
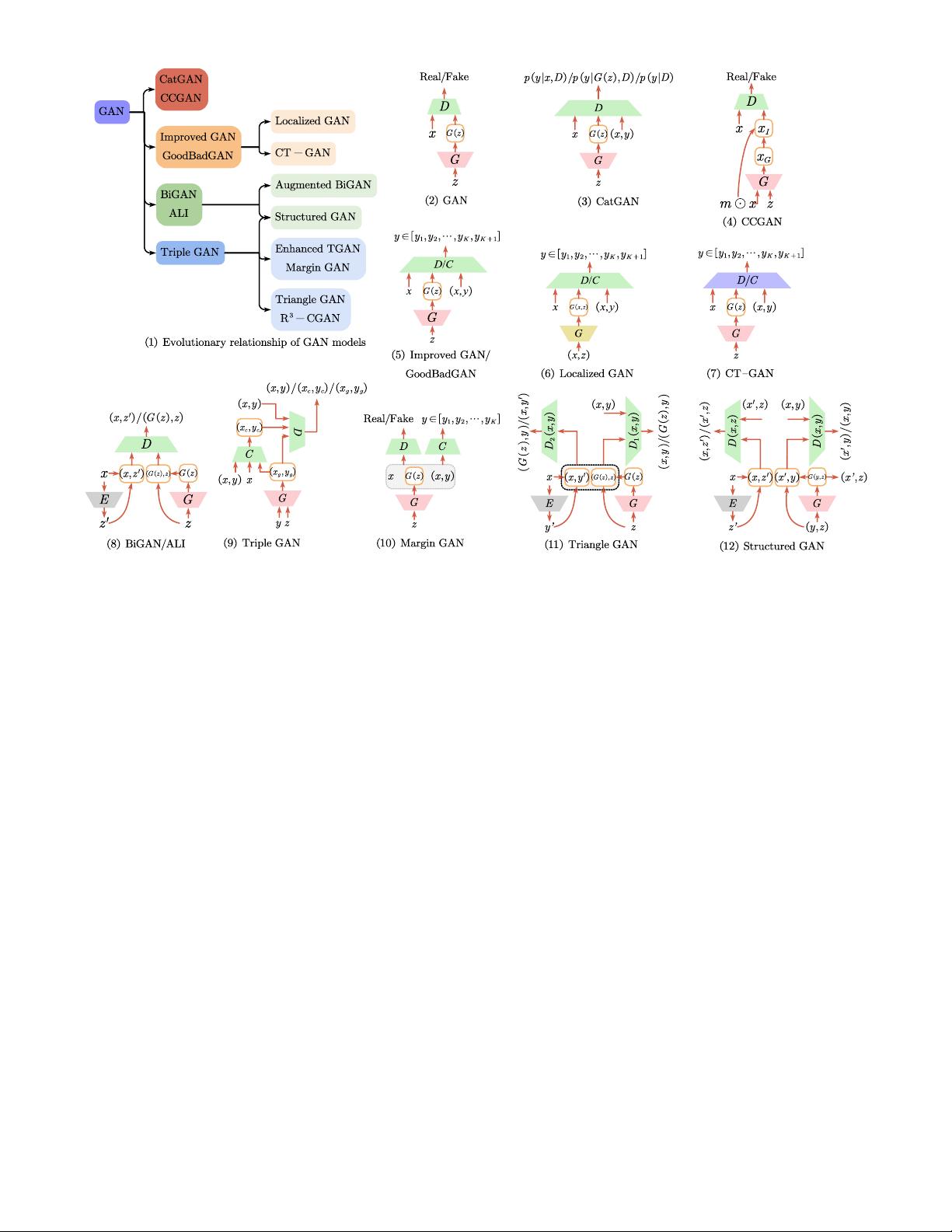
5
Fig. 2. A glimpse of the diverse range of architectures used for GAN-based deep generative semi-supervised methods. The characters ‘‘D, G” and
“E” represent Discriminator, Generator and Encoder, respectively. In Figure (6), Localized GAN is equipped with a local generator G(x, z), so we
use the yellow box to distinguish it. Similarly, in CT-GAN, the purple box is used to denote a discriminator that introduces consistency constraint.
