
第08章_聚合函数
我们上一章讲到了 SQL 单行函数。实际上 SQL 函数还有一类,叫做聚合(或聚集、分组)函数,它是对
一
组数据进行汇总的函数,输入的是一组数据的集合,输出的是单个值。
1.
聚合函数介绍
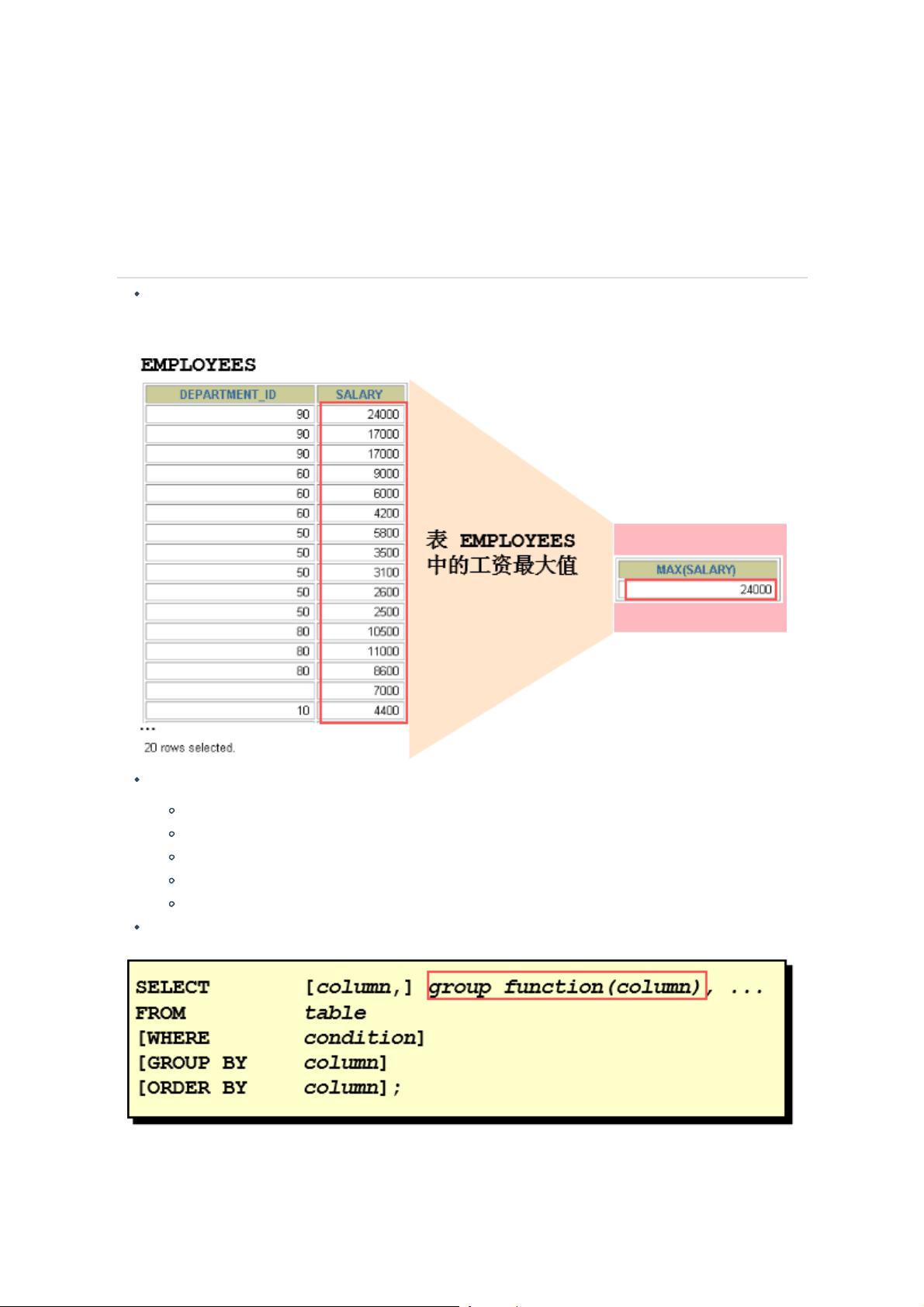
什么是聚合函数
聚合函数作用于一组数据,并对一组数据返回一个值。
聚合函数类型
AVG()
SUM()
MAX()
MIN()
COUNT()
聚合函数语法
下载后可阅读完整内容,剩余8页未读,立即下载

冰蓝星
- 粉丝: 240
- 资源: 28
 我的内容管理
展开
我的内容管理
展开







最新资源
- Hadoop生态系统与MapReduce详解
- MDS系列三相整流桥模块技术规格与特性
- MFC编程:指针与句柄获取全面解析
- LM06:多模4G高速数据模块,支持GSM至TD-LTE
- 使用Gradle与Nexus构建私有仓库
- JAVA编程规范指南:命名规则与文件样式
- EMC VNX5500 存储系统日常维护指南
- 大数据驱动的互联网用户体验深度管理策略
- 改进型Booth算法:32位浮点阵列乘法器的高速设计与算法比较
- H3CNE网络认证重点知识整理
- Linux环境下MongoDB的详细安装教程
- 压缩文法的等价变换与多余规则删除
- BRMS入门指南:JBOSS安装与基础操作详解
- Win7环境下Android开发环境配置全攻略
- SHT10 C语言程序与LCD1602显示实例及精度校准
- 反垃圾邮件技术:现状与前景
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


