深入解析MyISAM与InnoDB索引机制及其优化策略
183 浏览量
更新于2024-08-27
收藏 785KB PDF 举报
在Java高级编程中,MySQL索引的实现与数据库的存储引擎密切相关。本文主要关注MyISAM和InnoDB两种常见的MySQL存储引擎,它们对于索引处理的方式有着显著的差异。
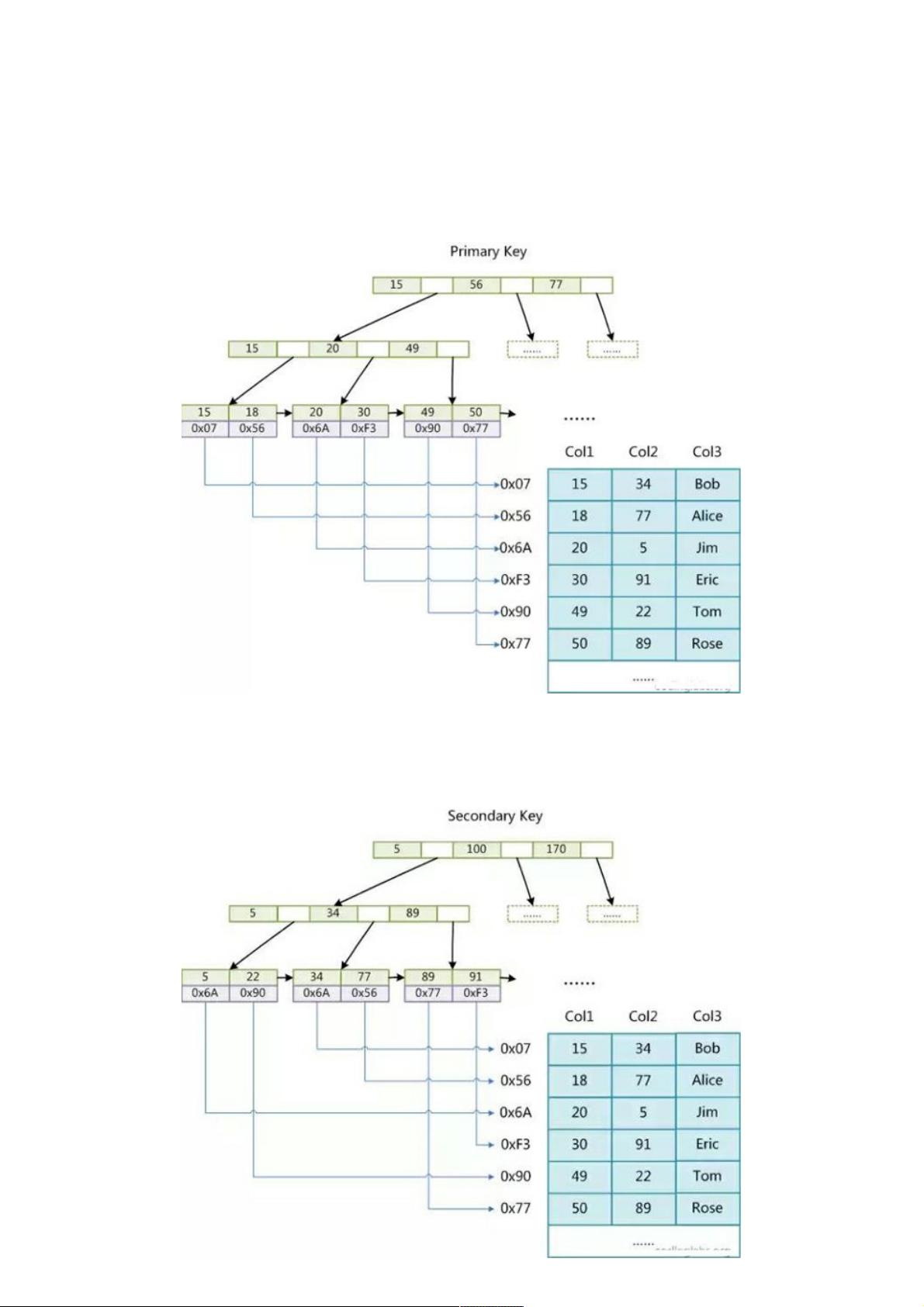
MyISAM引擎是基于B+Tree的数据结构,它的索引实现特点是使用单独的索引文件,如图1所示,叶节点包含数据记录的地址,而不是实际数据。主索引(Primarykey)和辅助索引(Secondarykey)在MyISAM中的结构相同,只是主索引的键值必须唯一,而辅助索引允许键值重复。搜索时,通过B+Tree搜索找到索引,再根据找到的地址读取数据记录。这种方式被称为"非聚集"索引,因为数据记录并不直接存储在索引中。
相比之下,InnoDB存储引擎则完全不同。InnoDB将数据和索引紧密集成在一起,数据文件本身就是索引的一部分,特别是主键索引。如图3所示,InnoDB的主索引即数据文件,每个叶节点包含完整的数据记录,这就形成了聚集索引。InnoDB要求每个表都有主键,如果没有显式指定,系统会选择一个可以唯一标识数据的列作为默认主键。此外,InnoDB的辅助索引(如在Col2上建立的)存储的是数据记录的地址,而非完整数据,这与MyISAM的辅助索引形成对比。
索引优化对于提高查询性能至关重要。在MyISAM中,为了减少I/O操作,可以选择合适的列作为索引,特别是在经常用于WHERE子句筛选条件的列上。而在InnoDB中,由于数据和索引的融合,主键索引的查询效率通常较高,但若需要频繁地进行范围查询,可能需要创建覆盖索引或者考虑其他策略来优化性能。
总结来说,Java高级编程中理解和优化MySQL索引的关键在于理解不同存储引擎的索引实现机制。MyISAM和InnoDB在索引结构、数据存储位置以及索引类型上有显著区别,这些差异直接影响到查询速度和存储效率。熟练掌握这些知识,有助于编写更高效的SQL查询,并在实际项目中做出正确的决策。
Java高级编程高级编程——MySQL索引实现及优化原理解析索引实现及优化原理解析
