使用Apache Spark MLlib 2.x实现机器学习模型的生产化
需积分: 10 12 浏览量
更新于2024-07-18
收藏 1.45MB PDF 举报
"本文主要探讨如何使用Apache Spark MLlib 2.x将机器学习模型投入生产环境,由Richard Garris,一位 Principal Solutions Architect 提供指导。文章涵盖了Spark MLlib的最新版本,强调其在大数据创新中的作用,特别是对于企业级数据处理平台的支持。Databricks作为公司背景被提及,该公司对开源社区的贡献显著,并提供了包括集群调优、管理、交互式工作空间、生产管道自动化等在内的服务。此外,内容涉及不同角色(如数据科学家、数据工程师、BI分析师)的数据工作流程以及各种数据源(如云存储、数据仓库、数据湖)。"
Apache Spark MLlib 2.x 是一个重要的机器学习库,它包含了一系列用于机器学习的算法和实用工具,支持监督和无监督学习任务,如分类、回归、聚类、协同过滤等。在Spark MLlib 2.x中,改进了模型训练的效率和可扩展性,使其更适合大规模数据处理和分布式计算环境。
模型序列化是将训练好的机器学习模型转化为可存储和传输的格式的关键步骤。在生产环境中,模型可能需要跨不同的系统和时间进行部署,因此能够有效序列化和反序列化的模型是必要的。Spark MLlib提供了模型序列化功能,允许用户将模型保存到磁盘,然后在需要时加载,以实现模型的持久化和重复使用。
模型评分系统要求包括高效地应用模型到新数据的能力。这需要考虑到系统的吞吐量、延迟和资源利用。在设计模型评分架构时,应考虑如何并行化预测,如何有效地管理内存,以及如何处理流式或批处理的数据。此外,还需要确保评分系统能够处理模型更新,适应不断变化的数据和业务需求。
模型评分架构通常涉及以下几个组件:数据预处理、模型加载、预测执行和结果后处理。预处理阶段可能包括数据清洗、转换和标准化;模型加载是指从存储中检索模型;预测执行是实际应用模型进行预测;结果后处理可能涉及聚合、阈值设定或其他业务逻辑。
在生产环境中,自动化生产管道是将模型部署和维护流程化的关键。这包括模型训练、验证、部署、监控和更新的整个生命周期管理。使用Apache Spark可以构建这样的管道,通过Spark SQL进行数据处理,用MLlib训练模型,并利用Spark Streaming或Structured Streaming进行实时预测。
