Hadoop与Spark集群安装教程:Linux环境配置详解
需积分: 9 3 浏览量
更新于2024-07-19
收藏 638KB DOCX 举报
本文档详细介绍了如何在Linux系统环境下安装和配置大数据集群,主要针对Hadoop2.0和Spark。以下是关键知识点的总结:
1. **Hadoop Master节点设置**:
- 主机名配置:首先,确认并修改HadoopMaster节点的主机名为"hadoopadmin",通过运行特定命令并检测主机名是否已更新。
- 防火墙管理:关闭所有节点的防火墙,通过图形界面确认并执行相应操作。
- `/etc/hosts` 文件配置:在所有节点上编辑hosts文件,添加主机名映射。
- Java安装:确保每个节点安装Java,使用RPM包并配置全局JAVA_HOME变量。
2. **Hadoop Slave节点设置**:
- 与Master节点类似,对Hadoopslave节点(如hadoop2)进行相同的主机名和hosts文件配置。
- 免密钥登录配置:在iespark用户下,生成SSH密钥对,复制公钥并将其添加到authorized_keys文件中,确保文件权限正确。
3. **Java环境设置**:
- 安装Java并配置环境变量,确保系统中全局可用的JAVA_HOME指向正确的Java安装路径。
4. **免密钥登录**:
- 在iespark用户下,通过SSH密钥对实现安全的免密登录,生成密钥并进行相关文件操作。
5. **安装Hadoop2.0**:
- 提供了详细的安装步骤,包括操作系统配置、防火墙、主机名和hosts文件的调整,以及Java的安装和环境变量配置。
6. **Spark安装**:
- 虽然标题只提到Hadoop,但通常情况下,Spark也会作为大数据处理的一部分被安装在Hadoop集群中,可能涉及类似的配置步骤。
这些步骤对于搭建一个基本的大数据处理环境至关重要,特别是对于Hadoop生态系统的理解和实践。在实际操作时,需要确保网络连接稳定,权限设置正确,并且遵循最佳实践以提高集群性能和安全性。
软件安装手册
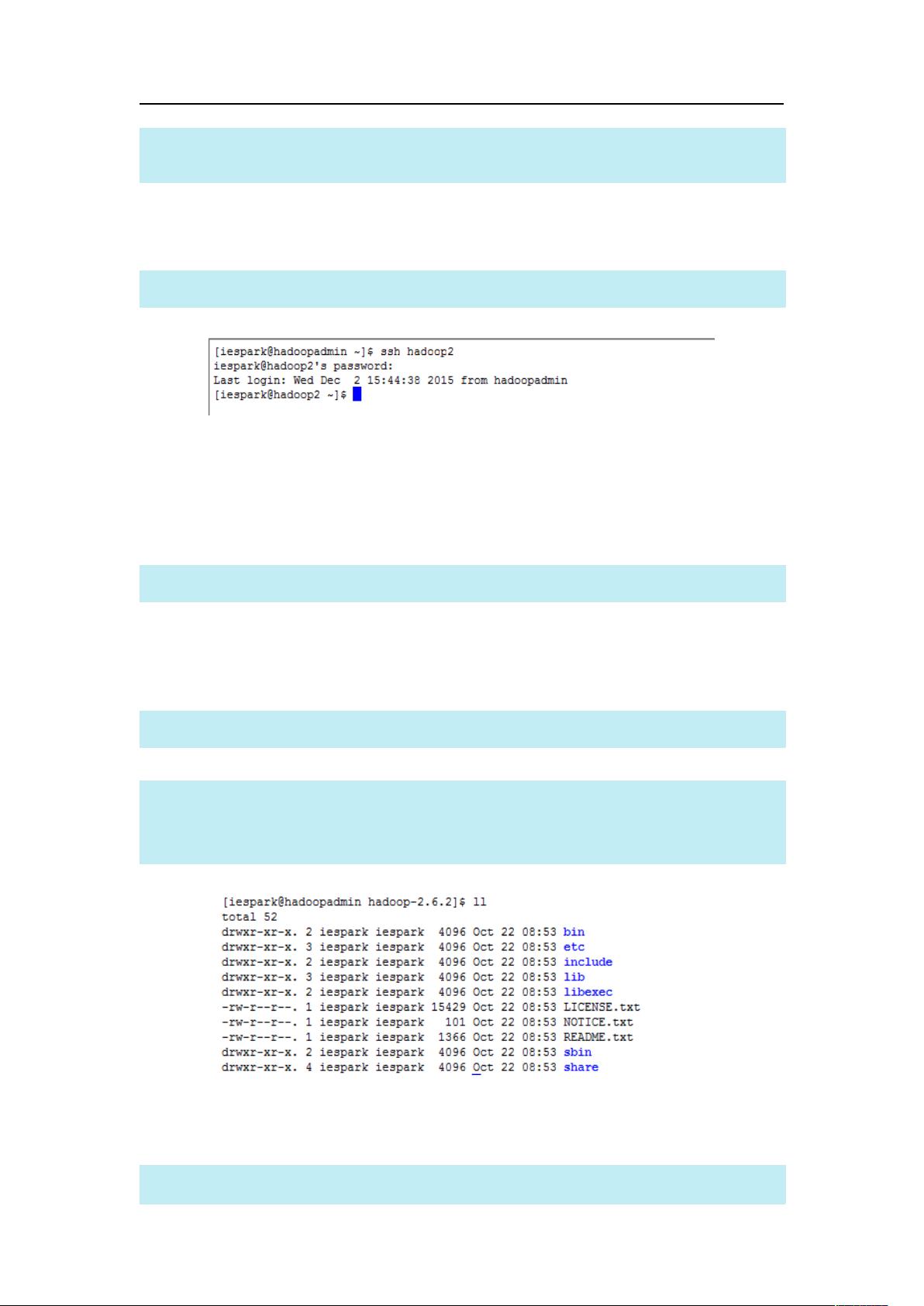
3、验证免密钥登陆
在 hadoopadmin 机器上执行下面的命令:
