Apache Kylin:大数据时代的亚秒级分析引擎
需积分: 0 31 浏览量
更新于2024-06-30
收藏 4.74MB PDF 举报
"尚硅谷大数据技术之Kylin1"
Apache Kylin是一个开源的分布式分析引擎,专为Hadoop/Spark环境设计,提供了SQL查询接口和在线分析处理(OLAP)功能,能够处理超大规模的数据集。它最初由eBay公司开发,并最终贡献给了开源社区。Kylin的一个关键特性是其能够在亚秒级别内对海量Hive数据进行快速查询,这得益于它的预计算策略,将复杂的计算任务在离线阶段完成,显著提升了查询效率。
Kylin的特点主要包括以下几个方面:
1. **标准SQL接口**:Kylin提供了一个符合标准的SQL接口,使得用户可以方便地与大数据环境进行交互,无需学习新的查询语言。
2. **支持超大数据集**:Kylin在处理大数据的能力上表现出色,能支持数十亿乃至上千亿条记录的秒级查询,这在大数据分析领域是非常出色的性能。
3. **亚秒级响应**:通过预计算技术,Kylin将大量计算任务提前执行,极大地减少了在线查询时的计算负担,确保查询响应时间在亚秒级别。
4. **可伸缩性和高吞吐率**:Kylin不仅单节点性能强大,能实现每秒70个查询,还能通过集群扩展,以适应更高的并发查询需求。
5. **BI工具集成**:Kylin支持多种BI工具,如通过ODBC与Tableau、Excel、PowerBI等集成,通过JDBC与Saiku、BIRT等Java工具集成,通过RESTAPI与JavaScript、Web网页集成,还有Zepplin的插件,提供了丰富的对接选项。
Kylin的架构主要由以下几个组件构成:
- **RESTServer**:这是面向应用程序开发的入口点,提供了一套RESTful接口,用于查询、获取结果、触发Cube构建任务、获取元数据以及用户权限管理等功能。
- **查询引擎(QueryEngine)**:当用户发起查询后,查询引擎解析SQL,与其他组件协作,返回查询结果。它是Kylin实现高效查询的关键部分。
- **Routing**:这个组件负责将SQL查询转换为针对预计算Cube的查询计划。Cube的数据预先存储在HBase中,这样可以直接快速检索,达到秒级或毫秒级的查询速度。
通过这些组件和特性,Kylin成为了一个强大的大数据分析平台,为企业的大数据分析和决策支持提供了高效的解决方案。无论是数据分析师还是开发人员,都能借助Kylin更轻松地从海量数据中获取有价值的信息。

第
2
章
Kylin
环境搭建
2.1 安装地址
1)官网地址
http://kylin.apache.org/cn/
2)官方文档
http://kylin.apache.org/cn/docs/