the standard GAN (Eq. (2)). The structure is illustrated in
Fig. 2(3). This method aims to learn a discriminator which
distinguishes the samples into K categories by labeling y
to each x, instead of learning a binary discriminator value
function. Moreover, the CatGAN discriminator loss function
the supervised loss is also a cross-entropy term between
the predicted conditional distribution p(y|x, D) and the
true label distribution of examples.n consists of three parts:
(1) entropy H[p(y|x, D)] which to obtain certain category
assignment for samples; (2) H[p(y|G(z), D)] for uncertain
predictions from generated samples; (3) the marginal class
entropy H[p(y|D)] to uniform usage of all classes. The
proposed framework uses the feature space learned by the
discriminator for the final learning task. For the labeled data,
the supervised loss is also a cross-entropy term between
the conditional distribution p(y|x, D) and the samples’ true
label distribution.
CCGAN. Context-Conditional Generative Adversarial
Networks (CCGAN) [141] is proposed to use an adversarial
loss for harnessing unlabeled image data based on image
in-painting. The architecture of the CCGAN is shown in
Fig. 2(4). The main highlight of this work is context infor-
mation provided by the surrounding parts of the image. The
method trains a GAN where the generator is to generate pix-
els within a missing hole. The discriminator is to discrimi-
nate between the real unlabeled images and these in-painted
images. More formally, m x as input to a generator, where
m denotes a binary mask to drop out a specified portion
of an image and denotes element-wise multiplication.
Thus the in-painted image x
I
= (1 − m) x
G
+ m x
with generator outputs x
G
= G(m x, z). The in-painted
examples provided by the generator cause the discrimina-
tor to learn features that generalize to the related task of
classifying objects. The penultimate layer of components of
the discriminator is then shared with the classifier, whose
cross-entropy loss is used combined with the discriminator
loss.
Improved GAN. There are several methods to adapt
GANs into a semi-supervised classification scenario. Cat-
GAN [140] forces the discriminator to maximize the mutual
information between examples and their predicted class dis-
tributions instead of training the discriminator to learn a bi-
nary classification. To overcome the learned representations’
bottleneck of CatGAN, Semi-supervised GAN (SGAN) [142]
learns a generator and a classifier simultaneously. The clas-
sifier network can have (K + 1) output units corresponding
to [y
1
, y
2
, . . . , y
K
, y
K+1
], where the y
K+1
represents the
outputs generated by G. Similar to SGAN, Improved GAN
[143] solves a (K +1)-class classification problem. The struc-
ture of Improved GAN is shown in Fig. 2(5). Real examples
for one of the first K classes and the additional (K + 1)th
class consisted of the synthetic images generated by the
generator G. This work proposes the improved techniques
to train the GANs, i.e., feature matching, minibatch dis-
crimination, historical averaging one-sided label smoothing,
and virtual batch normalization, where feature matching is
剩余23页未读,继续阅读

syp_net
- 粉丝: 158
- 资源: 1187
 我的内容管理
展开
我的内容管理
展开







最新资源
- 新型矿用本安直流稳压电源设计:双重保护电路
- 煤矿掘进工作面安全因素研究:结构方程模型
- 利用同位素位移探测原子内部新型力
- 钻锚机钻臂动力学仿真分析与优化
- 钻孔成像技术在巷道松动圈检测与支护设计中的应用
- 极化与非极化ep碰撞中J/ψ的Sivers与cos2φ效应:理论分析与COMPASS验证
- 新疆矿区1200m深孔钻探关键技术与实践
- 建筑行业事故预防:综合动态事故致因理论的应用
- 北斗卫星监测系统在电网塔形实时监控中的应用
- 煤层气羽状水平井数值模拟:交替隐式算法的应用
- 开放字符串T对偶与双空间坐标变换
- 煤矿瓦斯抽采半径测定新方法——瓦斯储量法
- 大倾角大采高工作面设备稳定与安全控制关键技术
- 超标违规背景下的热波动影响分析
- 中国煤矿选煤设计进展与挑战:历史、现状与未来发展
- 反演技术与RBF神经网络在移动机器人控制中的应用
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