如果出现下图的内容表示免密钥配置成功:
2. Hadoop 配置部署
每个节点上的 Hadoop 配置基本相同,在 HadoopMaster 节点操作,然后完成复制到另
一个节点。
下面所有的操作都使用 iespark 用户,切换 iespark 用户的命令是:
密码是:iespark
2.1 Hadoop 安装包解压
进入 Hadoop 软件包,命令如下:
复制并解压 Hadoop 安装包命令如下:
ll 看到如下图的内容,表示解压成功:
2.2 配置环境变量 hadoop-env.sh
环境变量文件中,只需要配置 JDK 的路径。
/(%
'@1&%'(6(%%
(&%'(/)2)%<;&%'(6(%$61
';&%'(6(%$61
%/-A&%'(/)2)%<
;&%'(6(%$61&%'(/)2)&%'(&%'(/&
';&
&$'2%&<'6
&&%'()
剩余29页未读,继续阅读
2018-11-27 上传
2021-12-24 上传
2023-03-04 上传
2023-09-08 上传
2023-07-28 上传
2023-03-26 上传
2023-08-12 上传
2023-03-14 上传

繁华落叶草
- 粉丝: 52
- 资源: 18
 我的内容管理
展开
我的内容管理
展开







最新资源
- AirKiss技术详解:无线传递信息与智能家居连接
- Hibernate主键生成策略详解
- 操作系统实验:位示图法管理磁盘空闲空间
- JSON详解:数据交换的主流格式
- Win7安装Ubuntu双系统详细指南
- FPGA内部结构与工作原理探索
- 信用评分模型解析:WOE、IV与ROC
- 使用LVS+Keepalived构建高可用负载均衡集群
- 微信小程序驱动餐饮与服装业创新转型:便捷管理与低成本优势
- 机器学习入门指南:从基础到进阶
- 解决Win7 IIS配置错误500.22与0x80070032
- SQL-DFS:优化HDFS小文件存储的解决方案
- Hadoop、Hbase、Spark环境部署与主机配置详解
- Kisso:加密会话Cookie实现的单点登录SSO
- OpenCV读取与拼接多幅图像教程
- QT实战:轻松生成与解析JSON数据
