HashMap深度解析:从JDK1.7到JDK1.8的变化
HashMap是Java编程中常用的数据结构之一,主要用于存储键值对数据。它的实现原理涉及到了哈希函数、数组和链表(或红黑树)等核心概念。本文将深入解析HashMap的内部工作机制,以及为何选择这样的设计。
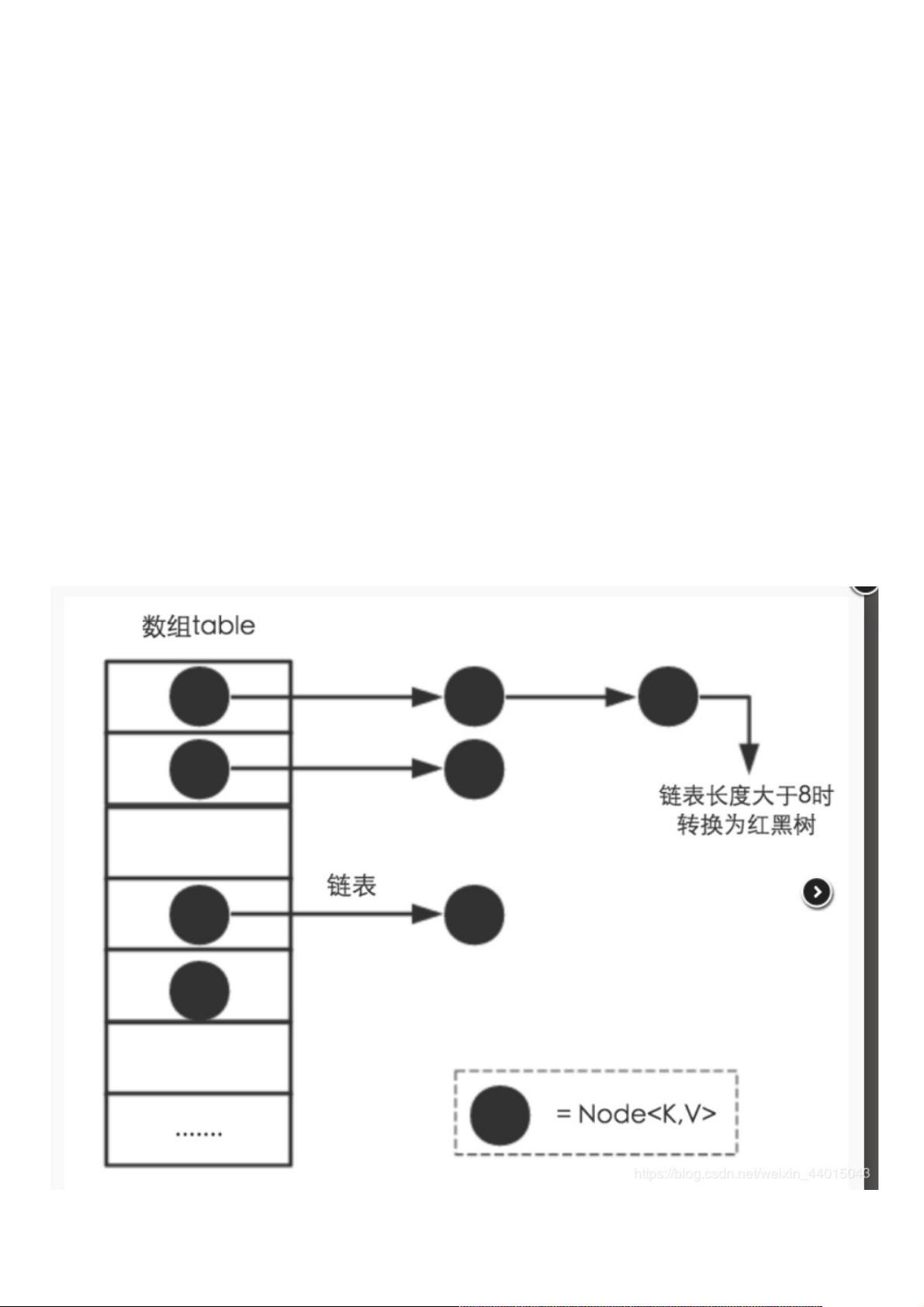
在JDK 1.7中,HashMap基于一个Entry数组实现,每个Entry是一个链表的节点,用于存储键值对。当多个键通过哈希函数映射到同一个数组索引位置时,这些键值对会形成链表。在JDK 1.8中,为了优化性能,引入了红黑树的概念。当链表长度超过8个元素时,链表会转换为红黑树,以降低查找、插入和删除操作的时间复杂度。
HashMap的核心变量有以下几个:
1. DEFAULT_INITIAL_CAPACITY: 初始化容量,设置为1 << 4,即16。容量通常设定为2的幂,因为哈希函数的结果通常会与容量进行与运算,以确定数组索引。2的幂能够确保除法后结果为整数,从而简化计算。
2. MAXIMUM_CAPACITY: 表示HashMap可容纳的最大元素数量,1 << 30,即1073741824。这是考虑到内存限制和性能平衡的一个上限。
3. DEFAULT_LOAD_FACTOR: 负载因子,默认为0.75。当元素数量达到数组长度的0.75倍时,HashMap会自动扩容,以保持性能。
4. TREEIFY_THRESHOLD: 链表转换为红黑树的阈值,为8。当一个桶(bucket)中的元素数量达到8时,链表将被转换为红黑树。
5. UNTREEIFY_THRESHOLD: 红黑树转换回链表的阈值,为6。在缩容或调整大小时,如果桶中的红黑树节点数量少于6,将红黑树转回链表。
6. MIN_TREEIFY_CAPACITY: 最小树化阈值,64。当整个HashMap元素数量超过此值时,即使桶中元素不足8个,也会进行树化,避免频繁扩容和树化操作。
HashMap的工作流程如下:
1. 当插入一个新的键值对时,首先通过哈希函数计算键的哈希值,然后用这个值对数组长度取模,得到对应的数组索引。
2. 如果索引位置为空,直接插入新的Entry。如果已有元素,新元素将链接到已存在的链表(或红黑树)中。
3. 当HashMap达到负载因子限制时,会创建一个新的、容量更大的数组,并将所有元素重新哈希到新数组中,这个过程称为扩容。
4. 查找、删除和更新操作也是通过哈希值定位到数组索引,然后沿着链表(或红黑树)找到对应的Entry进行操作。
使用链表+数组而非单纯的LinkedList,主要是为了兼顾空间效率和查找效率。数组提供快速访问,而链表则用于处理哈希冲突。相比于LinkedList,数组在内存中连续存储,可以更快地通过索引访问。当冲突发生时,链表用于链接相同索引位置的元素。然而,如果链表过长,会导致查找效率下降,因此在JDK 1.8引入了红黑树,以减少查找时间。
面试中可能会问到的问题包括:
1. 描述HashMap的内部结构和工作原理。
2. 为什么HashMap的容量通常是2的幂?
3. 解释负载因子的作用,以及何时会发生扩容。
4. 什么是哈希冲突,如何解决?
5. JDK 1.8中为什么引入红黑树,它的优势是什么?
6. HashMap的并发问题,为什么不能在多线程环境下直接使用HashMap?
理解HashMap的实现原理不仅有助于日常编程,也是面试中常见的技术问题,对于提升Java开发者的技术素养至关重要。