3)下载地址
http://kylin.apache.org/cn/download/
2.2 安装部署
1)将 apache-kylin-2.5.1-bin-hbase1x.tar.gz 上传到 Linux
2)解压 apache-kylin-2.5.1-bin-hbase1x.tar.gz 到/opt/module
[atguigu@hadoop102 sorfware]$ tar -zxvf
apache-kylin-2.5.1-bin-hbase1x.tar.gz -C /opt/module/
注意:需要在/etc/profile 文件中配置 HADOOP_HOME,HIVE_HOME,HBASE_HOME 并
将其对应的 sbin(如果有这个目录的话)和 bin 目录配置到 Path,最后需要 source 使其生效。
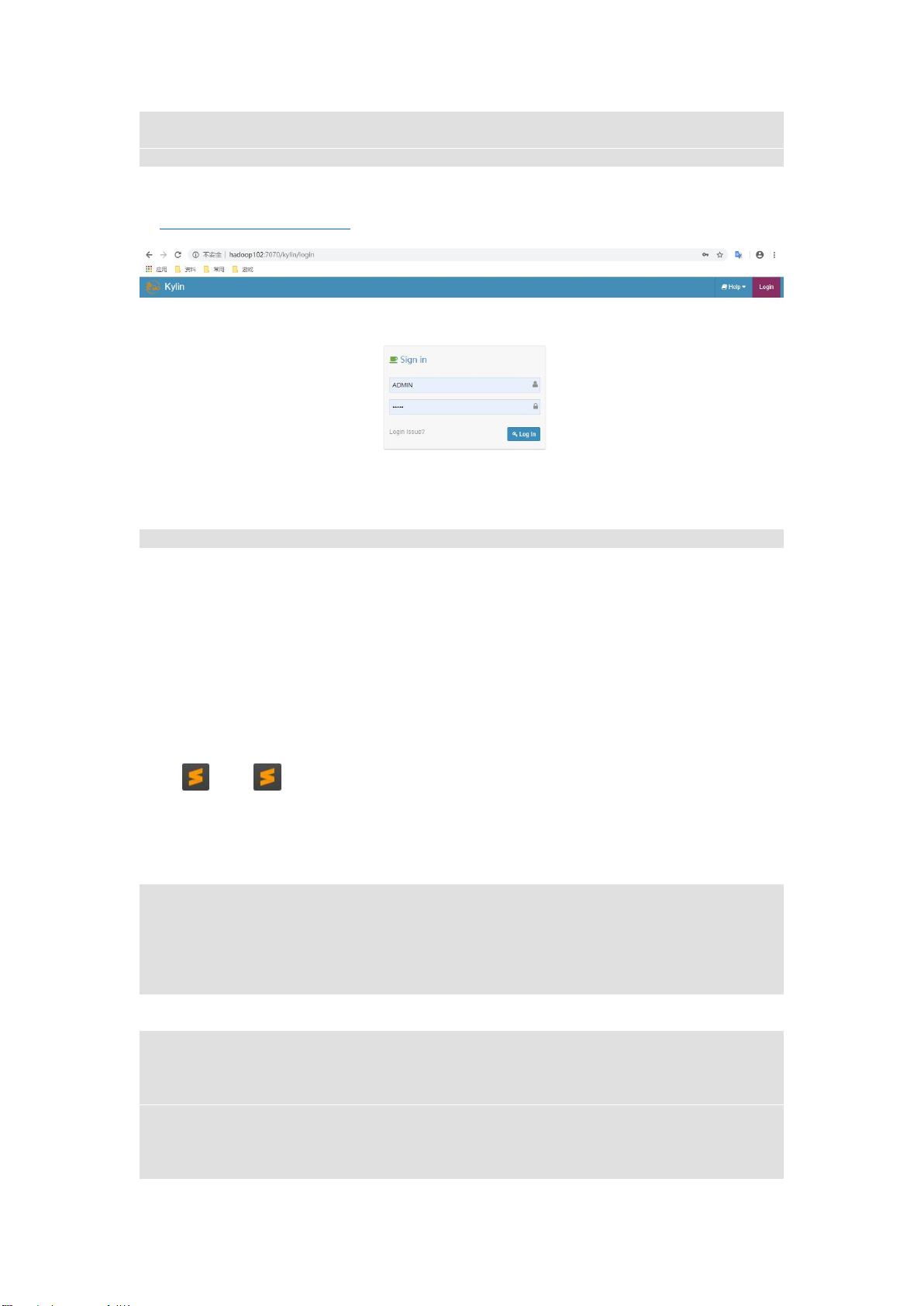
3)启动
[atguigu@hadoop102 kylin]$ bin/kylin.sh start
启动之后查看各个节点进程:
--------------------- hadoop102 ----------------
3360 JobHistoryServer(MR 的历史服务,必须启动)
31425 HMaster
3282 NodeManager
3026 DataNode
53283 Jps
2886 NameNode
44007 RunJar
2728 QuorumPeerMain
31566 HRegionServer
--------------------- hadoop103 ----------------
5040 HMaster
2864 ResourceManager
9729 Jps
2657 QuorumPeerMain
4946 HRegionServer
2979 NodeManager
2727 DataNode
--------------------- hadoop104 ----------------
4688 HRegionServer
2900 NodeManager
9848 Jps
2636 QuorumPeerMain
剩余39页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-08-04 上传
2020-02-13 上传
2022-07-08 上传
2021-08-18 上传
2024-07-18 上传
2022-03-27 上传

KateZeng
- 粉丝: 26
- 资源: 330
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
