Rete算法详解:高效规则匹配原理
需积分: 13 90 浏览量
更新于2024-07-17
收藏 1.08MB DOCX 举报
"Rete算法是一种高效的规则匹配算法,常用于规则引擎中,如Drools。该算法通过构建rete网络,利用时间冗余性和结构相似性提高匹配效率。事实是规则引擎中的基本数据单元,规则由条件和结论组成,模式是规则条件的抽象形式。"
Rete算法的核心在于其网络结构,这个网络由多个节点组成,包括alpha节点、beta节点和gamma节点等。Alpha节点负责处理事实对象的属性匹配,而Beta节点则处理事实之间的关系匹配。Gamma节点通常用于合并匹配结果,优化网络性能。在Rete网络中,每个节点都有自己的子网络,当新的事实插入时,这些节点会递归地检查事实是否符合其子网络的条件。
规则引擎的工作流程大致如下:
1. 初始化:首先,规则引擎读取所有的规则,并根据规则的LHS构造Rete网络。
2. 事实插入:用户或系统将事实对象插入到工作内存中,这些事实会从根节点开始,沿着网络向下传播。
3. 匹配过程:每到达一个节点,事实都会与该节点的条件进行比较。如果匹配成功,事实会被传递到下一个节点;如果不匹配,则会被丢弃,以避免无效的计算。
4. 冲突集构建:当事实匹配到一个规则的所有条件时,就会创建一个规则实例并加入到冲突集。冲突集包含了所有可能触发的动作规则。
5. 结论执行:一旦冲突集建立完成,引擎会执行RHS中的动作,这可能是更新数据、触发事件或其他业务逻辑。
在Drools这样的规则引擎中,Rete算法的应用使得规则匹配过程非常高效,即使面对大量规则和事实也能快速响应。此外,Drools还提供了优化机制,如惰性评估(lazy evaluation)和缓存策略,进一步提升了性能。
Rete算法的优越性在于其对时间冗余性的处理。由于同样的事实可能会多次出现在不同的规则条件中,Rete算法通过共享匹配状态避免了重复计算。同时,结构相似性则体现在规则条件的模式上,通过模式的共用减少了网络的复杂性,降低了计算成本。
然而,Rete算法并非没有局限性。在处理动态改变的事实或复杂的规则结构时,网络可能会变得庞大且难以维护。此外,对于某些特定的规则模式,如嵌套条件或循环依赖,Rete算法的效率可能会降低。