看完还不懂看完还不懂HashMap算我输(附职场面试常见问题)算我输(附职场面试常见问题)
HashMap的原理与实现的原理与实现
版本之更迭:版本之更迭:
–》》JDK 1.7 : Table数组+ Entry链表;
–》》JDK1.8 : Table数组+ Entry链表/红黑树;(为什么要使用红黑树?)
一问一问HashMap的实现原理的实现原理
你看过HashMap源码吗,知道底层的原理吗
为什么使用数组+链表
用LinkedList代替数组可以吗
既然是可以的,为什么不用反而用数组。
重要变量介绍:重要变量介绍:
ps:都是重要的变量记忆理解一下最好。
DEFAULT_INITIAL_CAPACITY Table数组的初始化长度: 1 << 4 2^4=16(为什么要是 2的n次方?)
MAXIMUM_CAPACITY Table数组的最大长度: 1<<30 2^30=1073741824
DEFAULT_LOAD_FACTOR 负载因子:默认值为0.75。 当元素的总个数>当前数组的长度 * 负载因子。数组会进行扩容,扩容为原来的两倍
(todo:为什么是两倍?)
TREEIFY_THRESHOLD 链表树化阙值: 默认值为 8 。表示在一个node(Table)节点下的值的个数大于8时候,会将链表转换成为红黑
树。
UNTREEIFY_THRESHOLD 红黑树链化阙值: 默认值为 6 。 表示在进行扩容期间,单个Node节点下的红黑树节点的个数小于6时候,会将
红黑树转化成为链表。
MIN_TREEIFY_CAPACITY = 64 最小树化阈值,当Table所有元素超过改值,才会进行树化(为了防止前期阶段频繁扩容和树化过程冲
突)。
实现原理:实现原理:
实现原理图实现原理图 我们都知道,在HashMap中,采用数组+链表的方式来实现对数据的储存。
HashMap采Entry数组来存储key-value对,每个键值对组成了个Entry实体,Entry类实际上是个单向的链表结 构,它具有Next指针,
可以连接下个Entry实体。 只是在JDK1.8中,链表度于8的时候,链表会转成红树!
第一问:第一问: 为什么使用链表+数组:要知道为什么使用链表首先需要知道Hash冲突是如何来的:
下载后可阅读完整内容,剩余9页未读,立即下载
529 浏览量
2275 浏览量
112 浏览量
206 浏览量
2024-09-29 上传
2023-09-27 上传
2023-06-08 上传
118 浏览量

weixin_38663036
- 粉丝: 4
- 资源: 928
 我的内容管理
展开
我的内容管理
展开







最新资源
- spring&hibernate整合
- 操作手册(GB8567——88).doc
- Bluetooth Tutorial
- CANopen协议中文简介.pdf
- UML_Concept
- [Bruce.Eckel编程思想系列丛书].PRENTICE_HALL-Thinking_In_Python
- 达内oracle笔记
- Java数据库查询结果的输出
- linux0.11注释-赵炯
- ALV development operation guide
- exp/imp导出导入工具的使用
- 很完善的oracle函数手册
- Oracle傻瓜手册
- jdbc连接驱动大全
- HTML指令HTML指令
- ActionScript.3.0.Cookbook.中文完整版
