Spark集群安装与WordCount实战
需积分: 16 68 浏览量
更新于2024-07-18
收藏 879KB DOCX 举报
"本资源主要介绍了如何在Spark集群上安装并使用Spark Shell编写WordCount程序,以及Spark的基本概念和特点。"
在大数据处理领域,Apache Spark是一个强大的工具,它提供了快速、通用且可扩展的数据分析功能。Spark的核心设计是基于内存计算,这使得它在处理大规模数据时能显著提升性能,尤其是在需要迭代计算的任务中。Spark最初由加州大学伯克利分校AMPLab开发,并于2010年开源,随后在2014年成为Apache顶级项目。Spark生态系统包括多个子项目,如Spark SQL用于结构化数据处理,Spark Streaming用于流处理,GraphX处理图数据,以及MLlib提供机器学习算法。
Spark的主要特点在于其内存计算模型。在执行任务时,Spark将中间结果存储在内存中,而不是像MapReduce那样频繁地将数据写入磁盘。这种设计极大地减少了I/O操作,提高了数据处理的速度。然而,为了容错,Spark引入了一种叫做弹性分布式数据集(RDD)的概念。RDD是不可变的数据集,如果某个部分数据丢失,可以通过其依赖关系(血统)重新计算恢复。
在实际操作中,我们可以在Spark Shell中使用Scala语言编写Spark程序。例如,要执行WordCount任务,首先需要启动HDFS,然后将文本文件上传到HDFS。接下来,在Spark Shell中,可以使用`sc.textFile`读取文件,接着通过`flatMap`、`split`、`map`和`reduceByKey`等函数进行词频统计,最后使用`sortBy`和`collect`整理并显示结果。值得注意的是,Spark是懒加载的,只有在调用行动操作(如`collect`)时,才会触发实际的计算。
学习Spark的原因在于其高效性和灵活性。与MapReduce相比,Spark在迭代计算上具有显著优势,因为数据不需要每次都写回磁盘。此外,Spark的API丰富多样,提供了包括转换(Transformations)和行动(Actions)在内的多种操作,使得开发者能够更方便地进行复杂的数据处理任务。Spark还能够与其他大数据工具(如Hadoop HDFS、HBase等)无缝集成,进一步增强了其通用性。
Spark是一个值得深入学习的现代大数据处理框架,尤其对于需要高性能计算和迭代应用的场景,如机器学习和图分析。通过掌握Spark,开发者可以构建出更加高效和灵活的数据处理解决方案。