在MySQL中,索引属于存储引擎级别的概念,不同存储引擎对索引的实现方式是不同的,本文主要讨论MyISAM和InnoDB两
个存储引擎的索引实现方式。
MyISAM索引实现MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址。下图是MyISAM索引的
原理图:
图 1
这里设表一共有三列,假设我们以Col1为主键,则图1是一个MyISAM表的主索引(Primary key)示意。可以看出MyISAM的
索引文件仅仅保存数据记录的地址。在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索
引要求key是唯一的,而辅助索引的key可以重复。如果我们在Col2上建立一个辅助索引,则此索引的结构如下图所示:
下载后可阅读完整内容,剩余6页未读,立即下载
2021-09-14 上传
2021-09-24 上传
2021-09-22 上传
2021-12-01 上传
2023-09-18 上传
2021-01-31 上传
2024-05-21 上传
2021-10-26 上传

weixin_38608378
- 粉丝: 4
- 资源: 857
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索数据转换实验平台在设备装置中的应用
- 使用git-log-to-tikz.py将Git日志转换为TIKZ图形
- 小栗子源码2.9.3版本发布
- 使用Tinder-Hack-Client实现Tinder API交互
- Android Studio新模板:个性化Material Design导航抽屉
- React API分页模块:数据获取与页面管理
- C语言实现顺序表的动态分配方法
- 光催化分解水产氢固溶体催化剂制备技术揭秘
- VS2013环境下tinyxml库的32位与64位编译指南
- 网易云歌词情感分析系统实现与架构
- React应用展示GitHub用户详细信息及项目分析
- LayUI2.1.6帮助文档API功能详解
- 全栈开发实现的chatgpt应用可打包小程序/H5/App
- C++实现顺序表的动态内存分配技术
- Java制作水果格斗游戏:策略与随机性的结合
- 基于若依框架的后台管理系统开发实例解析
