

程序员倾向于使用特定应用程序的Annotation,无论是作为一种分布式调试日志文件,还是通过一些应
用程序特定的功能对跟踪进行分类。例如,所有的Bigtable的请求会把被访问的表名也记录到
Annotation中。目前,70%的Dapper span和90%的所有Dapper跟踪都至少有一个特殊应用的
Annotation。
41个Java应用和68个C++应用中都添加自定义的Annotation为了更好地理解应用程序中的span在他们
的服务中的行为。值得注意的是,迄今为止我们的Java开发者比C++开发者更多的在每一个跟踪span上
采用Annotation的API。这可能是因为我们的Java应用的作用域往往是更接近最终用户(C++偏底层);这些
类型的应用程序经常处理更广泛的请求组合,因此具有比较复杂的控制路径。
4. 处理跟踪损耗
跟踪系统的成本由两部分组成:1.正在被监控的系统在生成追踪和收集追踪数据的消耗导致系统性能下
降,2。需要使用一部分资源来存储和分析跟踪数据。虽然你可以说一个有价值的组件植入跟踪带来一
部分性能损耗是值得的,我们相信如果基本损耗能达到可以忽略的程度,那么对跟踪系统最初的推广会
有极大的帮助。
在本节中,我们会展现一下三个方面:Dapper组件操作的消耗,跟踪收集的消耗,以及Dapper对生产
环境负载的影响。我们还介绍了Dapper可调节的采样率机制如何帮我们处理低损耗和跟踪代表性之间
的平衡和取舍。
4.1 生成跟踪的损耗
生成跟踪的开销是Dapper性能影响中最关键的部分,因为收集和分析可以更容易在紧急情况下被关
闭。Dapper运行库中最重要的跟踪生成消耗在于创建和销毁span和annotation,并记录到本地磁盘供
后续的收集。根span的创建和销毁需要损耗平均204纳秒的时间,而同样的操作在其他span上需要消耗
176纳秒。时间上的差别主要在于需要在跟span上给这次跟踪分配一个全局唯一的ID。
如果一个span没有被采样的话,那么这个额外的span下创建annotation的成本几乎可以忽略不计,他
由在Dapper运行期对ThreadLocal查找操作构成,这平均只消耗9纳秒。如果这个span被计入采样的
话,会用一个用字符串进行标注--在图4中有展现--平均需要消耗40纳秒。这些数据都是在2.2GHz的x86
服务器上采集的。
