
S. Zhu
,
G.
孙角,澳
-
地
Jiang
等
人
视觉信息学
4
(
2020
)
24
27
见图
4
。
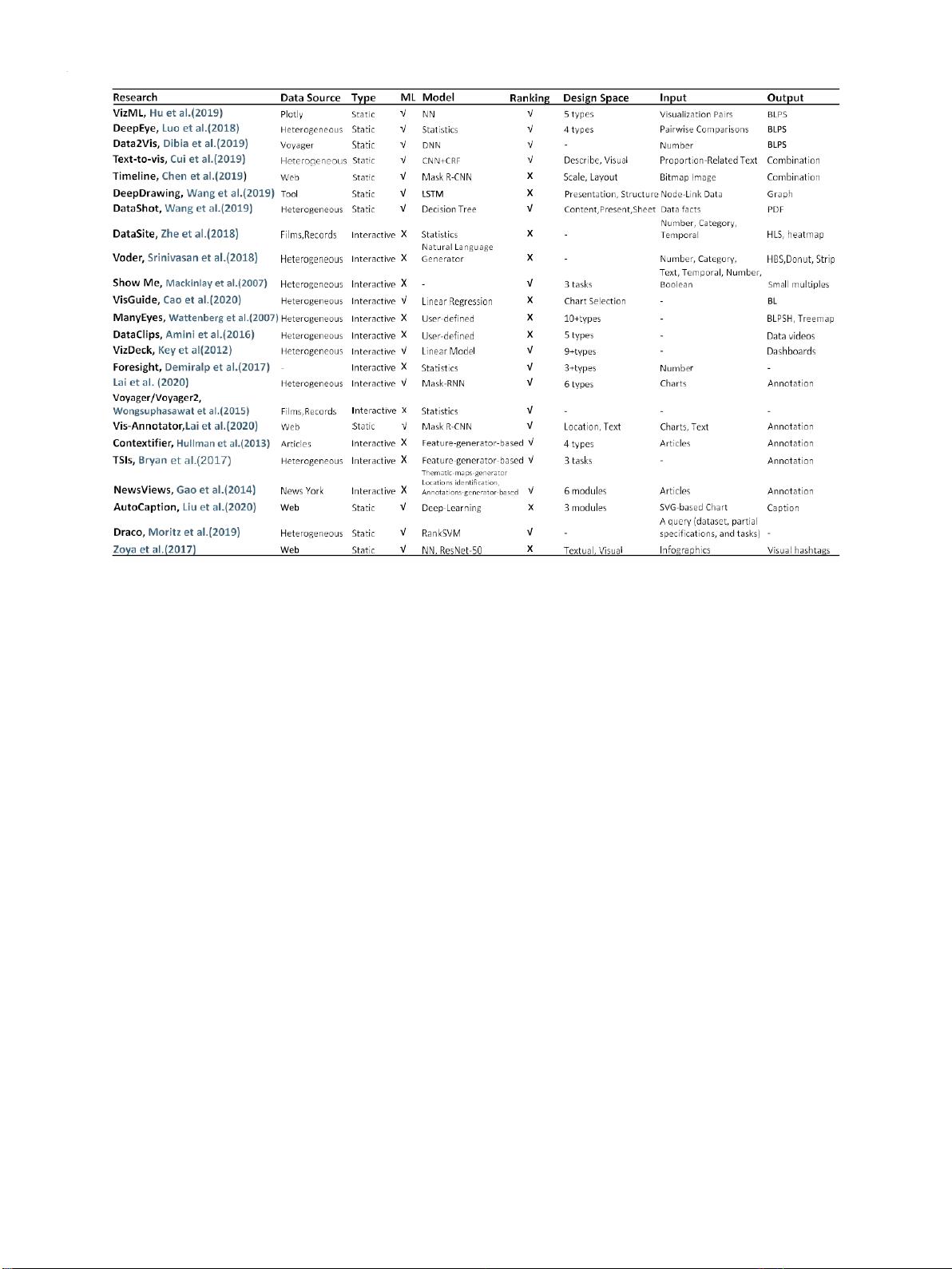
某些自动可视化生成器的摘要。条形图(B)、直线(L)、饼图(P)、散点图(S)和直方图(H)是大多数自动工具可以生成的常见可视化。 系统/工具支持各
种算法来对视觉或文本呈现进行排名。
它是第一个通过训练模型来推荐可视化的自动系统,该模型学
习数据记录和可视化属性之间的相关性,以预测用户偏好的图
表 。 Zhe 等 ( 2018 ) 然 后 采 取 了 更 进 一 步 的 措 施 , 提 出 了
DataSite
, 专 注 于 自 动 算 法 库 的 连 续 计 算 。
Srinivasan
等 人
(
2018
)介绍了
Voder
,它使用一系列统计函数将自然语言生成技
术结合Dibia和Demiralp(2019)提出
了
Data2Vis
,它使用递归神
经网络自动将
JSON
格式的数据集转换为可视化规范。这种方法与
长短期记忆相结合,创建了一个端到端的生成模型,该模型使用
Vega-Lite中创建的约4300个可视化示例进行训练(Satyanarayan
et al. ,2016年)。图6显示了可视化示例,这些示例是在给定种
族数据集时由
Data2vis
然而,从图表中提取和解释视觉元素是一个关键的挑战
.
