HBase RowKey设计与协处理器应用解析
需积分: 17 157 浏览量
更新于2024-09-06
收藏 426KB DOCX 举报
"本文档主要介绍了HBase的rowkey设计原则以及HBase的协处理器运用,旨在分享关于HBase的关键知识。"
在HBase这个分布式列式数据库中,rowkey的设计和协处理器的运用是非常关键的方面,对于系统的性能和功能扩展性有着直接影响。
1. HBase Rowkey设计
- **唯一性**:Rowkey必须是唯一的,因为它是表中数据的唯一标识。
- **排序性**:Rowkey是字节序排序的,设计时需考虑业务需求,确保重要的或常用的查询模式能在排序中受益。
- **前缀分散**:将经常一起查询的数据分配在同一Region内,通过将相关数据的Rowkey设计为相同前缀来实现。
- **反范式化**:由于HBase是稀疏的,Rowkey应包含所有查询所需的必要信息,避免额外的扫描操作。
- **长度适中**:Rowkey不宜过长,以免增加存储开销;也不宜过短,可能导致排序和查询效率降低。
- **避免热点问题**:防止所有数据都落在同一个Region,导致负载不均。可以通过时间戳、哈希值等方式分散Rowkey分布。
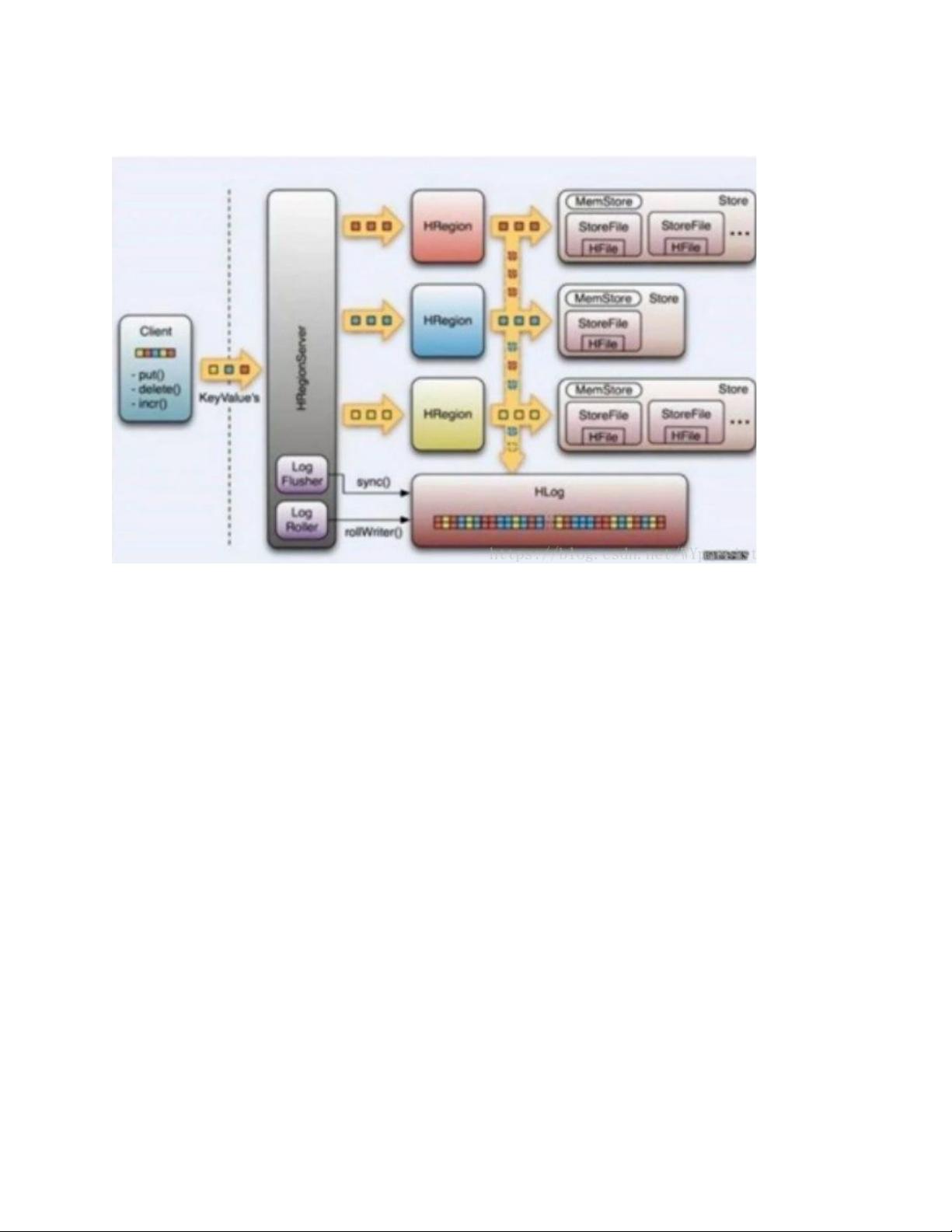
2. HBase写数据流程
- 数据首先写入HLog,保证持久化,即使RegionServer失败,也能从日志恢复。
- 写入内存中的MemStore,达到一定阈值后,数据被刷入磁盘上的StoreFile。
- StoreFile不断累积并进行合并,合并过程中处理版本管理和数据删除。
- 当StoreFile大小达到一定程度,触发Region的拆分,保持Region的大小均衡。
3. HBase读数据流程
- 读操作首先从内存中的MemStore查找,因为这是最新数据的来源。
- 如果MemStore中没有,再从磁盘上的StoreFile读取,这可能涉及多层索引查找。
- 读取过程涉及客户端与RegionServer的交互,通过元数据表(META)定位Region位置。
4. HBase协处理器
- **协处理器**是运行在RegionServer上的插件,可以扩展HBase的功能,比如实现数据过滤、数据校验、定制索引等。