总结来说,Rete算法是规则引擎中一种重要的匹配算法,它通过构建高效的网络结构,实现了对大量规则和事实的快速匹配。在实际应用中,如Drools等,Rete算法极大地提高了规则引擎的性能,使其成为业务决策和自动化中的有力工具。
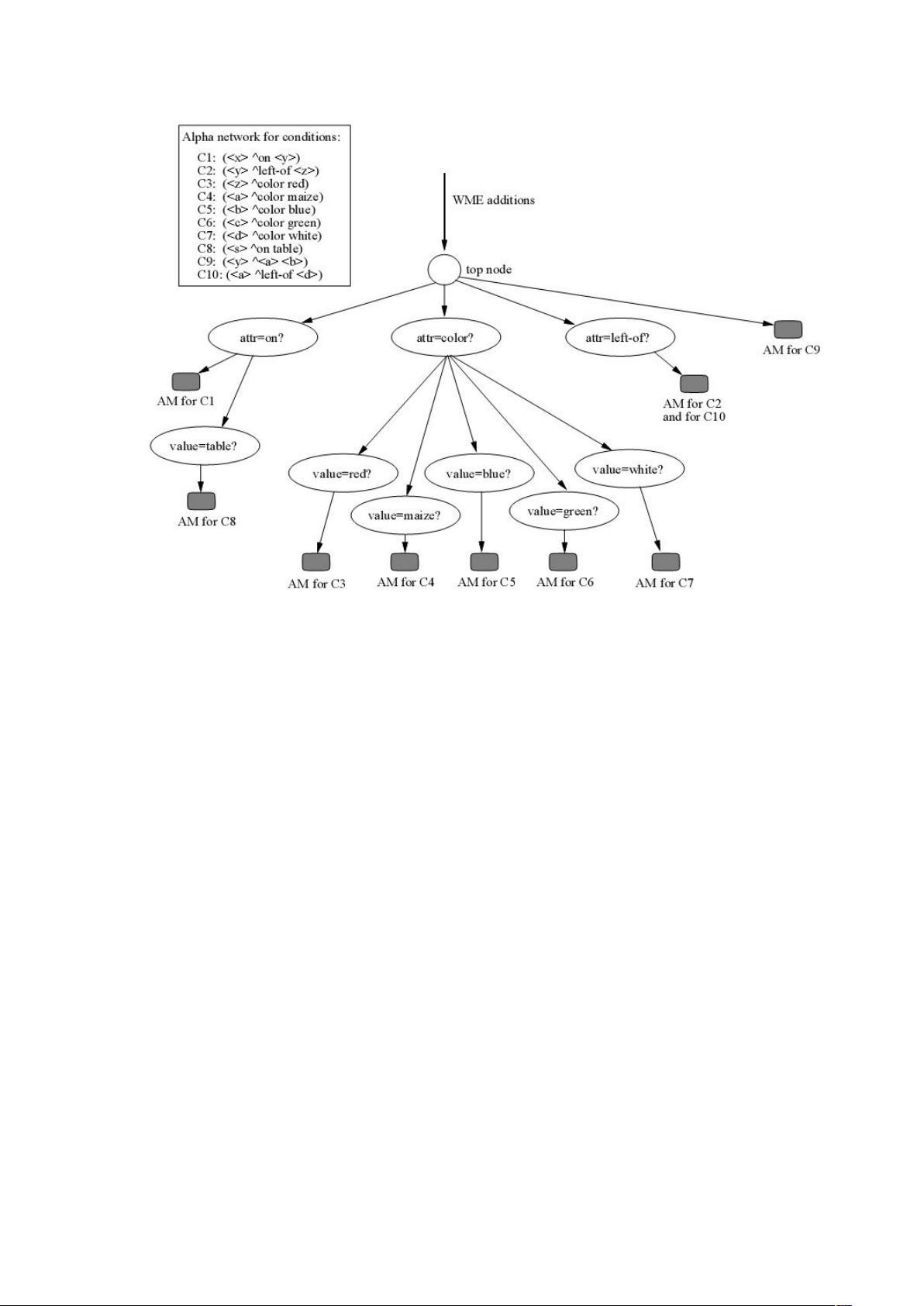
上面的 alpha 网络仅仅检测条件中的常量,如 attribute 项上的常量有 on,color,left-
of;value 项上的常量 redmaizebluegreenwhite。
4.4.2 带 HASHING 的数据流网络
上面的数据流网络的一个最大的缺点就是,当某个节点的扇出(fan-out)很大时,将会
做大量的无用功(wastedwork)。比如上图中对颜色的测试,某些专家系统可能含有
大量的颜色,那么将会有大量的比较操作,从而造成匹配操作变慢。
一个解决这个问题的方法就是对于那些带有很大扇出的节点,采用 hash 表(或者平衡
二叉树)来判断。
从上面的讨论可知,alpha 网络非常有效,随着事实集合的变化,alpha 网络可以几乎
可以马上作出相应处理。Beta 节点的处理占到了整个系统匹配的绝大部分时间。所以
一般研究的都针对网络中的 beta 节点进行。
4.5 内存节点
Alpha 内存存储事实集合,beta 内存存储 tokens(tokens 指规则中已经匹配好的事实绑
定)。
4.5.1 事实集合的结构
事实集合最简单的结构是采用链表结构。但是为了获得更高的效率,一般也给每个事
实内存加上索引(indexing)。最常用的索引方法是采用 Hash 表。也可以采用树,但
剩余27页未读,继续阅读
2022-12-24 上传
2022-11-28 上传
2024-07-24 上传
2022-06-08 上传
2023-03-09 上传
2022-11-12 上传
2022-05-29 上传
2021-08-03 上传

weixin_40289065
- 粉丝: 0
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