为了解
决这个问题,
Sue
,
Battle et al.
(
2018
)提出了一种从互联网中
自动提取可视化并使用注释描述从收集的可视化中,最常见的可
视化类型是条形图、折线图、散点图和地理地图。因此,他们在
网络上提取基于SVG的基于这种方法,Hu等人(2019)引入
了
VizML
。该模型通过从公共可视化社区收集的
1000
,
000
个可视化
对进行训练,这些可视化对的数量级大于
Data2Vis
和
DeepEye
。
VizML
提供了一个重要的度量解释的特征,并将其集成到可视化
界面。上述技术可以自动生成公共信息,
图形,有一些挑战:
用于收集和标记训练数据的可扩展方法。它是一种缺乏公共性
和全面性的视觉原始
图书馆这一挑战不仅涉及从大量信息图表中识别和提取项
目,还涉及视觉项目的标签和描述,这些项目可能在字段中
表达不同的含义。
缺乏机器学习模型的可解释性和可解释性可解释性与用户自
定义规则相结合可以进一步提高可视化推荐的质量。
3.2.
自动注释
标注在帮助人们理解图表和表达设计者的信息方面起着越来越
重要的作用。 它已被广泛用于各种应用中,例如辅助讲故事的有
效分析(
Bylinskii et al.
,
2017
) 、 错 误 检 测 (
Grammarly
,
2012
)和分类(
Júnior et al.
,
2017
年)。注释在视觉上指向突出
的数据特征或视觉元素。本节回顾自动数据驱动注释,而基于知
识的注释可参见第
4.2
节。
很多工作都是用各种方法来达到目的的 自动注释。
Kandogan
(
2012
)提出了一个工作流程,主要包括:视觉特征检测、特征排
序和生成注释。
Lai
等人(
2020
年)提出 一个全面的自动注释工
作流程,它的灵感来自手动注释的过程。该工作流程由四个部分组
成:用于识别图表中的可视实体和可视文本的对象检测、用于解析描
述以生成对所描述的实体的查询的
NLP
、用于实现查询以将每个句
子锚定到对应图像的位置的注释以及描述图表。自动注释的过程涉及
自动识别和描述
/
突出显示关键视觉元素(
Kandogan
,
2012
)。
·
·
剩余16页未读,继续阅读

cpongm
- 粉丝: 5
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 新型矿用本安直流稳压电源设计:双重保护电路
- 煤矿掘进工作面安全因素研究:结构方程模型
- 利用同位素位移探测原子内部新型力
- 钻锚机钻臂动力学仿真分析与优化
- 钻孔成像技术在巷道松动圈检测与支护设计中的应用
- 极化与非极化ep碰撞中J/ψ的Sivers与cos2φ效应:理论分析与COMPASS验证
- 新疆矿区1200m深孔钻探关键技术与实践
- 建筑行业事故预防:综合动态事故致因理论的应用
- 北斗卫星监测系统在电网塔形实时监控中的应用
- 煤层气羽状水平井数值模拟:交替隐式算法的应用
- 开放字符串T对偶与双空间坐标变换
- 煤矿瓦斯抽采半径测定新方法——瓦斯储量法
- 大倾角大采高工作面设备稳定与安全控制关键技术
- 超标违规背景下的热波动影响分析
- 中国煤矿选煤设计进展与挑战:历史、现状与未来发展
- 反演技术与RBF神经网络在移动机器人控制中的应用
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


