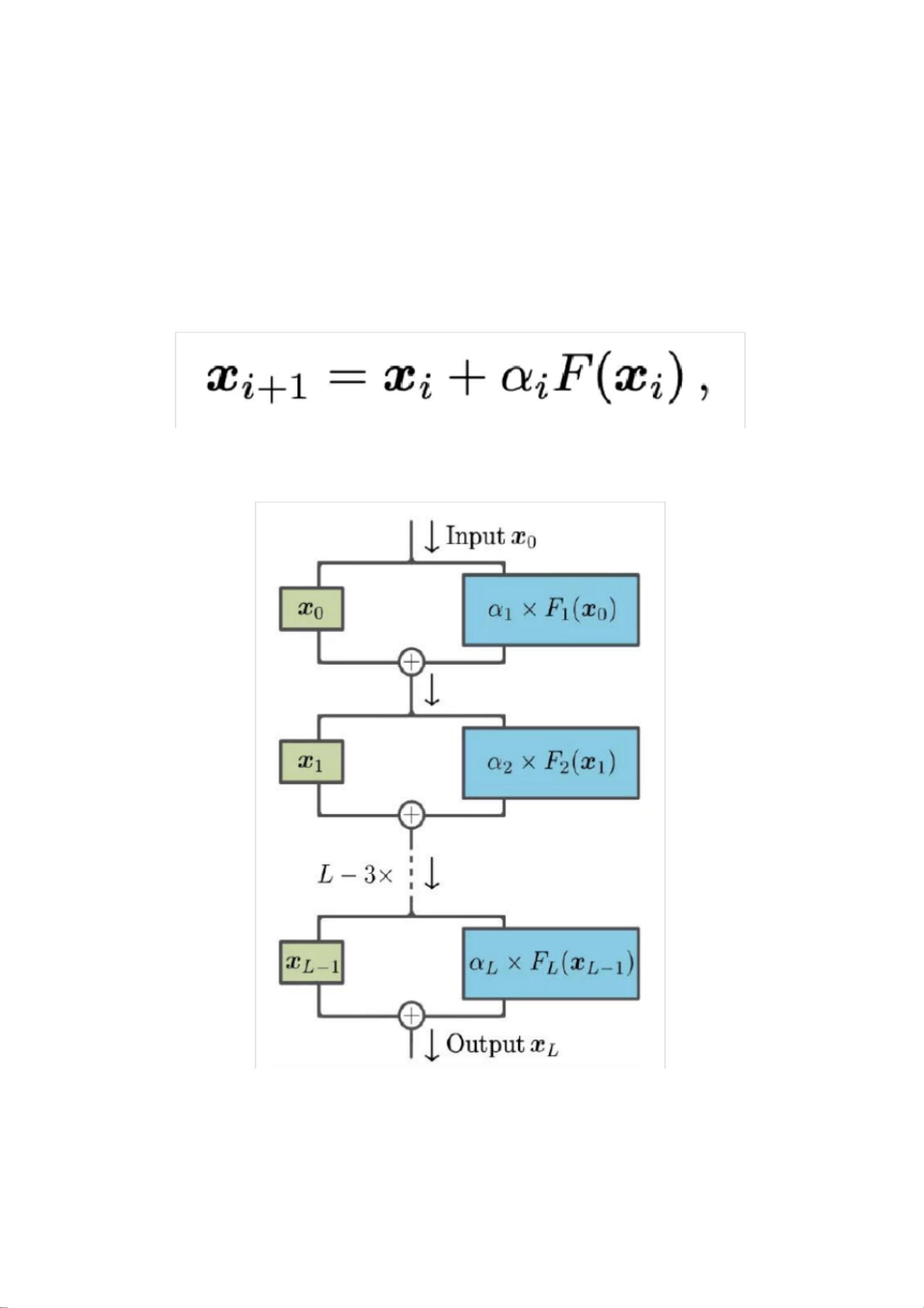
ReZero是一种新颖的解决方案,它通过在每个网络层引入一个残差连接和一个可训练的参数α,使得网络在训练初期表现为恒等映射。α的初始值设为零,这意味着在训练开始时,网络层的梯度几乎消失,允许网络在后续的训练过程中动态地学习合适的参数值。ReZero的网络结构如图所示,它改进了传统的残差网络结构。
ReZero的主要优势体现在两个方面:
1. 提升深层神经网络的训练可行性:由于学习信号可以有效地在深层网络中传播,ReZero使得训练非常深的网络成为可能。例如,它成功训练了一万个层的全连接网络和超过一百层的Transformer模型,无需使用像学习速率热身和LayerNorm这样的额外技巧。
2. 加速收敛速度:相比于使用标准化操作的常规残差网络,ReZero具有更快的收敛速度。应用到Transformer模型时,其在enwiki8语言建模基准上的收敛速度提高了56%;而在ResNet上处理CIFAR10数据集时,ReZero实现了32%的训练加速,同时保持85%的精度。
ReZero的核心在于其动态等距(dynamical isometry)的概念,它通过在初始阶段避免使用复杂的函数传递信号,而是用残差连接和初始为零的可学习参数α_i(即残差权重)来重新调整网络层的输出。这样,即使在某些层的雅可比值消失的情况下,也能保证深度网络的训练有效性,类似于ReLU激活函数或自注意力机制的效果。
ReZero提供了一种简单而有效的手段,以克服深度神经网络中的梯度问题,促进深层网络的训练,并且能显著提高模型的训练效率。这种技术对于继续推进深度学习在各种任务中的应用具有重要的意义。
深度学习在计算机视觉、自然语言处理等领域取得了很多重大突破。神经
网络的表达能力通常随着其网络深度呈指数增长,这一特性赋予了它很强的泛
化能力。然而深层的网络也产生了梯度消失或梯度爆炸,以及模型中的信息传
递变差等一系列问题。研究人员使用精心设计的权值初始化方法、 BatchNorm
或 LayerNorm 这类标准化技术来缓解以上问题,然而这些技术往往会耗费更多
计算资源,或者存在其自身的局限。