安全性和治理也是企业级数据解决方案的重要组成部分。Databricks Enterprise Security提供了数据访问优化、权限控制和审计日志等功能,确保敏感模型和数据的安全。
这篇文章将深入讨论如何利用Apache Spark MLlib 2.x构建和部署机器学习模型,以及在实际生产环境中所需考虑的关键技术和实践。这对于数据科学家和工程师来说,是理解和实现高效、可靠且可扩展的机器学习系统的宝贵资源。
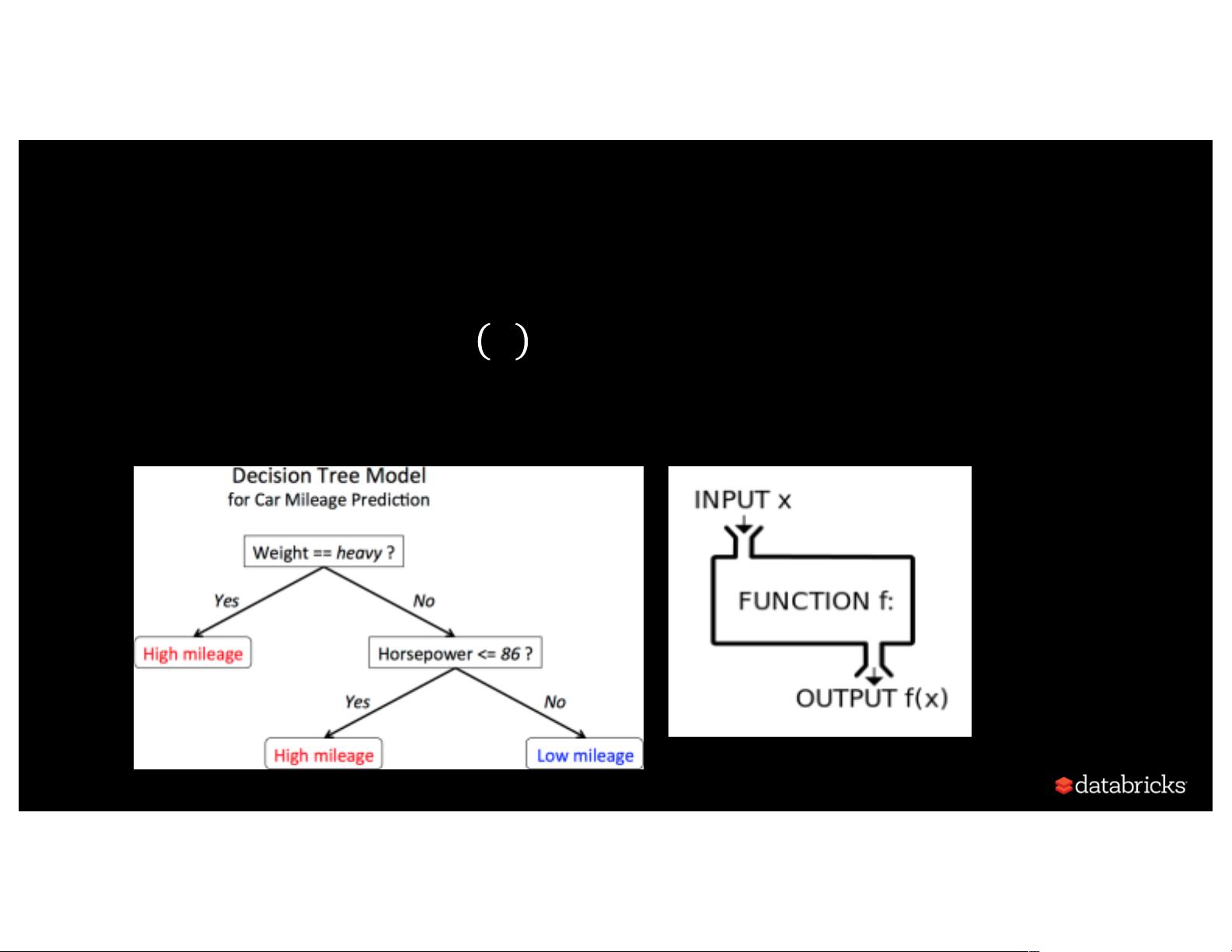
A Model is a Mathematical Function
• A model is a function: 𝑓 𝑥
• Linear regression 𝑦$ = $𝑏
0
$ + $𝑏
1
𝑥
1
$ + $𝑏
2
𝑥
2
剩余40页未读,继续阅读
179 浏览量
119 浏览量
125 浏览量
2023-06-03 上传
2023-05-19 上传
2023-05-12 上传
2023-03-31 上传
2023-07-12 上传
2023-06-07 上传

qiwihui
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 俄罗斯RTSD数据集实现交通标志实时检测
- 易语言开发的文件批量改名工具使用Ex_Dui美化界面
- 爱心援助动态网页教程:前端开发实战指南
- 复旦微电子数字电路课件4章同步时序电路详解
- Dylan Manley的编程投资组合登录页面设计介绍
- Python实现H3K4me3与H3K27ac表观遗传标记域长度分析
- 易语言开源播放器项目:简易界面与强大的音频支持
- 介绍rxtx2.2全系统环境下的Java版本使用
- ZStack-CC2530 半开源协议栈使用与安装指南
- 易语言实现的八斗平台与淘宝评论采集软件开发
- Christiano响应式网站项目设计与技术特点
- QT图形框架中QGraphicRectItem的插入与缩放技术
- 组合逻辑电路深入解析与习题教程
- Vue+ECharts实现中国地图3D展示与交互功能
- MiSTer_MAME_SCRIPTS:自动下载MAME与HBMAME脚本指南
- 前端技术精髓:构建响应式盆栽展示网站
