大数据技术:存储、计算与分析模型的探索
需积分: 10 105 浏览量
更新于2024-07-18
收藏 2.45MB PDF 举报
"大数据技术综述"
随着信息技术的飞速发展,大数据已成为研究者、政府决策者和企业领导者关注的焦点。在这个信息增长速度超越摩尔定律的新世纪,海量数据给人们带来了诸多挑战,但同时也隐藏着巨大的潜力和实用价值。大数据科学发现(DISD)这一新的科研范式应运而生,它主要解决的就是如何从庞大的数据中提取有价值的信息。
大数据技术的核心挑战主要围绕数据的存储、处理和分析。在存储方面,由于数据量的爆炸性增长,传统的数据库系统已经无法满足需求。因此,分布式存储系统如Hadoop的HDFS(Hadoop Distributed File System)和Google的Bigtable等应运而生,它们提供了大规模、高可用性和容错性的数据存储解决方案。
在计算问题上,大数据处理需要高效的并行和分布式计算能力。MapReduce作为Hadoop的核心计算框架,通过将复杂任务拆分为可并行执行的映射和化简阶段,极大地提升了处理效率。此外,Spark作为一种内存计算框架,进一步优化了数据处理速度,使得实时分析成为可能。
在数据分析模型方面,传统的统计模型如回归分析、聚类分析等仍然是基础工具,但在大数据环境下,机器学习算法的重要性日益凸显。支持向量机(SVM)、决策树、随机森林等算法被广泛应用于分类和预测任务。近年来,深度学习的崛起,如深度神经网络(DNN)、卷积神经网络(CNN)和循环神经网络(RNN),在图像识别、语音识别、自然语言处理等领域取得了突破性进展。同时,强化学习也逐渐崭露头角,通过与环境的交互不断优化策略,为自动驾驶、游戏AI等领域带来了革新。
云计算为大数据处理提供了基础设施即服务(IaaS)、平台即服务(PaaS)和软件即服务(SaaS)的模式,使得企业可以按需获取计算资源,降低了大数据应用的门槛。例如,Amazon Web Services(AWS)、Microsoft Azure和Google Cloud Platform等云服务商提供了丰富的数据处理和分析服务。
大数据技术的发展涵盖了从数据采集、存储、处理到分析的全过程,涉及众多领域,如经济学、商业活动、公共管理、自然科学等。随着技术的不断进步,大数据将继续推动科学、社会和经济的创新,为我们揭示隐藏在海量数据背后的未知世界。
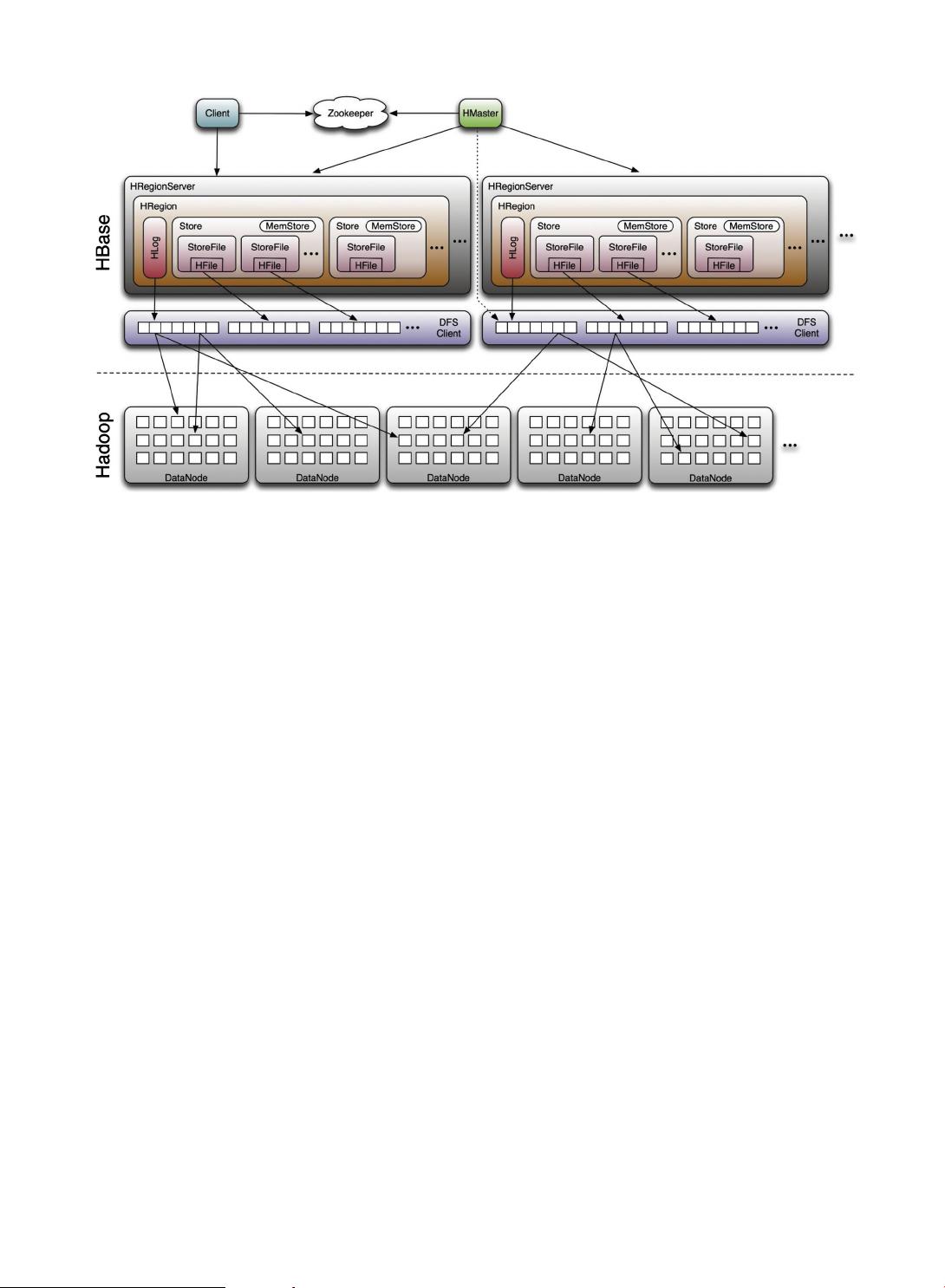
(see Fig. 4). However, many Big Data analytic platforms, like SQLstream and Cloudera Impala, series still use SQL in its data-
base systems, because SQL is more reliable and simpler query language with high performance in stream Big Data real-time
analytics.