在Dapper运行期写入到本地磁盘是最昂贵的操作,但是他们的可见损耗大大减少,因为写入日志文件
和操作相对于被跟踪的应用系统来说都是异步的。不过,日志写入的操作如果在大流量的情况,尤其是
每一个请求都被跟踪的情况下就会变得可以察觉到。我们记录了在4.3节展示了一次Web搜索的负载下
的性能消耗。
4.2 跟踪收集的消耗
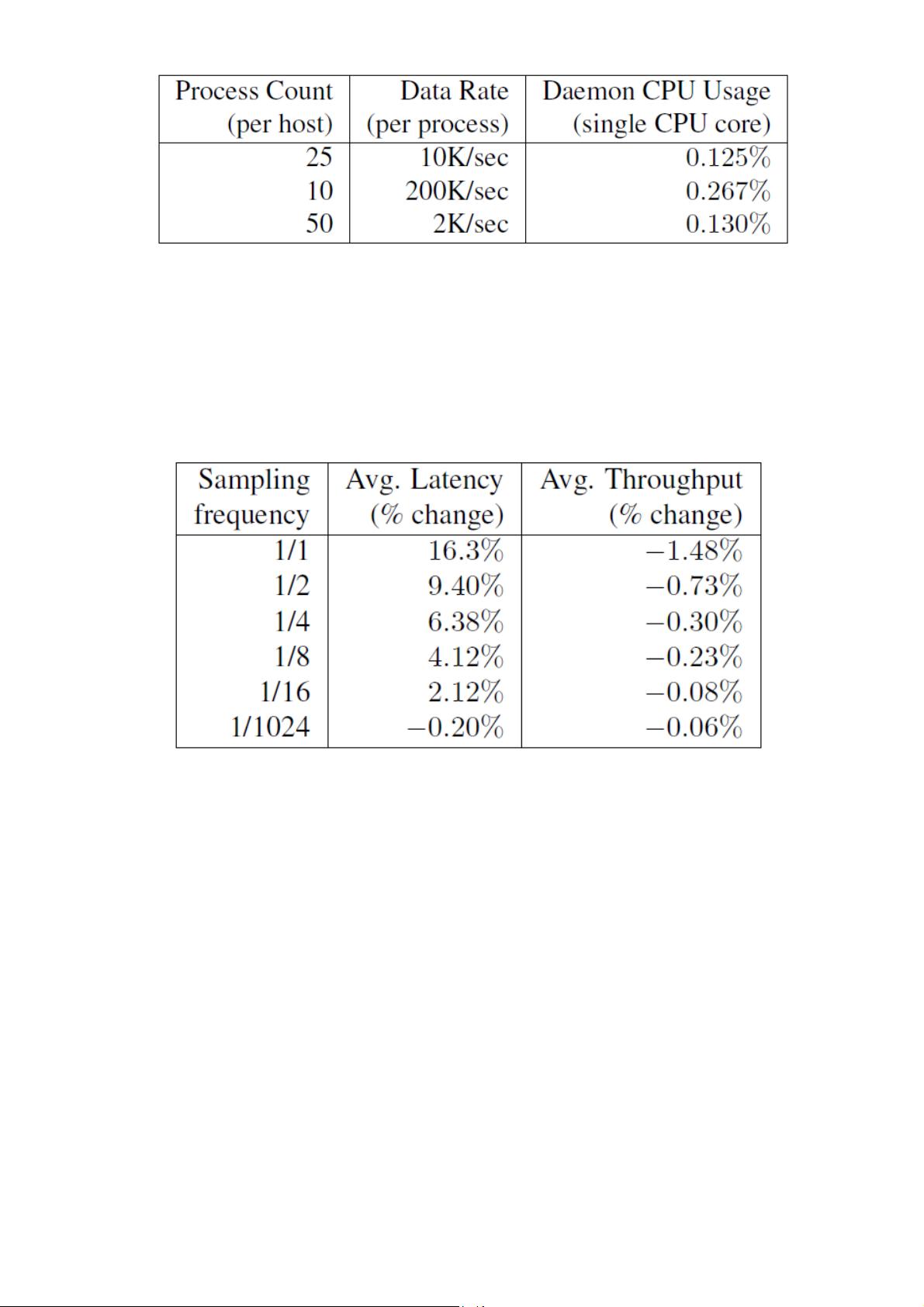
读出跟踪数据也会对正在被监控的负载产生干扰。表1展示的是最坏情况下,Dapper收集日志的守护进
程在高于实际情况的负载基准下进行测试时的cpu使用率。在生产环境下,跟踪数据处理中,这个守护
进程从来没有超过0.3%的单核cpu使用率,而且只有很少量的内存使用(以及堆碎片的噪音)。我们还
限制了Dapper守护进程为内核scheduler最低的优先级,以防在一台高负载的服务器上发生cpu竞争。
Dapper也是一个带宽资源的轻量级的消费者,每一个span在我们的仓库中传输只占用了平均426的
byte。作为网络行为中的极小部分,Dapper的数据收集在Google的生产环境中的只占用了0.01%的网
络资源。
剩余41页未读,继续阅读

八五年的湘哥
- 粉丝: 2w+
- 资源: 22
 我的内容管理
展开
我的内容管理
展开







最新资源
- 新型矿用本安直流稳压电源设计:双重保护电路
- 煤矿掘进工作面安全因素研究:结构方程模型
- 利用同位素位移探测原子内部新型力
- 钻锚机钻臂动力学仿真分析与优化
- 钻孔成像技术在巷道松动圈检测与支护设计中的应用
- 极化与非极化ep碰撞中J/ψ的Sivers与cos2φ效应:理论分析与COMPASS验证
- 新疆矿区1200m深孔钻探关键技术与实践
- 建筑行业事故预防:综合动态事故致因理论的应用
- 北斗卫星监测系统在电网塔形实时监控中的应用
- 煤层气羽状水平井数值模拟:交替隐式算法的应用
- 开放字符串T对偶与双空间坐标变换
- 煤矿瓦斯抽采半径测定新方法——瓦斯储量法
- 大倾角大采高工作面设备稳定与安全控制关键技术
- 超标违规背景下的热波动影响分析
- 中国煤矿选煤设计进展与挑战:历史、现状与未来发展
- 反演技术与RBF神经网络在移动机器人控制中的应用
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


