Hadoop高可用实践:ZooKeeper与HDFS HA集群搭建
183 浏览量
更新于2024-08-29
收藏 413KB PDF 举报
"基于 ZooKeeper 搭建 Hadoop 高可用集群的教程图解"
在构建大规模数据处理系统时,确保服务的高可用性至关重要。Hadoop 高可用(HA)设计旨在减少单点故障,提高系统的稳定性。本文将详细解析如何利用ZooKeeper来搭建Hadoop的HDFS和YARN的高可用集群。
Hadoop HA 主要关注两个核心组件:HDFS的NameNode和YARN的ResourceManager。NameNode作为HDFS的元数据管理器,而ResourceManager则负责YARN集群的资源调度。由于NameNode对数据一致性的要求更高,因此其HA实现更为复杂。
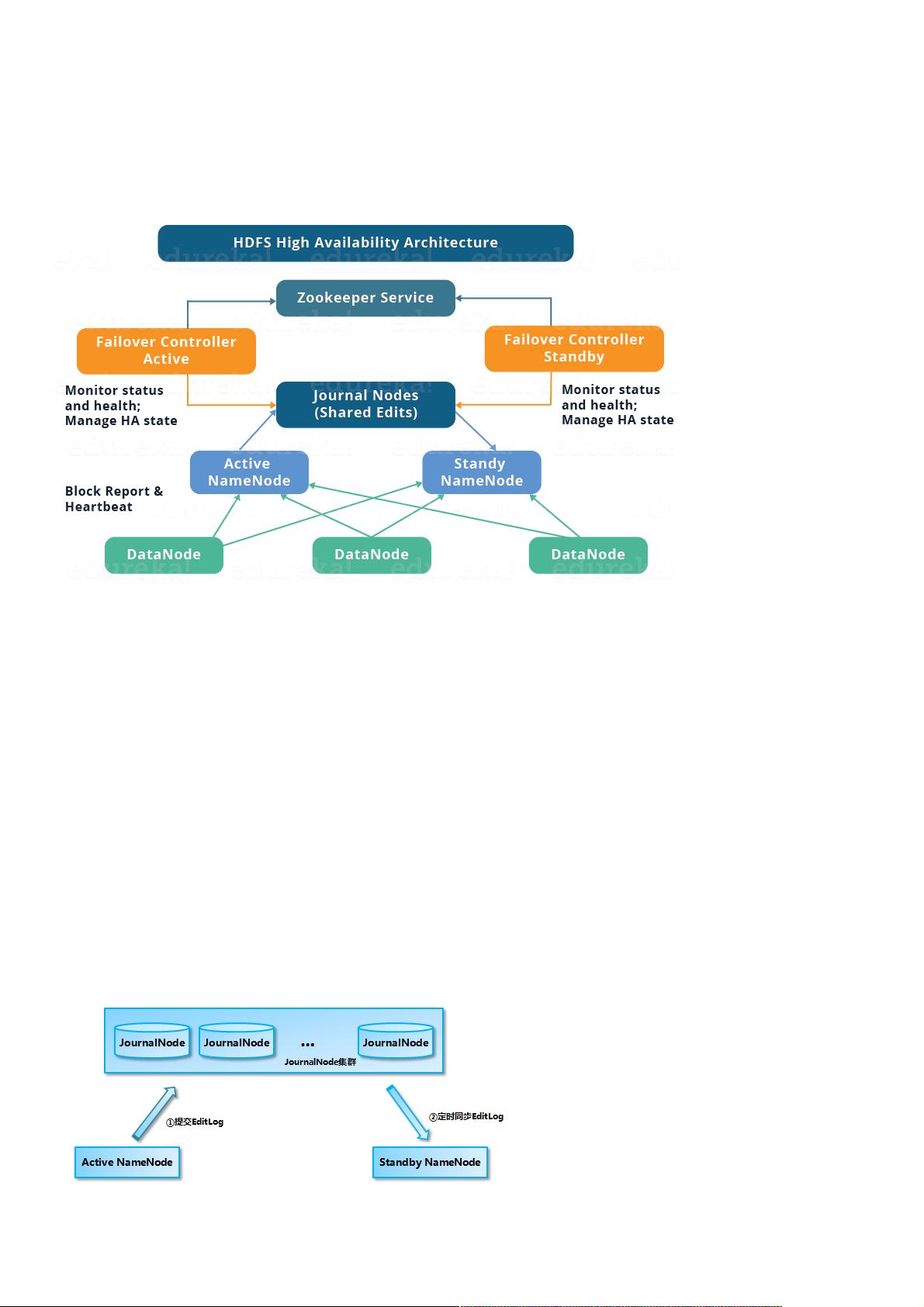
**1.1 HDFS高可用架构**
HDFS HA 架构的核心是Active和Standby两种状态的NameNode,它们通过Zookeeper集群进行主备切换。当Active NameNode出现故障时,Zookeeper中的ZKFailoverController会检测到并触发切换,将Standby NameNode提升为主。这个过程是自动的,确保了服务的连续性。
- **Active NameNode**:当前对外提供服务的NameNode,负责处理客户端的所有读写请求。
- **Standby NameNode**:备用的NameNode,时刻准备接管服务,但不直接处理客户端请求,而是通过共享存储系统与Active NameNode同步元数据。
- **Zookeeper集群**:用于NameNode的主备选举,确保在Active NameNode故障时快速、无冲突地进行切换。
- **共享存储系统**:如Quorum Journal Manager (QJM),保存HDFS的元数据,确保NameNode之间的数据同步。
**1.2 QJM的共享存储机制**
HDFS使用QJM作为默认的共享存储机制,它是一个分布式日志服务,保证了NameNode间元数据的一致性。QJM通过多数派原则(quorum)确保写入的成功,即使有部分JournalNode(QJM的一部分)失效,只要超过半数的JournalNode存活,数据就能被正确地记录和同步。
在主备切换时,新的Active NameNode首先会从QJM中读取所有未同步的事务日志,确保其元数据与旧主NameNode完全一致。只有在完成同步后,新主NameNode才会开始接收客户端请求,保证数据的一致性和完整性。
**1.3 YARN高可用**
YARN的高可用与HDFS类似,主要涉及ResourceManger的主备切换。ResourceManger同样依赖Zookeeper进行故障检测和主备切换。备用的ResourceManager在主节点故障时,会接管资源调度,确保应用的正常运行。
**1.4 配置和实践**
配置Hadoop HA需要考虑多个方面,包括Zookeeper集群的设置、NameNode和ResourceManager的配置、以及客户端的配置。具体步骤包括安装和配置Zookeeper,设置Hadoop的HA模式,配置ZKFailoverController,以及调整相关参数以优化性能和可靠性。
基于ZooKeeper搭建Hadoop的高可用集群是一项复杂但必要的任务,它通过引入冗余和自动化故障恢复机制,显著提升了Hadoop集群的稳定性和服务连续性。理解并掌握这一技术对于管理和维护大规模Hadoop集群至关重要。
基于基于 ZooKeeper 搭建搭建 Hadoop 高可用集群高可用集群 的教程图解的教程图解
一、高可用简介一、高可用简介
Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求比
YARN ResourceManger 高得多,所以它的实现也更加复杂,故下面先进行讲解:
1.1 高可用整体架构高可用整体架构
HDFS 高可用架构如下:
图片引用自:
https://www.edureka.co/blog/how-to-set-up-hadoop-cluster-with-hdfs-high-availability/