这个想法其实非常简单: ReZero 将所有网络层均初始化为恒等映射。在每
一层中,研究者引入了一个关于输入信号 x 的残差连接和一个用于调节当前网
络层输出 F(x) 的可训练参数 α,即:
在刚开始训练的时候将 α 设置为零。这使得在神经网络训练初期,所有组
成变换 F 的参数所对应的梯度均消失了,之后这些参数在训练过程中动态地产
生合适的值。改进的网络结构如下图所示:
ReZero 主要带来了以下两个益处:
1. 能够训练更深层神经网络
学习信号能够有效地在深层神经网络中传递,这使得我们能够训练一些之前所
下载后可阅读完整内容,剩余4页未读,立即下载
2021-09-21 上传
2021-09-26 上传
2021-09-25 上传
2021-09-26 上传
2023-03-09 上传
2021-09-25 上传
2020-04-02 上传
2023-06-05 上传
2021-09-20 上传

m0_63611298
- 粉丝: 0
- 资源: 9万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- StarModAPI: StarMade 模组开发的Java API工具包
- PHP疫情上报管理系统开发与数据库实现详解
- 中秋节特献:明月祝福Flash动画素材
- Java GUI界面RPi-kee_Pilot:RPi-kee专用控制工具
- 电脑端APK信息提取工具APK Messenger功能介绍
- 探索矩阵连乘算法在C++中的应用
- Airflow教程:入门到工作流程创建
- MIP在Matlab中实现黑白图像处理的开源解决方案
- 图像切割感知分组框架:Matlab中的PG-framework实现
- 计算机科学中的经典算法与应用场景解析
- MiniZinc 编译器:高效解决离散优化问题
- MATLAB工具用于测量静态接触角的开源代码解析
- Python网络服务器项目合作指南
- 使用Matlab实现基础水族馆鱼类跟踪的代码解析
- vagga:基于Rust的用户空间容器化开发工具
- PPAP: 多语言支持的PHP邮政地址解析器项目