To store and manage unstructured data or non-relational data, NoSQL employs a number of specific approaches. Firstly,
data storage and management are separated into two independent parts. This is contrary to relational databases which try to
meet the concerns in the two sides simultaneously. This design gives NoSQL databases systems a lot of advantages. In the
storage part which is also called key-value storage, NoSQL focuses on the scalability of data storage with high-performance.
In the management part, NoSQL provides low-level access mechanism in which data management tasks can be implemented
in the application layer rather than having data management logic spread across in SQL or DB-specific stored procedure lan-
guages [37]. Therefore, NoSQL systems are very flexible for data modeling, and easy to update application developments and
deployments [60].
Most NoSQL databases have an important property. Namely, they are commonly schema-free. Indeed, the biggest advan-
tage of schema-free databases is that it enables applications to quickly modify the structure of data and does not need to
rewrite tables. Additionally, it possesses greater flexibility when the structured data is heterogeneously stored. In the data
management layer, the data is enforced to be integrated and valid. The most popular NoSQL database is Apache Cassandra.
Cassandra, which was once Facebook proprietary database, was released as open source in 2008. Other NoSQL implementa-
tions include SimpleDB, Google BigTable, Apache Hadoop, MapReduce, MemcacheDB, and Voldemort. Companies that use
NoSQL include Twitter, LinkedIn and NetFlix.
3.2.4. Data analysis
The first impression of Big Data is its volume, so the biggest and most important challenge is scalability when we deal
with the Big Data analysis tasks. In the last few decades, researchers paid more attentions to accelerate analysis algorithms
to cope with increasing volumes of data and speed up processors following the Moore’s Law. For the former, it is necessary to
develop sampling, on-line, and multiresolution analysis methods [59]. In the aspect of Big Data analytical techniques, incre-
ment algorithms have good scalability property, not for all machine learning algorithms. Some researchers devote into this
area [180,72,62]. As the data size is scaling much faster than CPU speeds, there is a natural dramatic shift [8] in processor
technology—although the clock cycle frequency of processors is doubling following Moore’s Law, the clock speeds still highly
lag behind. Alternatively, processors are being embedded with increasing numbers of cores. This shift in processors leads to
the development of parallel computing [130,168,52].
For those real-time Big Data applications, like navigation, social networks, finance, biomedicine, astronomy, intelligent
transport systems, and internet of thing, timeliness is at the top priority. How can we grantee the timeliness of response
when the volume of data will be processed is very large? It is still a big challenge for stream processing involved by Big Data.
It is right to say that Big Data not only have produced many challenge and changed the directions of the development of the
hardware, but also in software architectures. That is the swerve to cloud computing [50,186,7,48], which aggregates multiple
disparate workloads into a large cluster of processors. In this direction, distributed computing is being developed at high
speed recently. We will give a more detail discussion about it in next section.
Fig. 4. Hbase NoSQL database system architecture. Source: from Apache Hadoop.
320 C.L. Philip Chen, C.-Y. Zhang / Information Sciences 275 (2014) 314–347
剩余33页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-01-20 上传
2021-11-06 上传
2021-07-07 上传
2021-11-06 上传

kenan716
- 粉丝: 0
- 资源: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- RichardRNStudio
- wnl.rar_Java编程_Java_
- word2vec:Google的Python接口word2vec
- :rocket:可定制的圆形/线性进度条软件包,支持动画文本,使用SwiftUI构建-Swift开发
- The Flow Of Time-crx插件
- 可运营的SSL证书在线生成系统源码,附带图文搭建教程
- grb:通过HTTP进行争夺从未如此简单
- vgg19-tensorflowjs-model::memo:Tensorflow.js VGG-19的预训练模型
- vault-kustomization
- composify:将WordPress插件zip文件转换为git存储库,以便composer版本约束正常运行
- 基于C#实现的普通图像读取及遥感图像处理
- student.rar_教育系统应用_Visual_C++_
- matlab哈士奇代码-Husky:沙哑
- PSI In-application Extension-crx插件
- 猫鼬简介:Ejemplo de un ORMbásicocreado con mongosse para mongo
- qtff-2001.zip_文件格式_Visual_C++_