HDFS 高可用架构主要由以下组件所构成:
Active NameNode 和 Standby NameNode:两台 NameNode 形成互备,一台处于 Active 状态,为主 NameNode,另外一台处于 Standby 状态,为备
NameNode,只有主 NameNode 才能对外提供读写服务。
主备切换控制器 ZKFailoverController:ZKFailoverController 作为独立的进程运行,对 NameNode 的主备切换进行总体控制。ZKFailoverController 能
及时检测到 NameNode 的健康状况,在主 NameNode 故障时借助 Zookeeper 实现自动的主备选举和切换,当然 NameNode 目前也支持不依赖于
Zookeeper 的手动主备切换。
Zookeeper 集群:为主备切换控制器提供主备选举支持。共享存储系统:共享存储系统是实现 NameNode 的高可用最为关键的部分,共享存储系统保
存了 NameNode 在运行过程中所产生的 HDFS 的元数据。
主 NameNode 和 NameNode 通过共享存储系统实现元数据同步。在进行主备切换的时候,新的主 NameNode 在确认元数据完全同步之后才能继续对
外提供服务。
DataNode 节点:除了通过共享存储系统共享 HDFS 的元数据信息之外,主 NameNode 和备 NameNode 还需要共享 HDFS 的数据块和 DataNode 之间
的映射关系。
DataNode 会同时向主 NameNode 和备 NameNode 上报数据块的位置信息。
1.2 基于基于 QJM 的共享存储系统的数据同步机制分析的共享存储系统的数据同步机制分析
目前 Hadoop 支持使用 Quorum Journal Manager (QJM) 或 Network File System (NFS) 作为共享的存储系统,这里以 QJM 集群为例进行说明:Active
NameNode 首先把 EditLog 提交到 JournalNode 集群,然后 Standby NameNode 再从 JournalNode 集群定时同步 EditLog,当 Active NameNode 宕机
后, Standby NameNode 在确认元数据完全同步之后就可以对外提供服务。
需要说明的是向 JournalNode 集群写入 EditLog 是遵循 “过半写入则成功” 的策略,所以你至少要有3个 JournalNode 节点,当然你也可以继续增加节点
数量,但是应该保证节点总数是奇数。同时如果有 2N+1 台 JournalNode,那么根据过半写的原则,最多可以容忍有 N 台 JournalNode 节点挂掉。
1.3 NameNode 主备切换主备切换
NameNode 实现主备切换的流程下图所示:
下载后可阅读完整内容,剩余7页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-08-04 上传
2018-07-27 上传
2021-09-19 上传
2019-03-18 上传
2020-02-21 上传

weixin_38647925
- 粉丝: 2
- 资源: 913
 我的内容管理
展开
我的内容管理
展开







最新资源
- Sticker - Stock Ticker on Tab-crx插件
- CondutionLanding:The Condution Project(https)的登陆页面
- 专案
- OPENMV驱动云台实现颜色追踪
- continental:带有欧洲国家地图的符号字体
- Transferencia-Bancaria:NET应用程序
- rcs-rds.github.io:速度测试助手(主页)
- hckr news-crx插件
- website
- AO3402PDF规格书.rar
- 行业文档-设计装置-回转平台.zip
- MSK_microbit
- GeradorDeKeyRandomicoPython
- pingplacepicker:Google的Place Picker的即插即用替代品
- Fritzing H-Bridge with L298N.zip
- The Hindu Revamp-crx插件