的数据,包括 $%&、$1+ 和 /++" 等。这对于已经部署 $",, 集群的用户特
别重要,因为不需要做任何数据迁移就可以使用 的强大处理能力。 也可以不
依赖于第三方的资源管理和调度器,它实现了 ", 作为其内置的资源管理和调度
框架,这样进一步降低了 的使用门槛,使得所有人都可以非常容易地部署和使用
。此外, 还提供了在 =/ 上部署 ", 的 集群的工具。
2. Spark 集群安装
2.1. 安装
注意:安装 + 时,无需安装 +
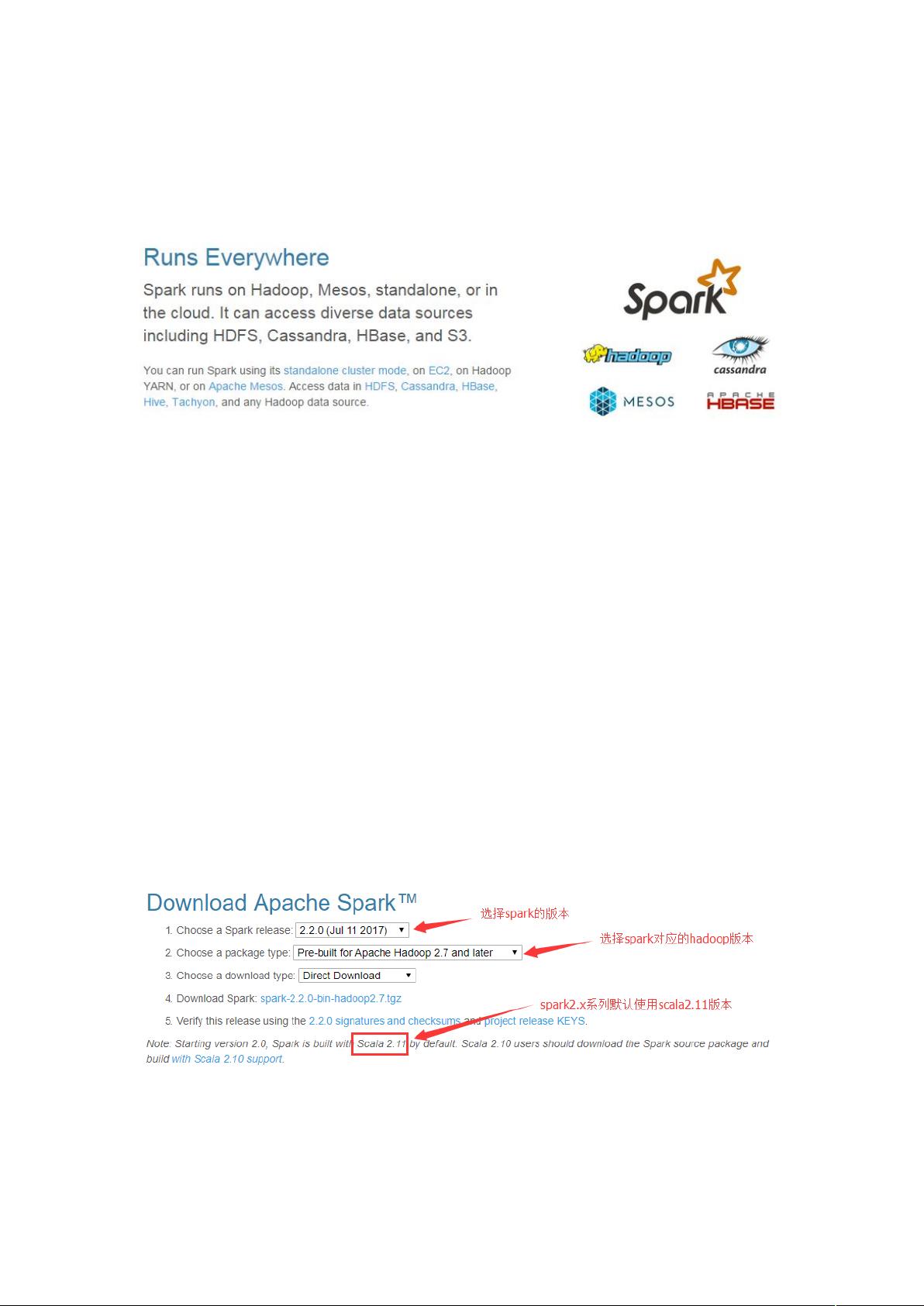
2.1.1. 下载 Spark 安装包
上传 +'安装包到 #> 上
解压安装包到指定位置
剩余17页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-07-22 上传
2018-08-28 上传
2018-09-12 上传
2016-03-04 上传
2024-04-18 上传
2023-03-16 上传

weixin_38983357
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- cpp_from_control_to_objects_8e:从C到对象,从控制结构开始,第8版
- import:R的导入机制
- vue2+vue-router+es6+webpack+node+mongodb的项目.zip
- Golang中的神经网络+培训框架-Golang开发
- 仅在页脚部分的最后一页的最底部打印表格页脚
- mac-config:Brewfile和脚本来设置全新的Mac安装
- writexl:轻巧的便携式数据帧,用于R的xlsx导出器
- Bootstrap模态登录框
- exif_read.rar_图形图像处理_Visual_C++_
- 福橘-股票行情-crx插件
- :magnifying_glass_tilted_right::bug:Golang fmt.Println调试和跟踪工具,能够可视化函数调用路径。-Golang开发
- 投资组合:我的个人投资组合以及由React提供的Dot Net服务器
- streamy-server
- voices:p5.js小实验
- New Tab Wallpaper-crx插件
- xml-website:监控项目的网站