- 协处理器提供了在数据写入和读取时介入的机会,可以在数据到达磁盘之前进行处理,提高了效率和安全性。
- 通过定义协处理器接口并实现自定义逻辑,用户可以对特定业务场景进行优化。
HBase的高效性和可扩展性使其在大数据存储和处理中广泛应用。了解并合理设计Rowkey,有效利用协处理器,能够显著提升HBase的性能和满足多样化的业务需求。在实际操作中,还需要关注客户端配置、系统调优、监控等方面,以确保HBase集群的稳定运行。
4,查找对应的 region
5,先从 MemStore 找数据,如果没有,再到 StoreFile 上读(为了读取的效率)。
Hbase 写数据流程
a) Client 发起了一个 HTable.put(Put)请求给 HRegionServer
b) HRegionServer 会将请求匹配到某个具体的 HRegion 上面
c) 决定是否写 WAL log。WAL log 文件是一个标准的 Hadoop SequenceFile,文
件中存储了 HLogKey,这些 Keys 包含了和实际数据对应的序列号,主要用于
崩溃恢复。
d) Put 数据保存到 MemStore 中,同时检查 MemStore 状态,如果满了,则触
发 Flush to Disk 请求。
e) HRegionServer 处理 Flush to Disk 的请求,将数据写成 HFile 文件并存到
HDFS 上,并且存储最后写入的数据序列号,这样就可以知道哪些数据已经存
入了永久存储的 HDFS 中。
由于不同的列族会共享 region,所以有可能出现,一个列族已经有 1000 万行,
而另外一个才 100 行。当一个要求 region 分割的时候,会导致 100 行的列会
同样分布到多个 region 中。所以,一般建议不要设置多个列族。
Hbase 快速响应数据
hbase 上的数据是以 store8le(HFile)二进制流的形式存储在 HDFS 上 block
剩余10页未读,继续阅读
2021-11-14 上传
2021-01-30 上传
2022-12-25 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情









